HumorDB: Can AI understand graphical humor?
作者: Vedaant Jain, Felipe dos Santos Alves Feitosa, Gabriel Kreiman
分类: cs.CV, cs.AI
发布日期: 2024-06-19 (更新: 2025-10-17)
备注: 10 main figures, 4 additional appendix figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出 HumorDB 数据集,用于评估和提升AI对视觉幽默的理解能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视觉幽默理解 数据集构建 图像理解 视觉-语言模型 注意力机制
📋 核心要点
- 现有图像理解方法在复杂场景理解方面存在不足,尤其是在需要认知知识交互的视觉幽默理解上。
- HumorDB 数据集通过提供多样化的幽默图像和对比样本,促进AI模型学习视觉幽默的细微差别和上下文信息。
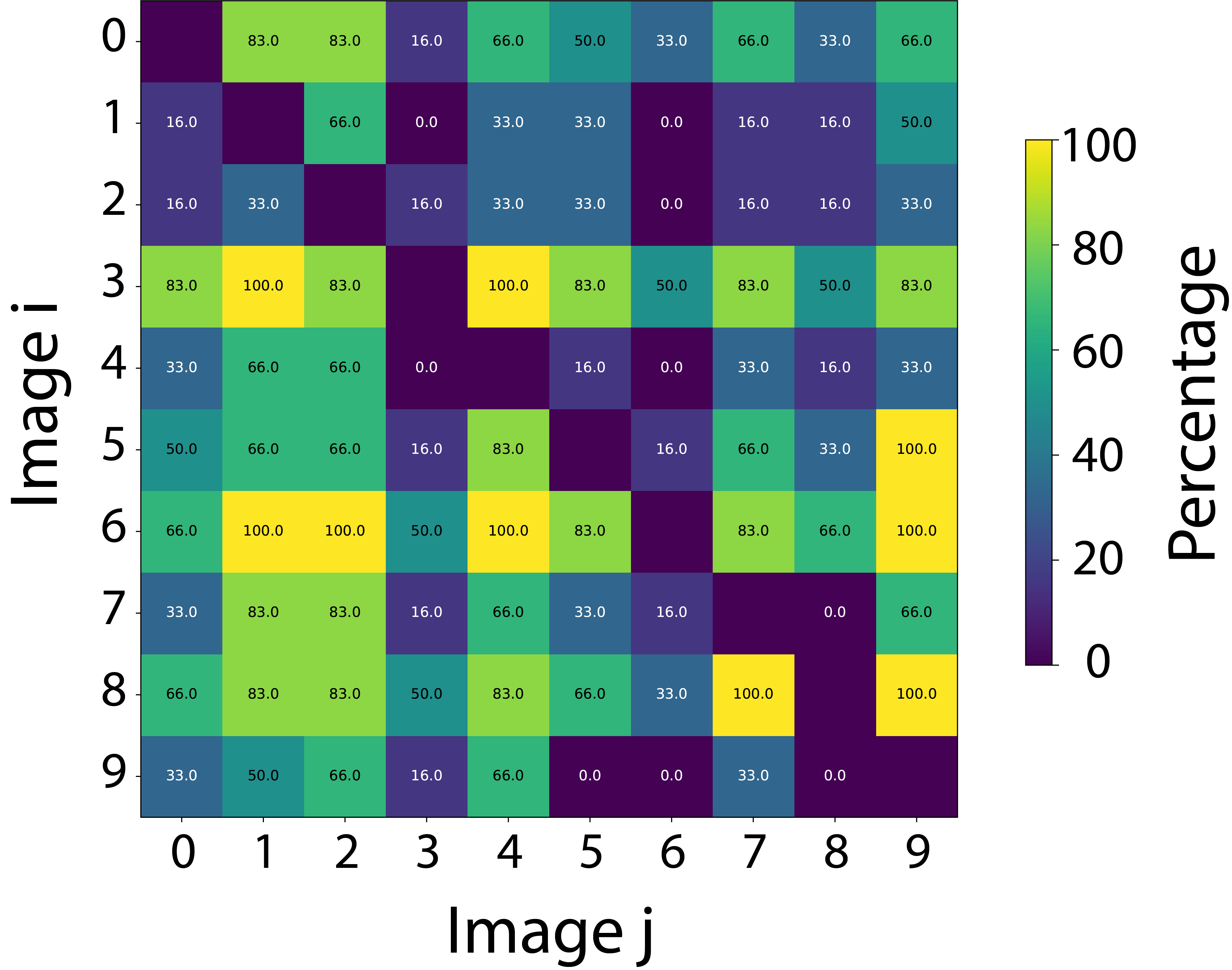
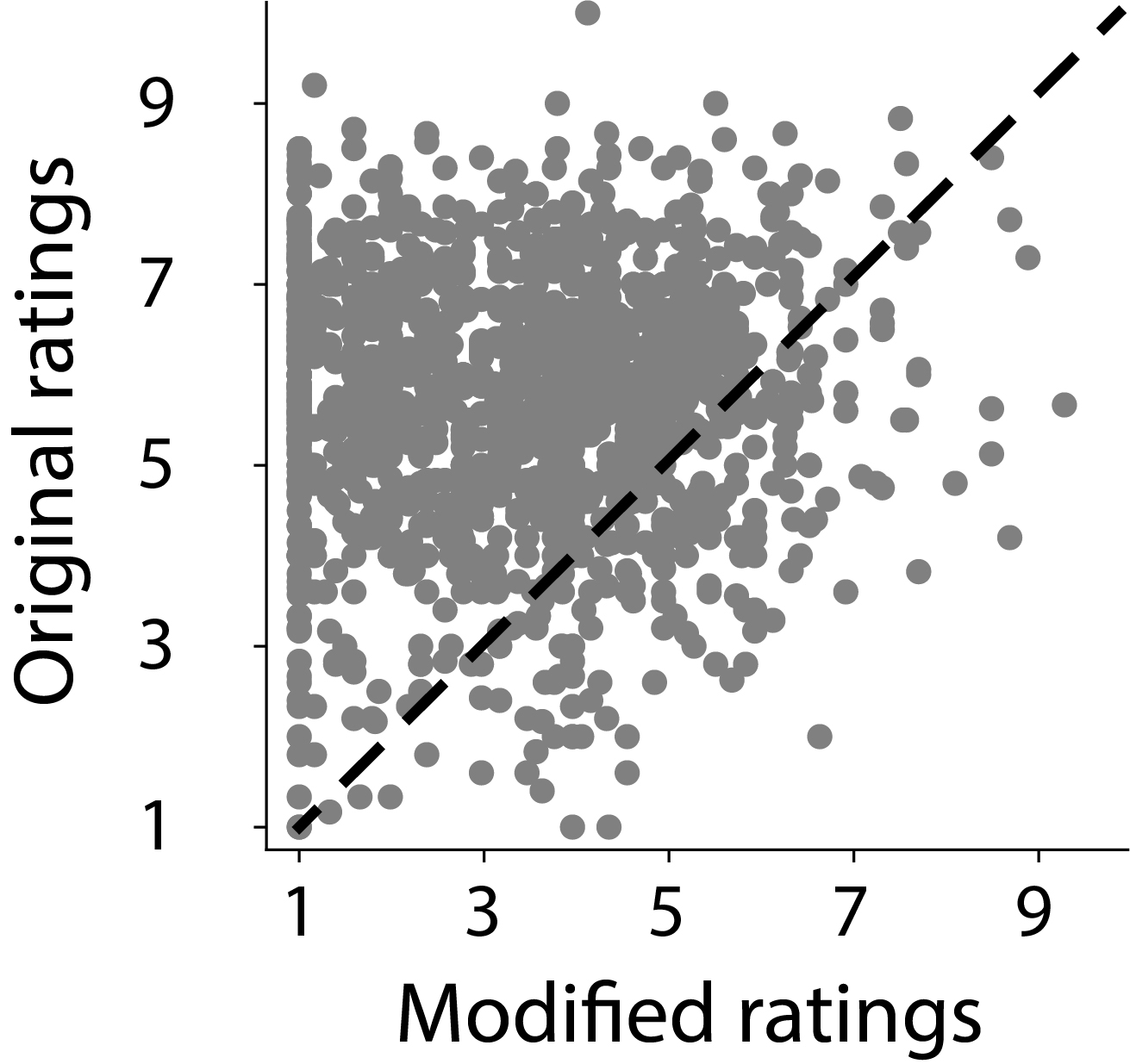
- 实验表明,现有AI模型在视觉幽默理解方面与人类存在差距,尤其是在处理抽象素描和细微幽默线索时。
📝 摘要(中文)
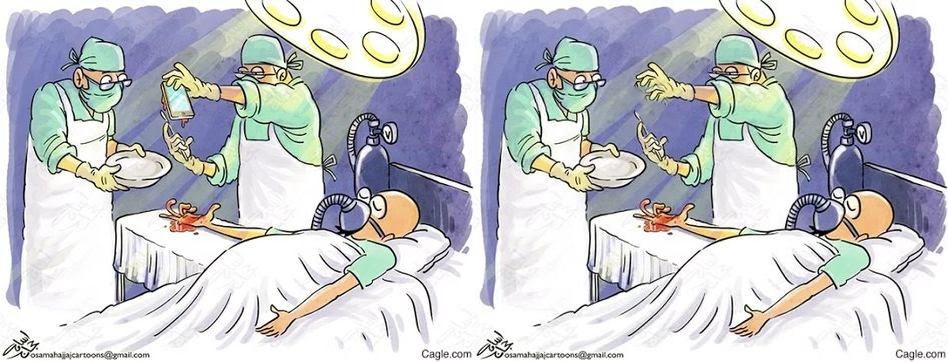
本文提出了 HumorDB,一个新颖、可控且精心策划的数据集,旨在评估和提升AI系统对视觉幽默的理解。该数据集包含照片、卡通、素描和AI生成内容等多种图像,包括最小对比对,其中细微的编辑区分了幽默和非幽默版本。我们在三个任务上评估了人类、最先进的视觉模型和大型视觉-语言模型:二元幽默分类、趣味性评分预测和成对幽默比较。结果表明,当前AI系统与人类水平的幽默理解之间存在差距。虽然预训练的视觉-语言模型比仅视觉模型表现更好,但它们仍然难以处理抽象草图和细微的幽默线索。注意力图分析表明,即使模型正确分类了幽默图像,它们也常常无法关注使图像有趣的精确区域。初步的机制可解释性研究和模型解释评估为不同架构如何处理幽默提供了初步见解。我们的结果确定了有希望的趋势和当前的局限性,表明有效理解视觉幽默需要复杂的架构,能够检测细微的上下文特征并弥合视觉感知和抽象推理之间的差距。
🔬 方法详解
问题定义:论文旨在解决AI对视觉幽默的理解问题。现有方法在处理需要复杂推理和上下文理解的视觉场景时表现不佳,无法有效识别和理解幽默的本质。现有模型难以捕捉图像中细微的幽默线索,并且缺乏将视觉信息与抽象知识联系起来的能力。
核心思路:论文的核心思路是通过构建一个高质量的视觉幽默数据集,为AI模型提供学习和评估视觉幽默理解能力的平台。该数据集包含多种类型的图像,包括幽默和非幽默的对比样本,旨在帮助模型学习区分幽默的关键特征。通过在该数据集上训练和评估模型,可以促进模型更好地理解视觉幽默。
技术框架:该研究主要围绕HumorDB数据集的构建和使用展开。数据集包含照片、卡通、素描和AI生成图像。研究者在数据集上进行了三个任务的评估:二元幽默分类、趣味性评分预测和成对幽默比较。评估对象包括人类、视觉模型和视觉-语言模型。研究还包括对模型注意力图的分析和初步的机制可解释性研究。
关键创新:该研究的关键创新在于HumorDB数据集的构建。该数据集是专门为视觉幽默理解而设计的,包含多种类型的图像和对比样本,可以有效评估和提升AI模型对视觉幽默的理解能力。此外,研究还对现有模型在视觉幽默理解方面的局限性进行了深入分析,并提出了未来研究方向。
关键设计:HumorDB数据集包含多种类型的图像,包括照片、卡通、素描和AI生成图像。数据集中的图像被分为幽默和非幽默两类,并包含最小对比对,其中细微的编辑区分了幽默和非幽默版本。研究者使用了多种视觉模型和视觉-语言模型进行评估,并使用了注意力图分析和机制可解释性研究等方法来分析模型的行为。
🖼️ 关键图片
📊 实验亮点
实验结果表明,预训练的视觉-语言模型在视觉幽默理解方面优于仅视觉模型,但仍与人类水平存在差距。模型在处理抽象素描和细微幽默线索时表现不佳。注意力图分析显示,即使模型正确分类了幽默图像,也常常无法关注使图像有趣的精确区域。这些结果揭示了现有模型在视觉幽默理解方面的局限性,并为未来的研究提供了方向。
🎯 应用场景
该研究成果可应用于提升AI在图像理解、情感分析和人机交互等领域的性能。例如,可以用于开发能够理解和生成幽默内容的AI系统,或者用于改善AI在处理复杂视觉场景时的推理能力。此外,该数据集和研究方法也可以为其他视觉理解任务提供借鉴。
📄 摘要(原文)
Despite significant advancements in image segmentation and object detection, understanding complex scenes remains a significant challenge. Here, we focus on graphical humor as a paradigmatic example of image interpretation that requires elucidating the interaction of different scene elements in the context of prior cognitive knowledge. This paper introduces \textbf{HumorDB}, a novel, controlled, and carefully curated dataset designed to evaluate and advance visual humor understanding by AI systems. The dataset comprises diverse images spanning photos, cartoons, sketches, and AI-generated content, including minimally contrastive pairs where subtle edits differentiate between humorous and non-humorous versions. We evaluate humans, state-of-the-art vision models, and large vision-language models on three tasks: binary humor classification, funniness rating prediction, and pairwise humor comparison. The results reveal a gap between current AI systems and human-level humor understanding. While pretrained vision-language models perform better than vision-only models, they still struggle with abstract sketches and subtle humor cues. Analysis of attention maps shows that even when models correctly classify humorous images, they often fail to focus on the precise regions that make the image funny. Preliminary mechanistic interpretability studies and evaluation of model explanations provide initial insights into how different architectures process humor. Our results identify promising trends and current limitations, suggesting that an effective understanding of visual humor requires sophisticated architectures capable of detecting subtle contextual features and bridging the gap between visual perception and abstract reasoning. All the code and data are available here: \href{https://github.com/kreimanlab/HumorDB}{https://github.com/kreimanlab/HumorDB}