Apprenticeship-Inspired Elegance: Synergistic Knowledge Distillation Empowers Spiking Neural Networks for Efficient Single-Eye Emotion Recognition
作者: Yang Wang, Haiyang Mei, Qirui Bao, Ziqi Wei, Mike Zheng Shou, Haizhou Li, Bo Dong, Xin Yang
分类: cs.CV, cs.NE
发布日期: 2024-06-20
备注: Accepted by IJCAI 2024
💡 一句话要点
提出基于知识蒸馏的协同学习框架,提升SNN单眼情感识别效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感识别 脉冲神经网络 知识蒸馏 多模态学习 单眼视觉
📋 核心要点
- 现有情感识别方法依赖专用传感器,成本高且数据处理复杂,限制了应用范围。
- 利用知识蒸馏,将多模态教师网络的知识迁移到单模态SNN学生网络,提升效率。
- 实验表明,该方法在单眼情感识别任务上,精度和效率均优于现有技术水平。
📝 摘要(中文)
本文提出了一种新颖的多模态协同知识蒸馏方案,专门用于高效的单眼情感识别任务。该方法允许轻量级的单模态学生脉冲神经网络(SNN)从事件-帧多模态教师网络中提取丰富的知识。该方法的核心优势在于能够利用传统帧中丰富的、较粗的时间线索进行有效的情感识别。因此,我们的方法能够充分解释来自传统帧域的时间和空间信息,从而消除了对专用传感设备(例如,基于事件的相机)的需求。通过使用现有和我们自己编制的单眼情感识别数据集,充分证明了我们方法的有效性,在准确性和效率方面实现了优于现有最先进方法的性能。
🔬 方法详解
问题定义:现有情感识别方法通常依赖于事件相机等专用设备,这增加了硬件成本和数据处理的复杂性。此外,如何有效地利用时间信息进行情感识别仍然是一个挑战。因此,需要一种更高效、更通用的方法,能够仅使用传统相机数据实现准确的情感识别。
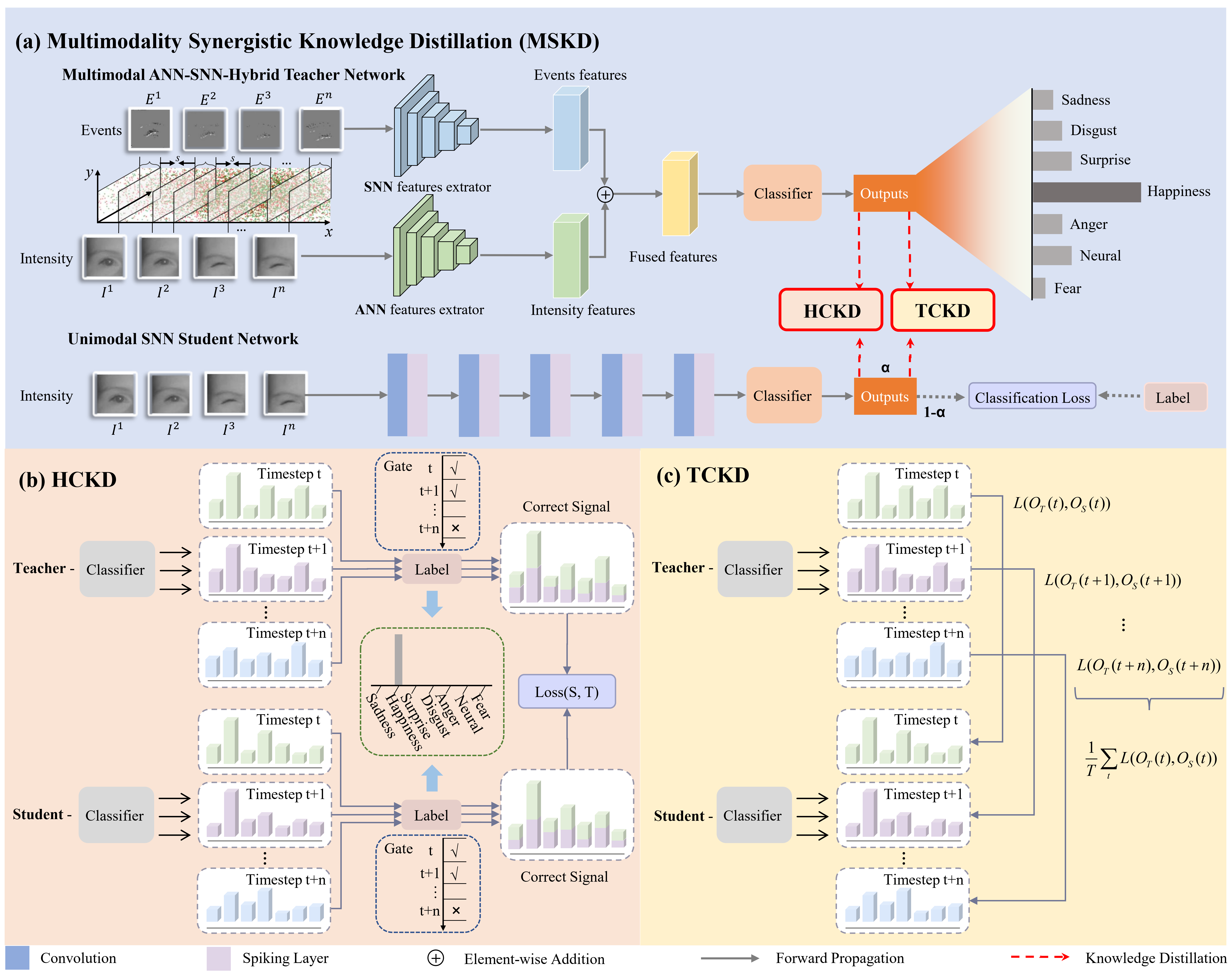
核心思路:本文的核心思路是利用知识蒸馏技术,将一个性能强大的多模态教师网络(同时利用事件数据和帧数据)的知识迁移到一个轻量级的单模态学生网络(仅使用帧数据)。这样,学生网络就可以学习到教师网络从多模态数据中提取的丰富特征,从而在仅使用帧数据的情况下也能实现高性能。
技术框架:整体框架包含一个多模态教师网络和一个单模态学生网络。教师网络接收事件数据和帧数据作为输入,学生网络仅接收帧数据作为输入。通过知识蒸馏,学生网络学习模仿教师网络的输出,从而获得教师网络从多模态数据中提取的知识。训练完成后,仅使用学生网络进行推理。
关键创新:该方法的主要创新在于利用多模态协同知识蒸馏,将事件数据和帧数据的信息融合,并迁移到单模态SNN网络。这使得SNN网络能够有效地利用时间信息,而无需依赖事件相机等专用设备。此外,使用SNN作为学生网络,可以进一步提高模型的效率。
关键设计:教师网络可以使用现有的多模态情感识别模型。学生网络采用SNN结构,以提高效率。知识蒸馏损失函数包括模仿教师网络输出的损失和正则化项,以防止过拟合。具体的网络结构、损失函数和训练参数需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在单眼情感识别任务上取得了显著的性能提升。与现有最先进的方法相比,该方法在准确性和效率方面均有优势。具体性能数据(例如,准确率提升百分比)在论文中进行了详细展示。该方法无需专用事件相机,降低了成本,更易于部署。
🎯 应用场景
该研究成果可应用于各种需要高效情感识别的场景,例如智能监控、人机交互、自动驾驶等。通过仅使用普通摄像头,即可实现准确的情感识别,降低了硬件成本和部署难度。未来,该技术有望在移动设备和嵌入式系统中得到广泛应用。
📄 摘要(原文)
We introduce a novel multimodality synergistic knowledge distillation scheme tailored for efficient single-eye motion recognition tasks. This method allows a lightweight, unimodal student spiking neural network (SNN) to extract rich knowledge from an event-frame multimodal teacher network. The core strength of this approach is its ability to utilize the ample, coarser temporal cues found in conventional frames for effective emotion recognition. Consequently, our method adeptly interprets both temporal and spatial information from the conventional frame domain, eliminating the need for specialized sensing devices, e.g., event-based camera. The effectiveness of our approach is thoroughly demonstrated using both existing and our compiled single-eye emotion recognition datasets, achieving unparalleled performance in accuracy and efficiency over existing state-of-the-art methods.