Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
作者: Paul Henderson, Melonie de Almeida, Daniela Ivanova, Titas Anciukevičius
分类: cs.CV, cs.LG
发布日期: 2024-06-18
💡 一句话要点
提出基于潜在扩散模型的3D高斯场景快速生成方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景生成 潜在扩散模型 高斯Splat 多视角学习 自编码器 快速生成 无监督学习
📋 核心要点
- 现有3D场景生成方法计算成本高昂,难以快速生成高质量、多样化的结果。
- 该论文提出一种基于潜在扩散模型的3D场景生成框架,通过在压缩的潜在空间中进行扩散过程,加速生成过程。
- 实验表明,该方法在生成速度和质量上均优于现有方法,且无需深度信息或物体掩码。
📝 摘要(中文)
本文提出了一种基于潜在扩散模型的3D场景生成方法,该模型仅使用2D图像数据进行训练。首先,设计了一个自编码器,将多视角图像映射到3D高斯splat,并同时构建这些splat的压缩潜在表示。然后,在潜在空间上训练一个多视角扩散模型,以学习高效的生成模型。该流程不需要对象掩码或深度信息,适用于具有任意相机位置的复杂场景。在MVImgNet和RealEstate10K两个大规模真实世界复杂场景数据集上进行了实验。结果表明,该方法能够从头开始、从单个输入视图或从稀疏输入视图生成3D场景,耗时仅需0.2秒。它产生多样且高质量的结果,同时比非潜在扩散模型和早期基于NeRF的生成模型快一个数量级。
🔬 方法详解
问题定义:现有的3D场景生成方法,如基于NeRF的方法,通常计算量大,生成速度慢,难以应用于需要快速生成3D场景的场景。此外,一些方法需要深度信息或物体掩码等额外信息,限制了其适用范围。
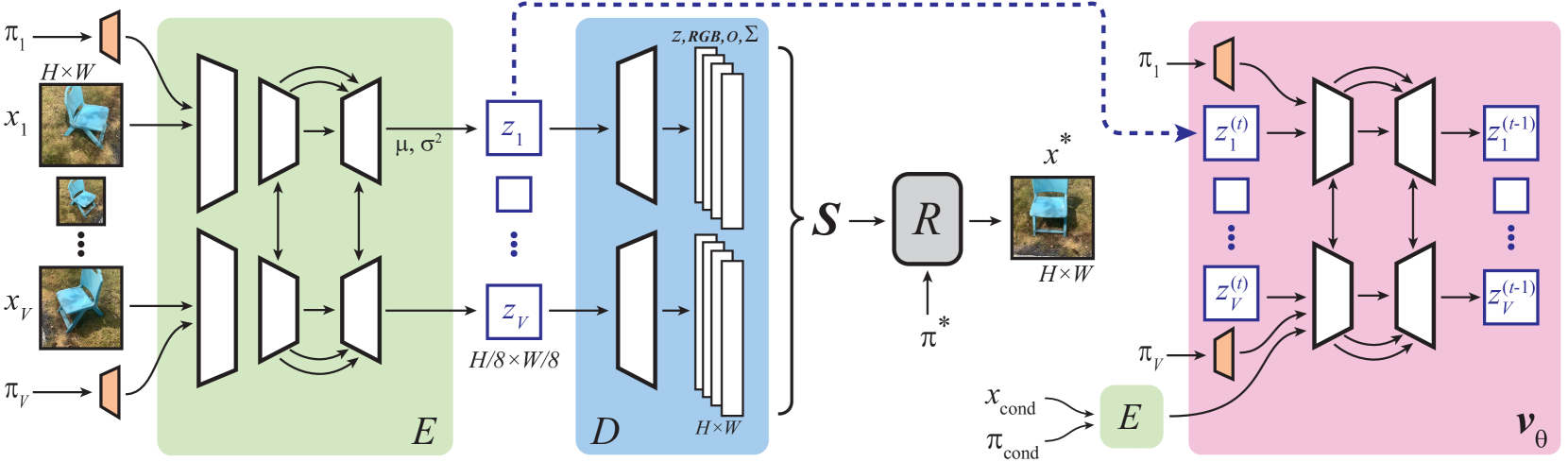
核心思路:该论文的核心思路是将3D场景生成问题转化为在压缩的潜在空间中进行扩散的过程。通过自编码器将多视角图像编码为3D高斯splat的潜在表示,然后在该潜在空间上训练扩散模型。这样可以在低维空间进行扩散过程,从而显著提高生成速度。
技术框架:该方法包含两个主要阶段:1) 自编码器训练阶段:使用多视角图像训练一个自编码器,将图像编码为3D高斯splat的潜在表示。2) 扩散模型训练阶段:在自编码器学习到的潜在空间上训练一个多视角扩散模型,用于生成新的3D场景的潜在表示。生成过程包括从扩散模型中采样潜在表示,然后通过自编码器的解码器将其转换为3D高斯splat。
关键创新:该方法最重要的创新点在于将扩散模型应用于3D场景的潜在空间,从而实现了快速且高质量的3D场景生成。与直接在像素空间或体素空间进行扩散的方法相比,该方法大大降低了计算复杂度。此外,该方法不需要深度信息或物体掩码,使其更具通用性。
关键设计:自编码器采用卷积神经网络结构,用于提取多视角图像的特征并将其编码为潜在表示。扩散模型采用U-Net结构,用于学习潜在空间中的数据分布。损失函数包括重建损失和扩散损失,用于优化自编码器和扩散模型。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
该方法在MVImgNet和RealEstate10K数据集上进行了评估,实验结果表明,该方法能够在0.2秒内生成3D场景,比非潜在扩散模型和基于NeRF的生成模型快一个数量级。同时,生成的3D场景具有较高的质量和多样性,能够从单个或稀疏的输入视图中推断出完整的3D结构。
🎯 应用场景
该研究成果可应用于游戏开发、虚拟现实、增强现实、机器人导航等领域。例如,可以快速生成游戏场景、创建虚拟环境、辅助机器人进行场景理解和导航。该方法有望推动3D内容创作的自动化和智能化,降低3D内容生成的成本和门槛。
📄 摘要(原文)
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models