From Descriptive Richness to Bias: Unveiling the Dark Side of Generative Image Caption Enrichment
作者: Yusuke Hirota, Ryo Hachiuma, Chao-Han Huck Yang, Yuta Nakashima
分类: cs.CV
发布日期: 2024-06-20
💡 一句话要点
揭示生成式图像描述增强的负面影响:偏见与幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述生成 生成式模型 性别偏见 幻觉 视觉-语言模型
📋 核心要点
- 现有图像描述增强方法侧重于提升描述的丰富性,但忽略了潜在的负面影响,如偏见和幻觉。
- 该论文通过对比标准描述和生成式增强描述,揭示了后者在性别偏见和幻觉方面的问题。
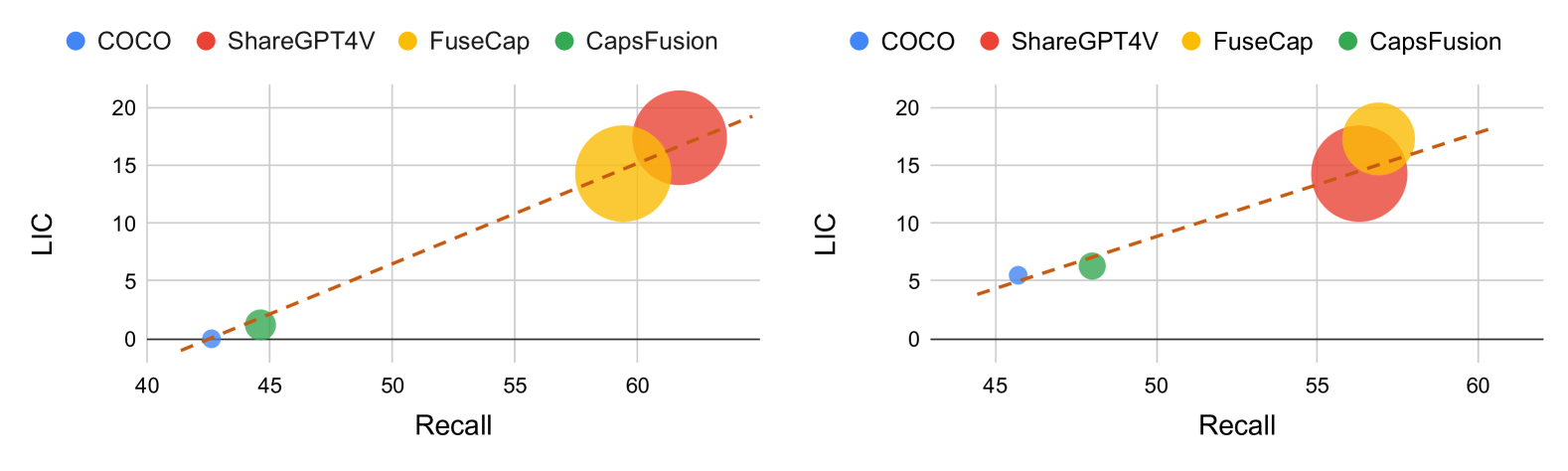
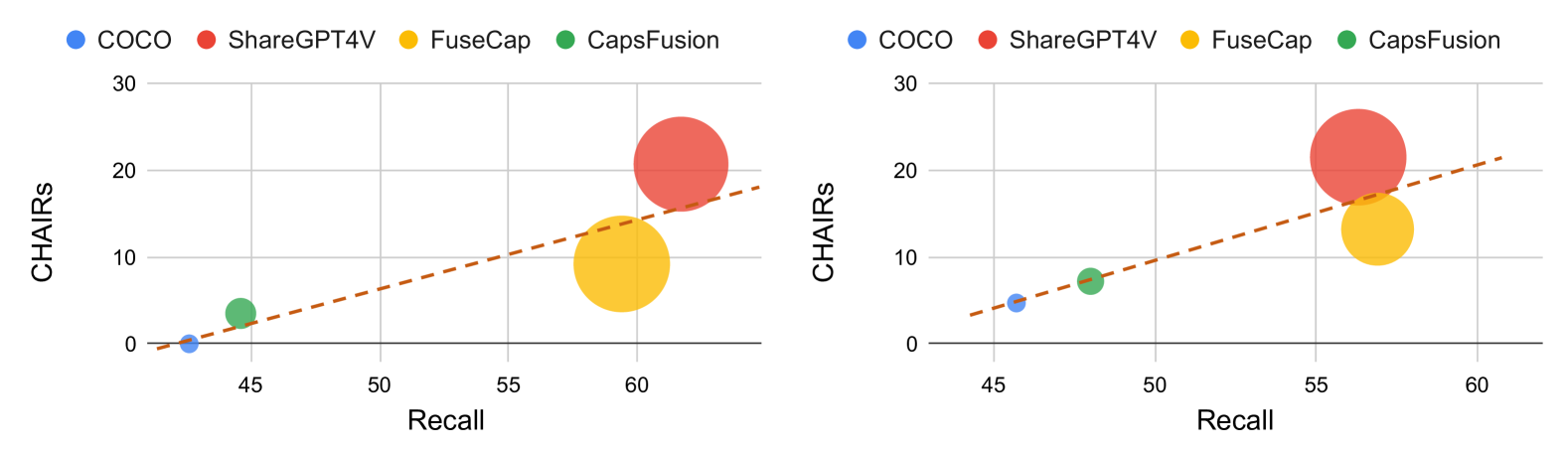
- 实验表明,使用增强描述训练的模型会显著放大性别偏见和幻觉,提示需要谨慎对待描述增强。
📝 摘要(中文)
大型语言模型(LLMs)提升了视觉-语言模型生成图像描述的能力。这种生成式图像描述增强(GCE)方法使得文本描述更具描述性,从而改善了与视觉上下文的对齐。然而,尽管许多研究关注GCE的优势,但是否存在负面影响?本文从“性别偏见”和“幻觉”的角度比较了标准格式的描述和最新的GCE过程,结果表明,增强后的描述会遭受更严重的性别偏见和幻觉。此外,使用这些增强描述训练的模型平均放大了30.9%的性别偏见,并增加了59.5%的幻觉。这项研究对当前追求描述性更强的图像描述的趋势提出了警告。
🔬 方法详解
问题定义:论文旨在研究生成式图像描述增强(GCE)技术在提升图像描述丰富度的同时,是否会引入或加剧性别偏见和幻觉问题。现有方法主要关注GCE带来的好处,而忽略了其潜在的负面影响,导致模型在实际应用中可能产生不公平或不准确的预测。
核心思路:论文的核心思路是通过对比分析标准图像描述和GCE生成的增强描述,量化评估GCE对性别偏见和幻觉的影响。通过分析描述文本中的性别相关词汇和与图像内容不符的信息,来衡量偏见和幻觉的程度。
技术框架:论文的技术框架主要包括以下几个步骤:1) 收集标准图像描述数据集;2) 使用GCE方法生成增强的图像描述;3) 设计指标来量化评估性别偏见和幻觉;4) 使用标准描述和增强描述分别训练视觉-语言模型;5) 评估模型在偏见和幻觉方面的表现,并进行对比分析。
关键创新:论文的关键创新在于首次系统性地研究了GCE技术在图像描述领域可能带来的负面影响,并提出了量化评估偏见和幻觉的指标。通过实验证明,GCE虽然可以提升描述的丰富度,但同时也可能加剧性别偏见和幻觉问题,为未来的研究提供了重要的参考。
关键设计:论文的关键设计包括:1) 采用合适的GCE方法,例如基于大型语言模型的文本生成技术;2) 设计合理的指标来量化评估性别偏见,例如统计描述文本中与性别相关的词汇频率;3) 设计合理的指标来量化评估幻觉,例如比较描述文本与图像内容的一致性;4) 使用标准数据集和评估指标,确保实验结果的可重复性和可比性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用GCE增强的图像描述训练的模型,性别偏见平均增加了30.9%,幻觉增加了59.5%。这些数据明确地揭示了GCE在提升描述丰富度的同时,会显著加剧模型的偏见和幻觉问题。该研究结果对视觉-语言模型的发展具有重要的警示意义。
🎯 应用场景
该研究成果可应用于图像描述生成、视觉问答、图像检索等领域,有助于开发更公平、更准确的视觉-语言模型。通过避免使用带有偏见或幻觉的图像描述进行模型训练,可以提升模型的可靠性和安全性,减少潜在的社会负面影响。未来的研究可以探索如何设计更有效的GCE方法,在提升描述丰富度的同时,降低偏见和幻觉的风险。
📄 摘要(原文)
Large language models (LLMs) have enhanced the capacity of vision-language models to caption visual text. This generative approach to image caption enrichment further makes textual captions more descriptive, improving alignment with the visual context. However, while many studies focus on benefits of generative caption enrichment (GCE), are there any negative side effects? We compare standard-format captions and recent GCE processes from the perspectives of "gender bias" and "hallucination", showing that enriched captions suffer from increased gender bias and hallucination. Furthermore, models trained on these enriched captions amplify gender bias by an average of 30.9% and increase hallucination by 59.5%. This study serves as a caution against the trend of making captions more descriptive.