Prism: A Framework for Decoupling and Assessing the Capabilities of VLMs
作者: Yuxuan Qiao, Haodong Duan, Xinyu Fang, Junming Yang, Lin Chen, Songyang Zhang, Jiaqi Wang, Dahua Lin, Kai Chen
分类: cs.CV, cs.CL
发布日期: 2024-06-20
🔗 代码/项目: GITHUB
💡 一句话要点
Prism:解耦并评估视觉语言模型能力的框架,提升性能并降低成本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 解耦框架 感知推理 大型语言模型 多模态学习
📋 核心要点
- 现有VLM的视觉感知和推理能力耦合紧密,难以独立评估和优化,阻碍了模型性能的进一步提升。
- Prism框架将VLM解耦为感知和推理两个阶段,分别由VLM和LLM负责,从而实现对两种能力的独立评估。
- 实验表明,Prism在保证性能的同时,显著降低了模型规模和计算成本,具有很高的实用价值。
📝 摘要(中文)
本文提出Prism框架,旨在解耦和评估视觉语言模型(VLM)的感知和推理能力。现有VLM中视觉感知和推理能力相互交织,难以独立评估,不利于模型优化。Prism框架将视觉问题求解过程分为两个阶段:感知阶段利用VLM提取并以文本形式表达视觉信息;推理阶段则利用大型语言模型(LLM)基于提取的视觉信息生成答案。这种模块化设计能够系统地比较和评估不同VLM在感知和推理方面的优势。分析表明,Prism是一种经济高效的视觉语言任务解决方案。通过结合精简的、专注于感知的VLM和强大的、为推理定制的LLM,Prism在通用视觉语言任务中取得了优异的成果,同时显著降低了训练和运营成本。量化评估表明,配置了vanilla 2B LLaVA和免费GPT-3.5的Prism,在严格的多模态基准MMStar上的性能与大10倍的VLM相当。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在解决视觉问题时,感知和推理能力紧密耦合,难以区分和独立评估。这使得我们难以针对性地改进模型的感知或推理能力,也难以理解模型出错的原因。此外,大型VLM的训练和部署成本高昂,限制了其应用范围。
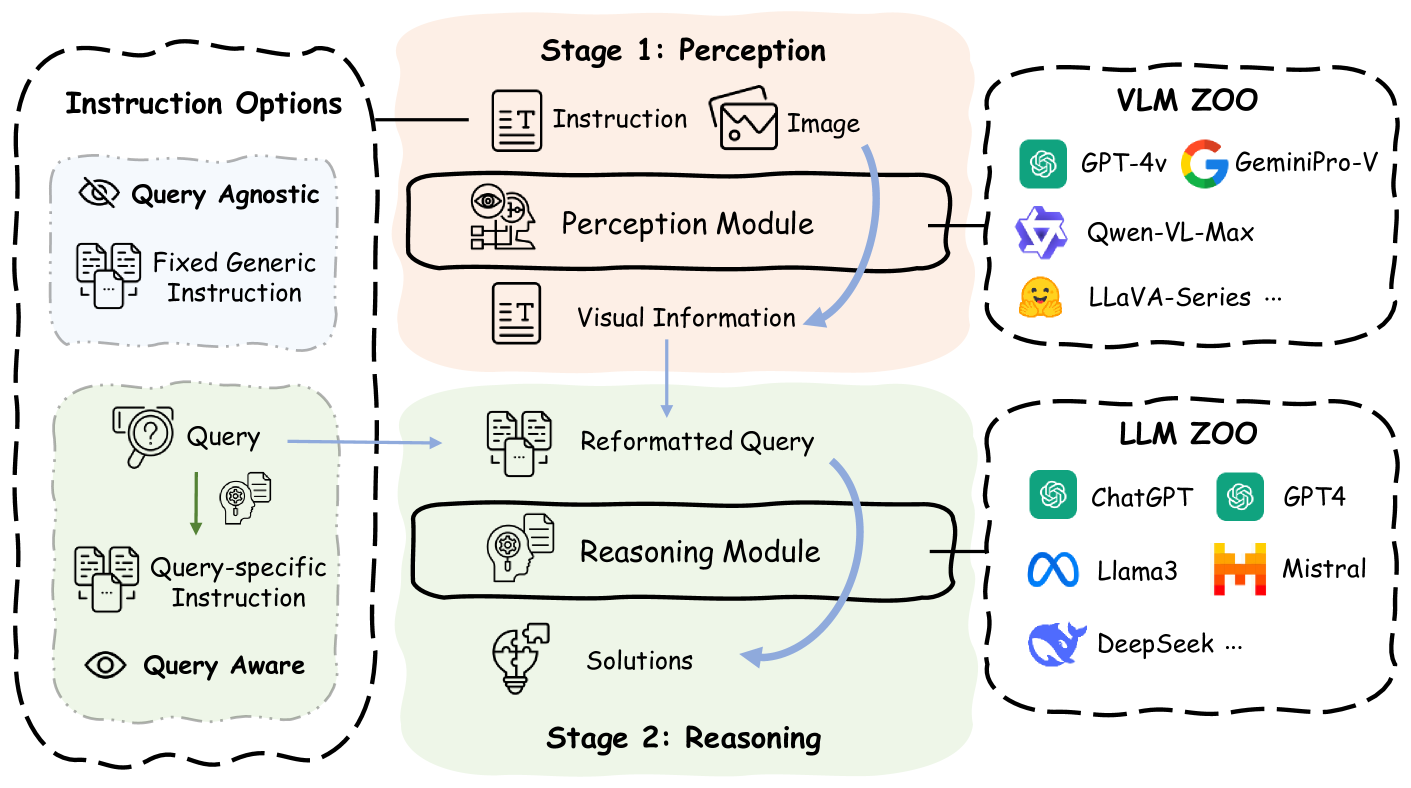
核心思路:Prism的核心思路是将VLM的视觉感知和推理过程解耦。具体来说,利用一个VLM专注于提取图像中的视觉信息,并将其转化为文本描述;然后,利用一个大型语言模型(LLM)基于这些文本描述进行推理,生成最终答案。通过这种方式,可以独立评估和优化VLM的感知能力和LLM的推理能力。
技术框架:Prism框架包含两个主要阶段:1) 感知阶段:使用一个VLM(例如LLaVA)作为视觉编码器,提取图像中的视觉特征,并生成对图像内容的文本描述。这个阶段的目标是尽可能准确地捕捉图像中的关键信息。2) 推理阶段:使用一个大型语言模型(例如GPT-3.5)作为推理引擎,接收感知阶段生成的文本描述,并根据问题进行推理,生成最终答案。这两个阶段可以独立训练和优化。
关键创新:Prism最重要的创新点在于解耦了VLM的感知和推理过程。这种解耦使得我们可以更加灵活地组合不同的VLM和LLM,从而构建出性能优异且成本较低的视觉语言系统。此外,这种解耦也使得我们可以更加容易地诊断和解决VLM中的问题。
关键设计:在感知阶段,可以使用各种现有的VLM作为视觉编码器。论文中使用了vanilla 2B LLaVA。关键在于如何设计提示词(prompt)来引导VLM生成高质量的文本描述。在推理阶段,可以使用各种现有的LLM作为推理引擎。论文中使用了免费的GPT-3.5。关键在于如何设计提示词来引导LLM进行有效的推理。损失函数方面,可以分别针对感知阶段和推理阶段进行优化,例如使用交叉熵损失函数来训练VLM,并使用强化学习来优化LLM的推理能力。
🖼️ 关键图片

📊 实验亮点
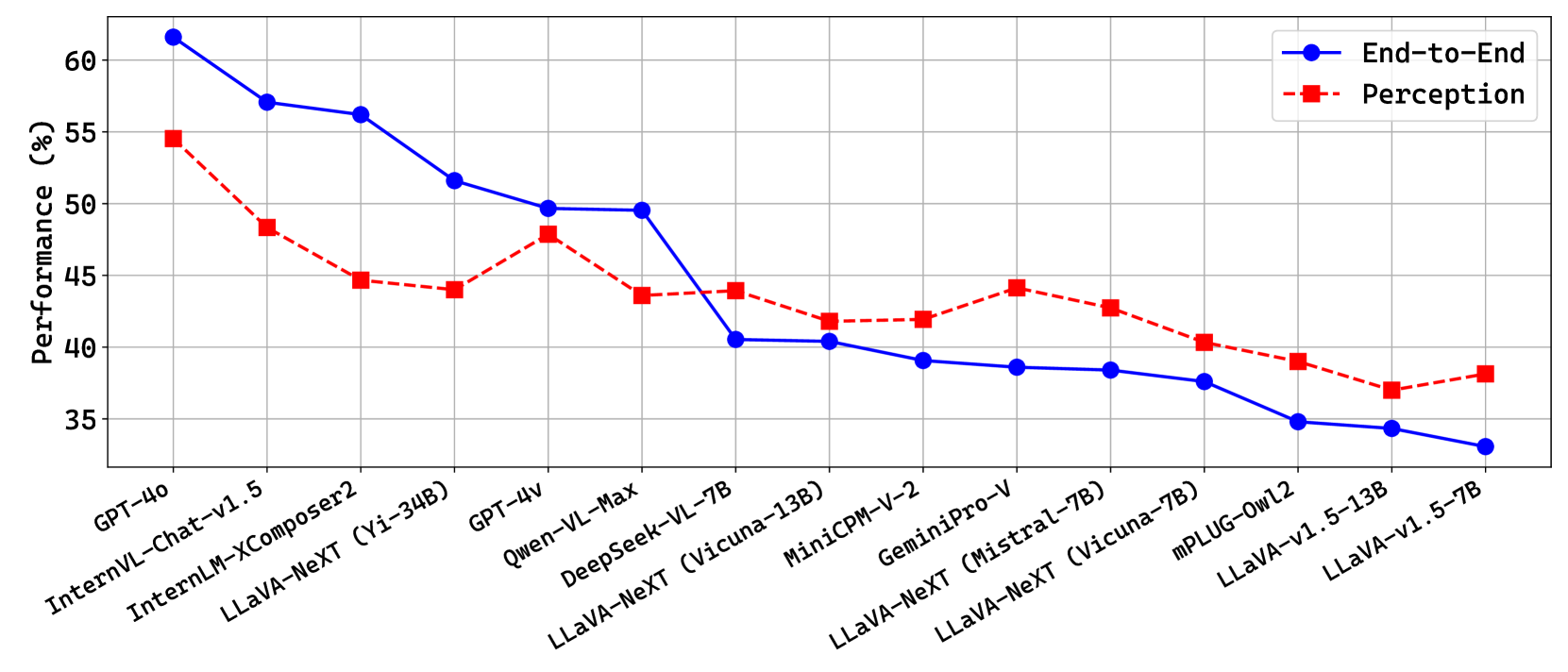
实验结果表明,使用vanilla 2B LLaVA和免费GPT-3.5配置的Prism,在MMStar基准测试中取得了与大10倍的VLM相当的性能。这表明Prism能够以更低的成本实现更高的性能。此外,Prism的解耦设计使得我们可以更加容易地诊断和解决VLM中的问题,从而进一步提升模型的性能。
🎯 应用场景
Prism框架具有广泛的应用前景,例如智能客服、自动驾驶、医疗诊断等领域。在智能客服中,Prism可以用于理解用户上传的图片,并根据图片内容回答用户的问题。在自动驾驶中,Prism可以用于识别交通标志和行人,并根据识别结果做出相应的决策。在医疗诊断中,Prism可以用于分析医学影像,并辅助医生进行诊断。Prism的模块化设计使得它可以灵活地适应不同的应用场景。
📄 摘要(原文)
Vision Language Models (VLMs) demonstrate remarkable proficiency in addressing a wide array of visual questions, which requires strong perception and reasoning faculties. Assessing these two competencies independently is crucial for model refinement, despite the inherent difficulty due to the intertwined nature of seeing and reasoning in existing VLMs. To tackle this issue, we present Prism, an innovative framework designed to disentangle the perception and reasoning processes involved in visual question solving. Prism comprises two distinct stages: a perception stage that utilizes a VLM to extract and articulate visual information in textual form, and a reasoning stage that formulates responses based on the extracted visual information using a Large Language Model (LLM). This modular design enables the systematic comparison and assessment of both proprietary and open-source VLM for their perception and reasoning strengths. Our analytical framework provides several valuable insights, underscoring Prism's potential as a cost-effective solution for vision-language tasks. By combining a streamlined VLM focused on perception with a powerful LLM tailored for reasoning, Prism achieves superior results in general vision-language tasks while substantially cutting down on training and operational expenses. Quantitative evaluations show that Prism, when configured with a vanilla 2B LLaVA and freely accessible GPT-3.5, delivers performance on par with VLMs $10 \times$ larger on the rigorous multimodal benchmark MMStar. The project is released at: https://github.com/SparksJoe/Prism.