Towards Event-oriented Long Video Understanding
作者: Yifan Du, Kun Zhou, Yuqi Huo, Yifan Li, Wayne Xin Zhao, Haoyu Lu, Zijia Zhao, Bingning Wang, Weipeng Chen, Ji-Rong Wen
分类: cs.CV, cs.CL, cs.MM
发布日期: 2024-06-20
备注: Work on progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出Event-Bench基准测试和VIM方法,提升MLLM在事件导向长视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 事件导向 多模态大语言模型 基准测试 数据增强
📋 核心要点
- 现有视频理解数据集缺乏丰富的事件信息,导致模型容易利用捷径,无法真正理解长视频。
- 论文提出Event-Bench基准测试,包含事件相关的任务,用于全面评估模型对长视频事件的理解能力。
- 论文提出视频指令融合(VIM)方法,通过合成事件密集的视频指令来提升MLLM的性能。
📝 摘要(中文)
随着视频多模态大语言模型(MLLMs)的快速发展,涌现出大量评估其视频理解能力的基准测试。然而,由于视频中缺乏丰富的事件,这些数据集可能存在捷径偏差,即答案可以从少数帧推断出来,而无需观看整个视频。为了解决这个问题,我们引入了Event-Bench,这是一个事件导向的长视频理解基准,建立在现有数据集和人工标注的基础上。Event-Bench包括六个事件相关的任务和2,190个测试实例,以全面评估视频事件理解能力。此外,我们提出了一种经济高效的方法——视频指令融合(VIM),它使用融合的、事件密集的视频指令来增强视频MLLM,从而解决了人工标注的事件密集型数据稀缺的问题。大量实验表明,性能最佳的模型GPT-4o实现了53.33的总体准确率,显著优于最佳开源模型41.42%。通过利用有效的指令合成方法和自适应模型架构,VIM在Event-Bench上超越了最先进的开源模型和GPT-4V。
🔬 方法详解
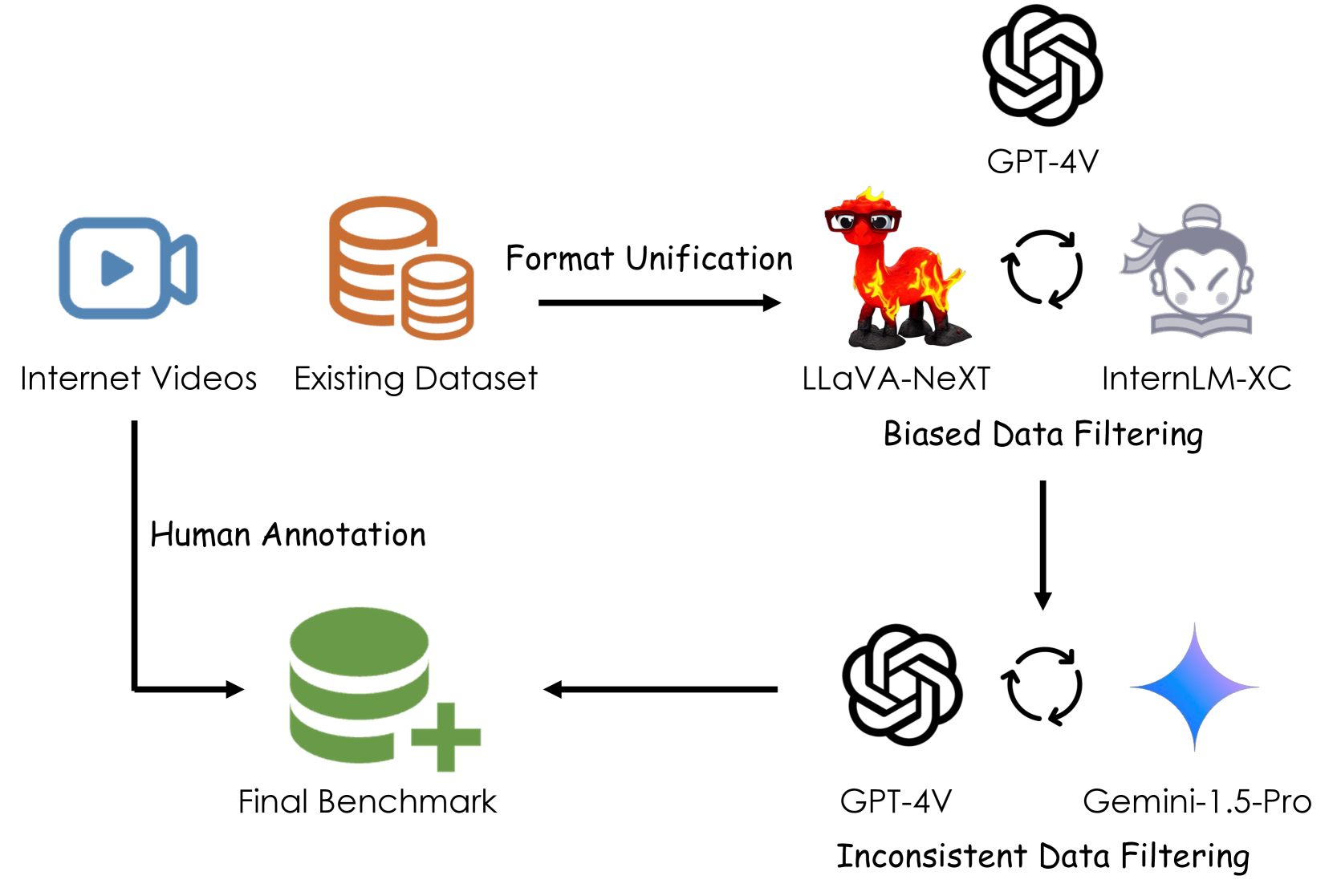
问题定义:现有视频理解数据集,特别是用于评估多模态大语言模型(MLLMs)的数据集,往往缺乏足够丰富的事件信息。这导致模型可以通过识别视频中的少量关键帧来推断答案,而无需真正理解视频中发生的事件和事件之间的关系。这种“捷径学习”使得模型在这些数据集上表现良好,但泛化能力较差,无法处理复杂的、事件驱动的长视频理解任务。因此,需要一个更具挑战性的基准测试来评估模型对长视频事件的理解能力。
核心思路:论文的核心思路是构建一个事件导向的长视频理解基准测试(Event-Bench),并提出一种数据增强方法(VIM)来提升模型在该基准上的性能。Event-Bench通过人工标注和现有数据集的结合,提供了包含丰富事件信息的长视频测试用例。VIM方法则通过合成事件密集的视频指令,来增强模型的训练数据,从而提高模型对事件的理解能力。这样设计的目的是为了迫使模型真正理解视频中的事件,而不是仅仅依赖于捷径。
技术框架:Event-Bench基准测试包含六个事件相关的任务,涵盖了视频事件理解的多个方面。VIM方法主要包含两个阶段:首先,利用指令合成技术生成事件密集的视频指令;然后,将这些合成的指令与原始的视频指令进行融合,用于训练视频MLLM。模型架构方面,论文可能采用了自适应的模型架构,以更好地适应事件密集型数据的特点(具体架构细节未知)。
关键创新:Event-Bench基准测试的创新在于其事件导向的设计,能够更全面地评估模型对长视频事件的理解能力。VIM方法的创新在于其经济高效的指令合成技术,能够有效地解决事件密集型数据稀缺的问题。通过合成指令,可以显著增加训练数据的多样性,从而提高模型的泛化能力。
关键设计:关于Event-Bench,关键设计在于六个事件相关任务的具体设计,以及如何从现有数据集中提取和标注事件信息(具体细节未知)。关于VIM,关键设计在于指令合成的具体方法,如何保证合成指令的质量和多样性,以及如何将合成指令与原始指令进行有效融合(具体细节未知)。论文可能还涉及了模型架构的自适应设计,以更好地适应事件密集型数据的特点(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GPT-4o在Event-Bench上取得了53.33%的总体准确率,显著优于最佳开源模型41.42%。VIM方法在Event-Bench上超越了最先进的开源模型和GPT-4V,证明了其有效性。这些结果表明,Event-Bench能够有效评估模型对长视频事件的理解能力,而VIM方法能够有效提升模型的性能。
🎯 应用场景
该研究成果可应用于智能监控、视频内容分析、智能交通等领域。例如,在智能监控中,可以利用该技术理解监控视频中的异常事件,及时发出警报。在视频内容分析中,可以自动识别视频中的关键事件,提高视频检索和推荐的效率。在智能交通中,可以分析交通视频中的交通事故,辅助事故责任认定。
📄 摘要(原文)
With the rapid development of video Multimodal Large Language Models (MLLMs), numerous benchmarks have been proposed to assess their video understanding capability. However, due to the lack of rich events in the videos, these datasets may suffer from the short-cut bias that the answers can be deduced from a few frames, without the need to watch the entire video. To address this issue, we introduce Event-Bench, an event-oriented long video understanding benchmark built on existing datasets and human annotations. Event-Bench includes six event-related tasks and 2,190 test instances to comprehensively evaluate video event understanding ability. Additionally, we propose Video Instruction Merging~(VIM), a cost-effective method that enhances video MLLMs using merged, event-intensive video instructions, addressing the scarcity of human-annotated, event-intensive data. Extensive experiments show that the best-performing model, GPT-4o, achieves an overall accuracy of 53.33, significantly outperforming the best open-source model by 41.42%. Leveraging an effective instruction synthesis method and an adaptive model architecture, VIM surpasses both state-of-the-art open-source models and GPT-4V on the Event-Bench. All code, data, and models are publicly available at https://github.com/RUCAIBox/Event-Bench.