Block-level Text Spotting with LLMs
作者: Ganesh Bannur, Bharadwaj Amrutur
分类: cs.CV
发布日期: 2024-06-19
备注: 19 pages, 7 figures
💡 一句话要点
提出BTS-LLM,利用大语言模型进行图像块级文本定位与识别。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 块级文本定位 大型语言模型 文本识别 图像理解 语义理解
📋 核心要点
- 现有文本定位技术主要集中于字符、单词或行级别,缺乏对包含丰富上下文信息的块级文本的有效提取方法。
- BTS-LLM利用LLM的语义理解能力,对行文本进行分组和排序,从而实现更准确的块级文本定位和识别。
- 该方法在文本识别出现错误时,还能利用LLM的纠错能力进行文本重建,提升整体性能。
📝 摘要(中文)
本文提出了一种新颖的块级文本定位方法BTS-LLM,旨在从图像中提取文本块。相较于字符、单词或行级别的文本提取,块级文本包含更多上下文信息,有利于翻译等下游应用。BTS-LLM包含三个部分:首先,检测和识别行级别的文本;其次,将行聚合成块;最后,利用大型语言模型(LLM)确定块内行的最佳顺序。该方法旨在利用LLM强大的语义知识,实现精确的块级文本定位。此外,即使文本识别过程中出现错误,LLM也能纠正语义相关的错误,并重建文本。
🔬 方法详解
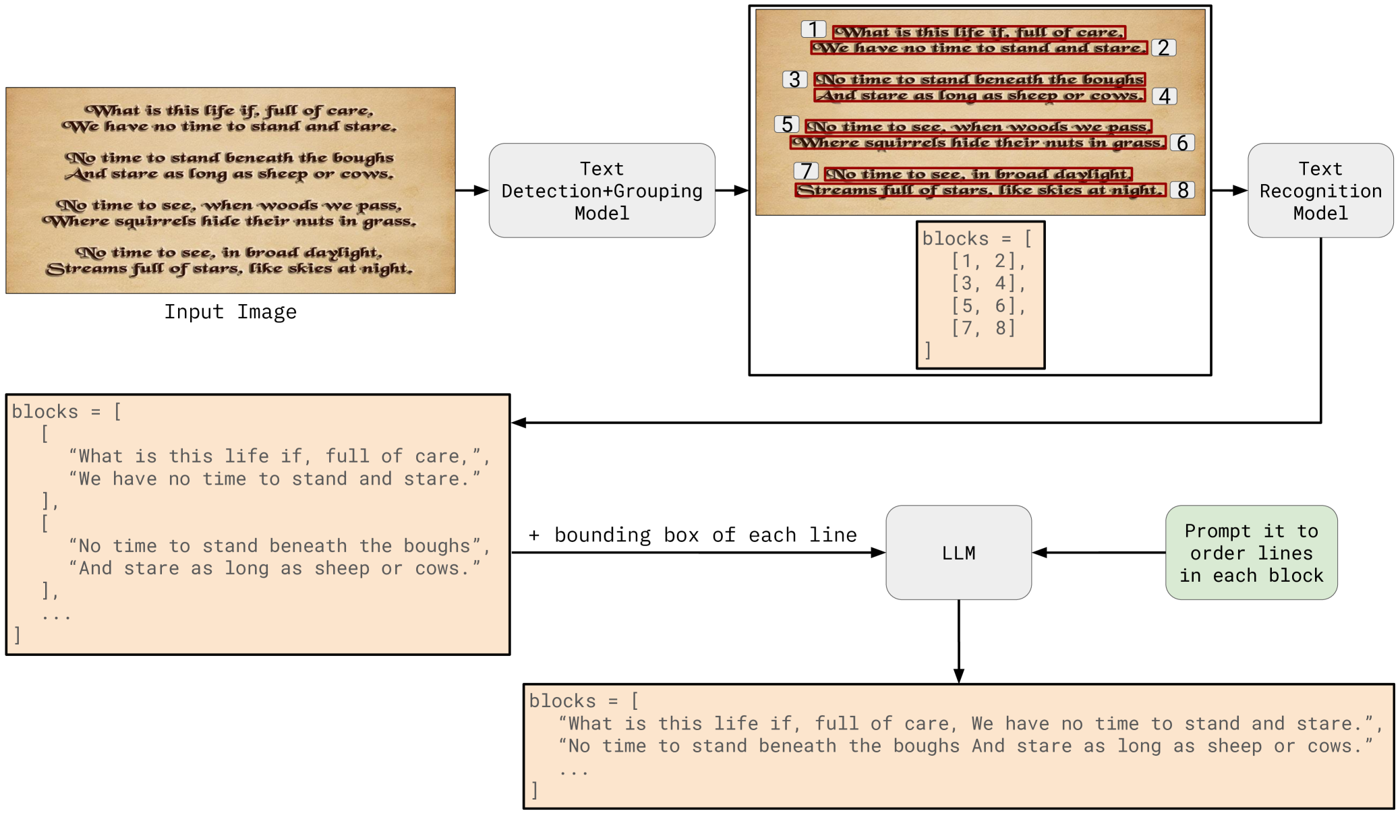
问题定义:论文旨在解决图像中块级文本定位的问题。现有方法主要关注字符、单词或行级别的文本提取,忽略了块级文本所包含的丰富上下文信息,这限制了下游应用(如翻译)的性能。现有方法缺乏有效利用上下文信息进行文本块划分和排序的能力。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解能力,对识别出的行文本进行分组和排序,从而实现更准确的块级文本定位。LLM能够理解文本的语义关系,从而判断哪些行应该被组合在一起,以及它们之间的正确顺序。
技术框架:BTS-LLM包含三个主要阶段:1) 行级别文本检测与识别:使用现有的文本检测和识别技术,从图像中提取行级别的文本信息。2) 行分组:将检测到的行文本分组到不同的文本块中。分组策略可能基于空间 proximity、文本相似度等特征。3) 块内行排序:利用LLM对每个文本块内的行进行排序,以确定最佳的阅读顺序。LLM会评估不同行顺序的语义合理性,并选择最合理的顺序。
关键创新:该方法最关键的创新在于将LLM引入到块级文本定位任务中。传统方法主要依赖于视觉特征或简单的规则进行文本块划分和排序,而BTS-LLM则利用LLM的语义理解能力,从而能够更准确地识别和组织文本块。此外,LLM还能够纠正文本识别过程中的错误,进一步提升整体性能。
关键设计:论文中关于LLM的使用方式是关键设计。具体来说,LLM可能被用于评估不同行顺序的困惑度(perplexity)或语义相似度,并选择困惑度最低或语义相似度最高的顺序。此外,LLM还可以被用于生成文本,从而纠正识别错误。具体的LLM选择、训练方式以及与现有文本识别模块的集成方式是需要进一步研究的关键技术细节。损失函数的设计可能包括文本识别损失、行分组损失以及LLM的语言模型损失。
🖼️ 关键图片


📊 实验亮点
论文重点在于提出了一种新的块级文本定位框架,并强调了LLM在提升文本定位准确性和纠错能力方面的作用。摘要中并未提供具体的实验数据或与其他基线的对比结果,因此无法量化评估性能提升的具体幅度。未来的研究可以关注在不同数据集上进行实验验证,并与其他先进方法进行比较。
🎯 应用场景
该研究成果可应用于文档图像分析、机器翻译、信息提取等领域。例如,在机器翻译中,块级文本定位可以提供更丰富的上下文信息,从而提高翻译的准确性和流畅性。此外,该技术还可用于自动文档摘要、知识图谱构建等任务,具有广泛的应用前景。
📄 摘要(原文)
Text spotting has seen tremendous progress in recent years yielding performant techniques which can extract text at the character, word or line level. However, extracting blocks of text from images (block-level text spotting) is relatively unexplored. Blocks contain more context than individual lines, words or characters and so block-level text spotting would enhance downstream applications, such as translation, which benefit from added context. We propose a novel method, BTS-LLM (Block-level Text Spotting with LLMs), to identify text at the block level. BTS-LLM has three parts: 1) detecting and recognizing text at the line level, 2) grouping lines into blocks and 3) finding the best order of lines within a block using a large language model (LLM). We aim to exploit the strong semantic knowledge in LLMs for accurate block-level text spotting. Consequently if the text spotted is semantically meaningful but has been corrupted during text recognition, the LLM is also able to rectify mistakes in the text and produce a reconstruction of it.