MC-MKE: A Fine-Grained Multimodal Knowledge Editing Benchmark Emphasizing Modality Consistency
作者: Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Baizhou Huang, Xu Zhang, Xinyu Hu, Xiaojun Wan
分类: cs.CV, cs.CL
发布日期: 2024-06-19 (更新: 2024-10-30)
💡 一句话要点
MC-MKE:提出一个细粒度的多模态知识编辑基准,强调模态一致性,用于评估和纠正MLLM中的错误。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 知识编辑 大型语言模型 模态一致性 基准测试
📋 核心要点
- 现有多模态知识编辑基准未能充分分析和解决MLLM中因多模态知识复杂性导致的误读和误识别错误。
- 论文将多模态知识分解为视觉和文本组件,针对不同错误类型设计不同的编辑格式,实现独立纠正。
- 提出的MC-MKE基准测试揭示了现有方法在模态一致性方面的不足,为后续研究提供了方向。
📝 摘要(中文)
多模态大型语言模型(MLLM)容易出现非事实或过时的知识问题,由于多模态知识的复杂性,这些问题可能表现为误读和误识别错误。以往的基准测试没有系统地分析编辑方法在纠正这两种错误类型方面的性能。为了更好地表示和纠正这些错误,我们将多模态知识分解为视觉和文本组件。不同的错误类型对应于不同的编辑格式,这些格式编辑多模态知识的不同部分。我们提出了MC-MKE,这是一个细粒度的多模态知识编辑基准,强调模态一致性。我们的基准通过编辑相应的知识组件,促进对误读和误识别错误的独立纠正。我们在MC-MKE上评估了四种多模态知识编辑方法,揭示了它们的局限性,特别是在模态一致性方面。我们的工作强调了多模态知识编辑带来的挑战,并推动了在该领域开发有效技术的进一步研究。
🔬 方法详解
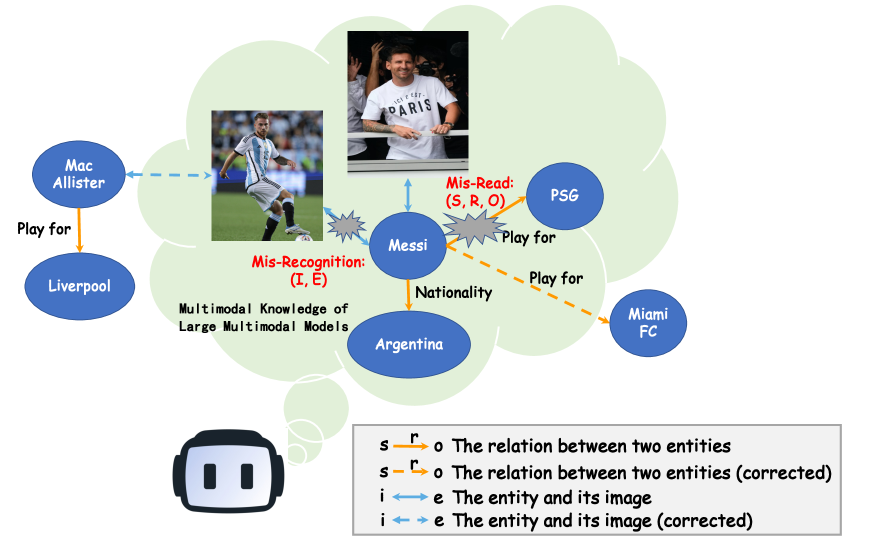
问题定义:现有的多模态知识编辑方法在纠正多模态大型语言模型(MLLM)中的知识错误时,未能充分区分和处理由于视觉信息误读和文本信息误识别导致的错误。这些方法缺乏细粒度的控制,难以保证编辑后视觉和文本信息的一致性,导致模型产生不协调的输出。因此,如何设计一个能够有效评估和提升多模态知识编辑方法在模态一致性方面的性能的基准测试是一个关键问题。
核心思路:论文的核心思路是将多模态知识分解为视觉和文本两个独立的组件,并针对不同类型的错误(误读和误识别)设计不同的编辑策略。通过这种方式,可以更精确地定位和修改错误的知识部分,同时确保编辑后的视觉和文本信息保持一致。这种细粒度的编辑方法能够更好地反映多模态知识的本质,并为开发更有效的多模态知识编辑技术提供指导。
技术框架:MC-MKE基准测试包含以下几个主要组成部分:1) 多模态知识库:包含一系列视觉和文本信息对,用于表示需要编辑的多模态知识。2) 错误类型划分:将错误分为误读(视觉信息错误)和误识别(文本信息错误)两种类型。3) 编辑格式定义:针对每种错误类型,定义相应的编辑格式,例如,对于误读错误,需要修改视觉信息;对于误识别错误,需要修改文本信息。4) 评估指标:设计用于评估编辑方法在纠正错误和保持模态一致性方面的性能指标。5) 基线方法:选择现有的多模态知识编辑方法作为基线,并在MC-MKE上进行评估。
关键创新:该论文的关键创新在于提出了一个细粒度的多模态知识编辑基准MC-MKE,该基准强调模态一致性,并能够独立评估和纠正MLLM中的误读和误识别错误。与以往的基准测试相比,MC-MKE更加关注多模态知识的本质,并为开发更有效的多模态知识编辑技术提供了更精确的评估工具。
关键设计:MC-MKE基准测试的关键设计包括:1) 细粒度的错误类型划分,区分误读和误识别错误。2) 针对不同错误类型设计的独立编辑格式,允许对视觉和文本信息进行独立修改。3) 用于评估模态一致性的指标,例如,可以计算编辑后视觉和文本信息之间的语义相似度。4) 选择具有代表性的多模态知识编辑方法作为基线,并在MC-MKE上进行评估和比较。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的多模态知识编辑方法在MC-MKE基准测试上表现出一定的局限性,尤其是在保持模态一致性方面。例如,某些方法在纠正视觉信息错误时,可能会导致文本信息出现不一致的情况。这些结果强调了多模态知识编辑的挑战性,并为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于提升多模态大型语言模型在图像描述、视觉问答、跨模态检索等领域的性能。通过知识编辑,可以纠正模型中的错误知识,提高其生成内容的准确性和可靠性。此外,该基准测试可以促进多模态知识编辑技术的发展,为构建更智能、更可靠的多模态人工智能系统奠定基础。
📄 摘要(原文)
Multimodal large language models (MLLMs) are prone to non-factual or outdated knowledge issues, which can manifest as misreading and misrecognition errors due to the complexity of multimodal knowledge. Previous benchmarks have not systematically analyzed the performance of editing methods in correcting these two error types. To better represent and correct these errors, we decompose multimodal knowledge into its visual and textual components. Different error types correspond to different editing formats, which edit distinct parts of the multimodal knowledge. We present MC-MKE, a fine-grained Multimodal Knowledge Editing benchmark emphasizing Modality Consistency. Our benchmark facilitates independent correction of misreading and misrecognition errors by editing the corresponding knowledge component. We evaluate four multimodal knowledge editing methods on MC-MKE, revealing their limitations, particularly in terms of modality consistency. Our work highlights the challenges posed by multimodal knowledge editing and motivates further research in developing effective techniques for this task.