CityNav: A Large-Scale Dataset for Real-World Aerial Navigation
作者: Jungdae Lee, Taiki Miyanishi, Shuhei Kurita, Koya Sakamoto, Daichi Azuma, Yutaka Matsuo, Nakamasa Inoue
分类: cs.CV, cs.AI
发布日期: 2024-06-20 (更新: 2025-08-02)
备注: ICCV2025. The first two authors are equally contributed. Project page: https://water-cookie.github.io/city-nav-proj/
💡 一句话要点
CityNav:用于真实世界空中导航的大规模数据集
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 空中导航 真实世界数据集 地理语义地图 无人机 机器人
📋 核心要点
- 现有空中视觉-语言导航数据集规模有限,且难以整合视觉和地理信息,阻碍了真实城市环境下的导航研究。
- CityNav数据集通过提供大规模的真实世界空中导航数据,并结合地理语义地图,为解决上述问题提供了基础。
- 实验表明,利用CityNav数据集训练的智能体,结合地理语义地图,导航性能得到显著提升,验证了数据集的有效性。
📝 摘要(中文)
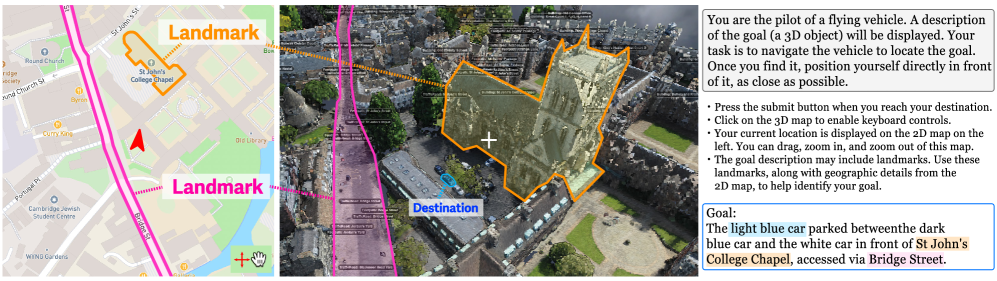
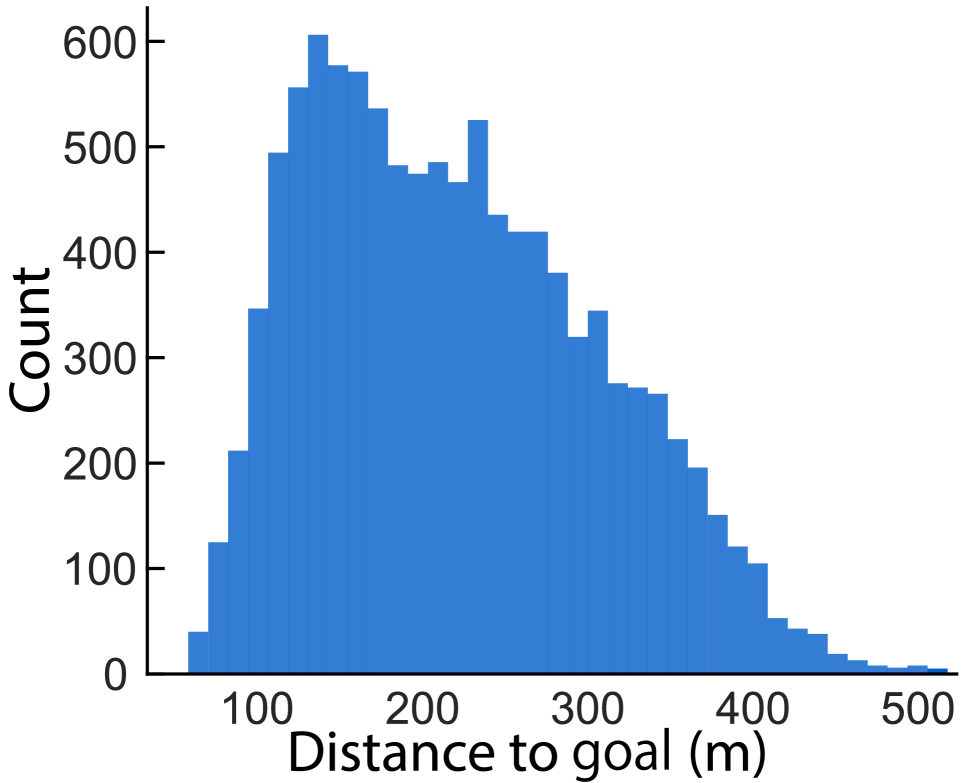
视觉-语言导航(VLN)旨在开发能够在真实环境中导航的智能体。尽管最近的跨模态训练方法显著提高了室内和室外场景中的导航性能,但由于数据集有限以及视觉和地理信息难以整合,真实城市上空的空中导航仍未得到充分探索。为了填补这一空白,我们推出了CityNav,这是第一个用于空中VLN的大规模真实世界数据集。我们的数据集包含32,637条人工演示轨迹,每条轨迹都配有自然语言描述,覆盖了剑桥和伯明翰两个真实城市的4.65平方公里。与由合成场景组成的现有数据集(如AerialVLN)相比,我们的数据集提出了独特的挑战,因为智能体必须解释真实世界地标与导航目的地之间的空间关系,这使得CityNav成为推进空中VLN的重要基准。此外,作为解决这一挑战的初步步骤,我们提供了一种创建地理语义地图的方法,该地图可用作导航期间的辅助模态输入。在我们的实验中,我们比较了三种具有代表性的空中VLN智能体(Seq2seq、CMA和AerialVLN模型)的性能,并证明语义地图表示显著提高了它们的导航性能。
🔬 方法详解
问题定义:论文旨在解决真实城市环境中,空中视觉-语言导航(VLN)任务缺乏大规模真实数据集的问题。现有方法在合成数据上训练,难以泛化到真实场景,且难以有效整合视觉和地理信息,导致导航性能受限。
核心思路:论文的核心思路是构建一个大规模的真实世界空中导航数据集CityNav,该数据集包含大量人工演示轨迹和对应的自然语言描述,覆盖真实城市区域。此外,论文还提出了一种生成地理语义地图的方法,作为辅助信息,帮助智能体理解环境和规划路径。
技术框架:CityNav数据集的构建流程包括:1) 在真实城市(剑桥和伯明翰)采集空中图像和地理数据;2) 招募人员进行导航演示,记录轨迹和自然语言描述;3) 对数据进行清洗和标注,构建最终的数据集。同时,论文提供了一种基于地理数据的语义地图生成方法,该方法将地理信息转换为智能体可以理解的语义表示。在实验中,论文使用Seq2seq、CMA和AerialVLN等模型进行评估,并将语义地图作为辅助输入。
关键创新:CityNav是第一个大规模的真实世界空中VLN数据集,其数据来源于真实城市环境,更具挑战性和实用性。此外,论文提出的地理语义地图生成方法,为智能体提供了更丰富的环境信息,有助于提高导航性能。
关键设计:地理语义地图的生成方法是关键设计之一。具体来说,该方法利用地理数据(如建筑物、道路等)进行语义分割,并将分割结果转换为智能体可以理解的语义表示。在实验中,语义地图被用作模型的额外输入,通过注意力机制等方式与视觉信息进行融合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在CityNav数据集上训练的空中VLN智能体,结合地理语义地图,导航性能得到显著提升。具体来说,与不使用语义地图的基线模型相比,使用语义地图的模型在导航成功率和路径长度方面均有明显改善,验证了CityNav数据集和地理语义地图的有效性。
🎯 应用场景
该研究成果可应用于无人机导航、城市巡检、物流配送等领域。CityNav数据集的发布将促进空中视觉-语言导航算法的发展,提高无人机在复杂城市环境中的自主导航能力,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Vision-and-language navigation (VLN) aims to develop agents capable of navigating in realistic environments. While recent cross-modal training approaches have significantly improved navigation performance in both indoor and outdoor scenarios, aerial navigation over real-world cities remains underexplored primarily due to limited datasets and the difficulty of integrating visual and geographic information. To fill this gap, we introduce CityNav, the first large-scale real-world dataset for aerial VLN. Our dataset consists of 32,637 human demonstration trajectories, each paired with a natural language description, covering 4.65 km$^2$ across two real cities: Cambridge and Birmingham. In contrast to existing datasets composed of synthetic scenes such as AerialVLN, our dataset presents a unique challenge because agents must interpret spatial relationships between real-world landmarks and the navigation destination, making CityNav an essential benchmark for advancing aerial VLN. Furthermore, as an initial step toward addressing this challenge, we provide a methodology of creating geographic semantic maps that can be used as an auxiliary modality input during navigation. In our experiments, we compare performance of three representative aerial VLN agents (Seq2seq, CMA and AerialVLN models) and demonstrate that the semantic map representation significantly improves their navigation performance.