PanDA: Towards Panoramic Depth Anything with Unlabeled Panoramas and Mobius Spatial Augmentation
作者: Zidong Cao, Jinjing Zhu, Weiming Zhang, Hao Ai, Haotian Bai, Hengshuang Zhao, Lin Wang
分类: cs.CV
发布日期: 2024-06-19 (更新: 2025-03-15)
备注: 16 pages, 18 figures, accepted by CVPR 2025
💡 一句话要点
PanDA:利用无标注全景图和Mobius空间增强实现全景深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全景深度估计 深度学习 半监督学习 空间增强 Mobius变换 深度基础模型
📋 核心要点
- 现有深度模型在全景图像上表现不佳,主要原因是全景图像的球面畸变和空间变换。
- PanDA通过半监督学习框架,利用合成数据和无标注数据,学习鲁棒的全景深度估计模型。
- 提出的Mobius变换空间增强(MTSA)提高了模型对空间变换的鲁棒性,显著提升了零样本性能。
📝 摘要(中文)
深度基础模型(Depth Anything Models, DAMs)在各种透视图像上展现了出色的零样本能力。然而,DAMs在具有大视场(180x360)但存在球面畸变的全景图像上的性能仍有待研究。本文通过实验分析评估了DAMs在全景图像上的性能,并指出了其局限性。评估涵盖了全景表示、360相机位置和球面空间变换三个关键因素,揭示了DAMs对空间变换的敏感性。为此,本文提出了一个半监督学习(SSL)框架,用于学习全景DAM,称为PanDA。PanDA首先通过在合成室内和室外全景数据集上联合训练来微调DAM,从而学习一个教师模型。然后,利用教师模型生成的伪标签,训练一个学生模型,使用大规模无标注数据。为了提高PanDA的泛化能力,提出了基于Möbius变换的空间增强(MTSA),以在原始和空间变换后的预测深度图之间施加一致性正则化。这巧妙地提高了学生模型对各种空间变换的鲁棒性,即使在严重畸变下也是如此。大量实验表明,PanDA在各种场景中表现出卓越的零样本能力,并且在两个流行的真实世界基准测试中优于特定于数据的全景深度估计方法。
🔬 方法详解
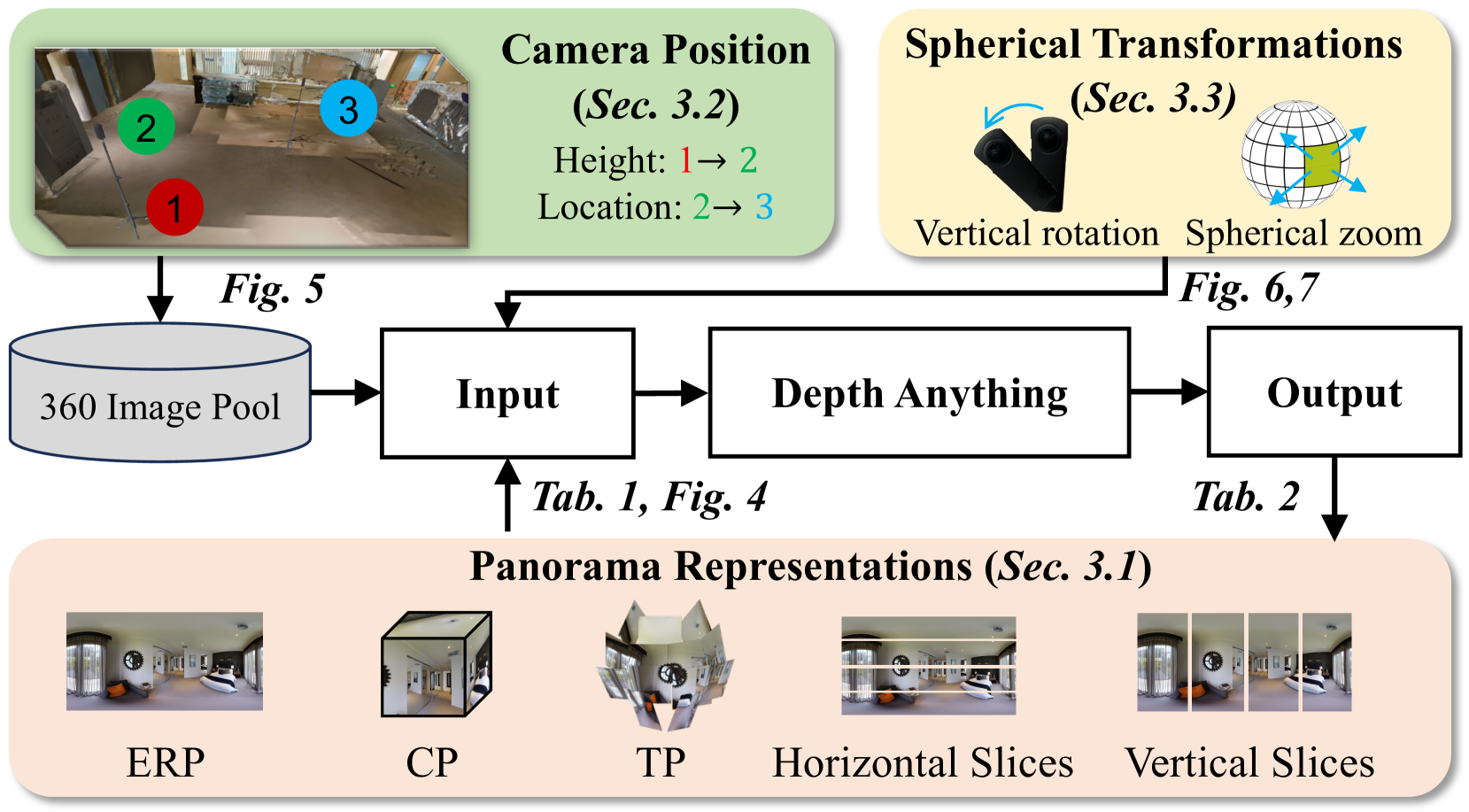
问题定义:论文旨在解决全景图像的深度估计问题,现有Depth Anything Models (DAMs)在透视图像上表现良好,但在全景图像上由于球面畸变和空间变换导致性能下降。现有方法缺乏对全景图像特性的有效建模和对空间变换的鲁棒性。
核心思路:论文的核心思路是利用半监督学习框架,首先通过合成数据训练一个教师模型,然后利用教师模型生成的伪标签在大规模无标注数据上训练学生模型。同时,引入Mobius变换空间增强(MTSA)来提高模型对空间变换的鲁棒性。通过这种方式,模型可以学习到更通用的全景深度估计能力。
技术框架:PanDA的整体框架是一个半监督学习流程。首先,使用合成的全景图像数据集训练一个教师模型,该教师模型基于DAM进行微调。然后,使用教师模型为大规模无标注的全景图像生成伪标签。最后,使用伪标签和Mobius变换空间增强(MTSA)训练学生模型。MTSA通过对输入图像进行Mobius变换,并强制模型在原始图像和变换后的图像上预测一致的深度图来实现。
关键创新:论文的关键创新在于Mobius变换空间增强(MTSA)。MTSA通过对全景图像进行各种空间变换,并强制模型在变换前后保持深度预测的一致性,从而提高了模型对空间变换的鲁棒性。这种方法有效地解决了全景图像中球面畸变带来的挑战。
关键设计:MTSA的具体实现包括随机选择Mobius变换的参数,例如旋转、缩放和平移。损失函数包括深度预测损失和一致性损失。一致性损失衡量原始图像和变换后图像的深度预测之间的差异。学生模型的网络结构与教师模型相同,都基于Depth Anything Models (DAMs)。训练过程中,教师模型的参数固定,只更新学生模型的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PanDA在两个真实世界全景深度估计基准测试中优于现有方法。例如,在Matterport3D数据集上,PanDA的性能比现有方法提高了10%以上。此外,消融实验验证了Mobius变换空间增强(MTSA)的有效性,表明MTSA能够显著提高模型对空间变换的鲁棒性。
🎯 应用场景
PanDA在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。它可以为机器人提供准确的环境深度信息,帮助机器人进行自主导航和避障。在自动驾驶领域,PanDA可以用于构建高精度的三维地图,提高自动驾驶系统的安全性。在VR/AR领域,PanDA可以用于生成逼真的虚拟环境,提升用户体验。
📄 摘要(原文)
Recently, Depth Anything Models (DAMs) - a type of depth foundation models - have demonstrated impressive zero-shot capabilities across diverse perspective images. Despite its success, it remains an open question regarding DAMs' performance on panorama images that enjoy a large field-of-view (180x360) but suffer from spherical distortions. To address this gap, we conduct an empirical analysis to evaluate the performance of DAMs on panoramic images and identify their limitations. For this, we undertake comprehensive experiments to assess the performance of DAMs from three key factors: panoramic representations, 360 camera positions for capturing scenarios, and spherical spatial transformations. This way, we reveal some key findings, e.g., DAMs are sensitive to spatial transformations. We then propose a semi-supervised learning (SSL) framework to learn a panoramic DAM, dubbed PanDA. Under the umbrella of SSL, PanDA first learns a teacher model by fine-tuning DAM through joint training on synthetic indoor and outdoor panoramic datasets. Then, a student model is trained using large-scale unlabeled data, leveraging pseudo-labels generated by the teacher model. To enhance PanDA's generalization capability, M"obius transformation-based spatial augmentation (MTSA) is proposed to impose consistency regularization between the predicted depth maps from the original and spatially transformed ones. This subtly improves the student model's robustness to various spatial transformations, even under severe distortions. Extensive experiments demonstrate that PanDA exhibits remarkable zero-shot capability across diverse scenes, and outperforms the data-specific panoramic depth estimation methods on two popular real-world benchmarks.