Mitigating Object Hallucinations in Large Vision-Language Models with Assembly of Global and Local Attention
作者: Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, Shijian Lu
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-06-18 (更新: 2025-03-14)
备注: Accepted by CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出AGLA,通过组装全局和局部注意力缓解大型视觉语言模型中的对象幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 对象幻觉 注意力机制 全局特征 局部特征 图像-提示匹配 多模态学习
📋 核心要点
- 大型视觉语言模型容易产生对象幻觉,即生成文本与图像内容不符,原因是模型对判别性图像特征的关注不足。
- AGLA通过组装全局特征(用于生成)和局部特征(用于判别)来缓解幻觉,无需额外训练,即插即用。
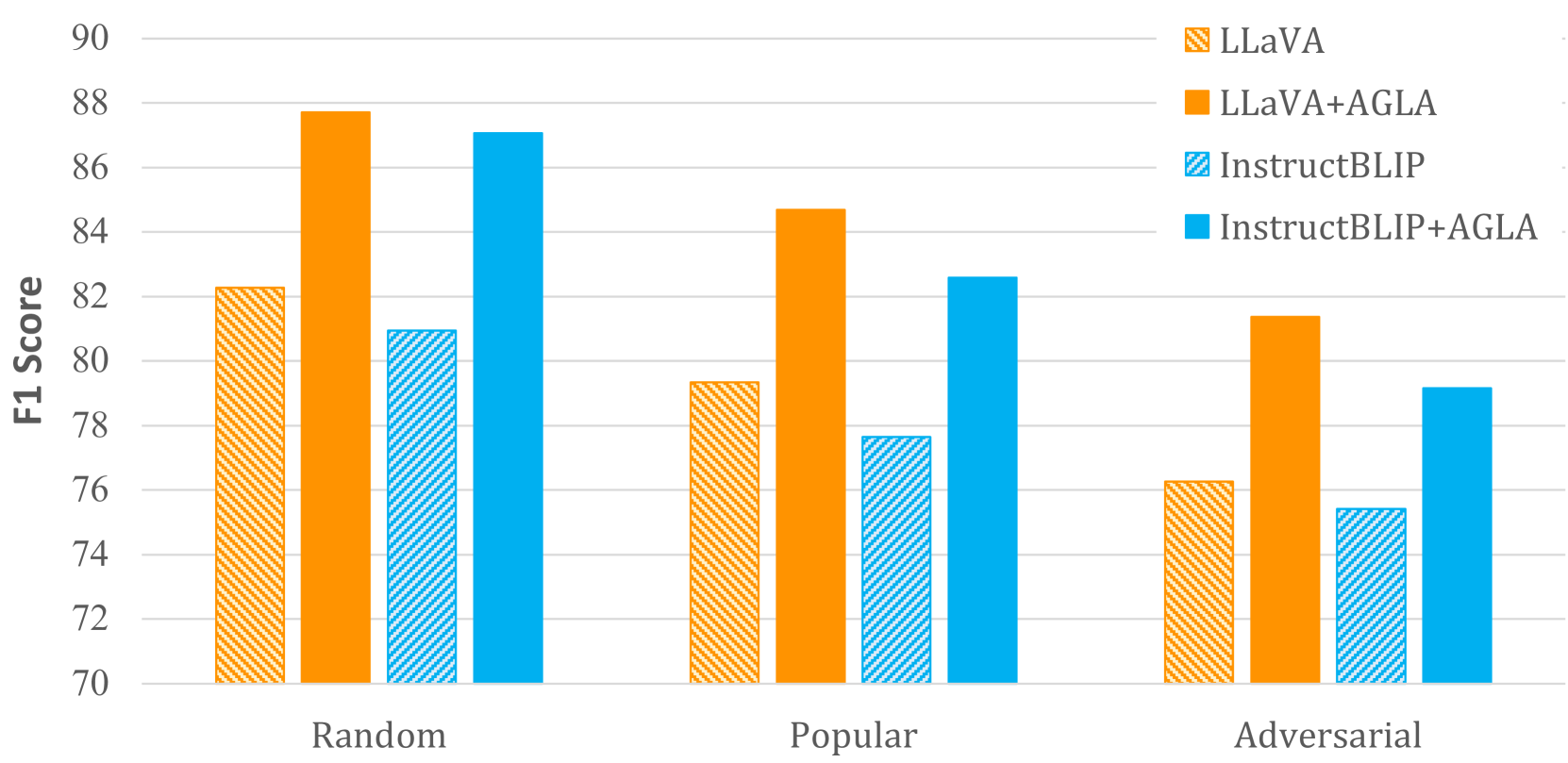
- 实验表明,AGLA能有效缓解LVLM中的幻觉问题,并在判别和生成任务中表现出广泛的适用性。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在各种多模态任务中取得了巨大成功,但经常遇到对象幻觉问题,即生成的文本响应与图像中的实际对象不一致。我们研究了不同的LVLMs,并指出对象幻觉的一个根本原因是缺乏对判别性图像特征的关注。具体来说,LVLMs通常主要关注与提示无关的全局特征,而不是与提示相关的局部特征,从而削弱了它们的视觉基础能力,并导致对象幻觉。我们提出了一种无训练且即插即用的方法,即全局和局部注意力组装(AGLA),通过同时组装用于响应生成的全局特征和用于视觉判别的局部特征来缓解幻觉。具体来说,我们引入了一种图像-提示匹配方案,该方案从图像中捕获与提示相关的局部特征,从而产生输入图像的增强视图,其中与提示相关的内容被突出显示,而无关的干扰被抑制。因此,可以通过校准的logit分布来缓解幻觉,该分布来自原始图像的生成全局特征和增强图像的判别局部特征。大量的实验表明AGLA在LVLM幻觉缓解方面的优越性,证明了其在判别和生成任务中的广泛适用性。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)中存在的对象幻觉问题,即模型生成的文本描述与图像中的实际对象不一致。现有LVLMs倾向于关注与prompt无关的全局特征,而忽略了与prompt相关的局部特征,导致视觉 grounding 能力不足,从而产生幻觉。
核心思路:论文的核心思路是同时利用全局特征和局部特征。全局特征用于生成文本描述,而局部特征用于视觉判别,从而提高模型对图像内容的理解和 grounding 能力。通过图像-prompt匹配,突出显示与prompt相关的局部特征,抑制无关干扰,增强模型的判别能力。
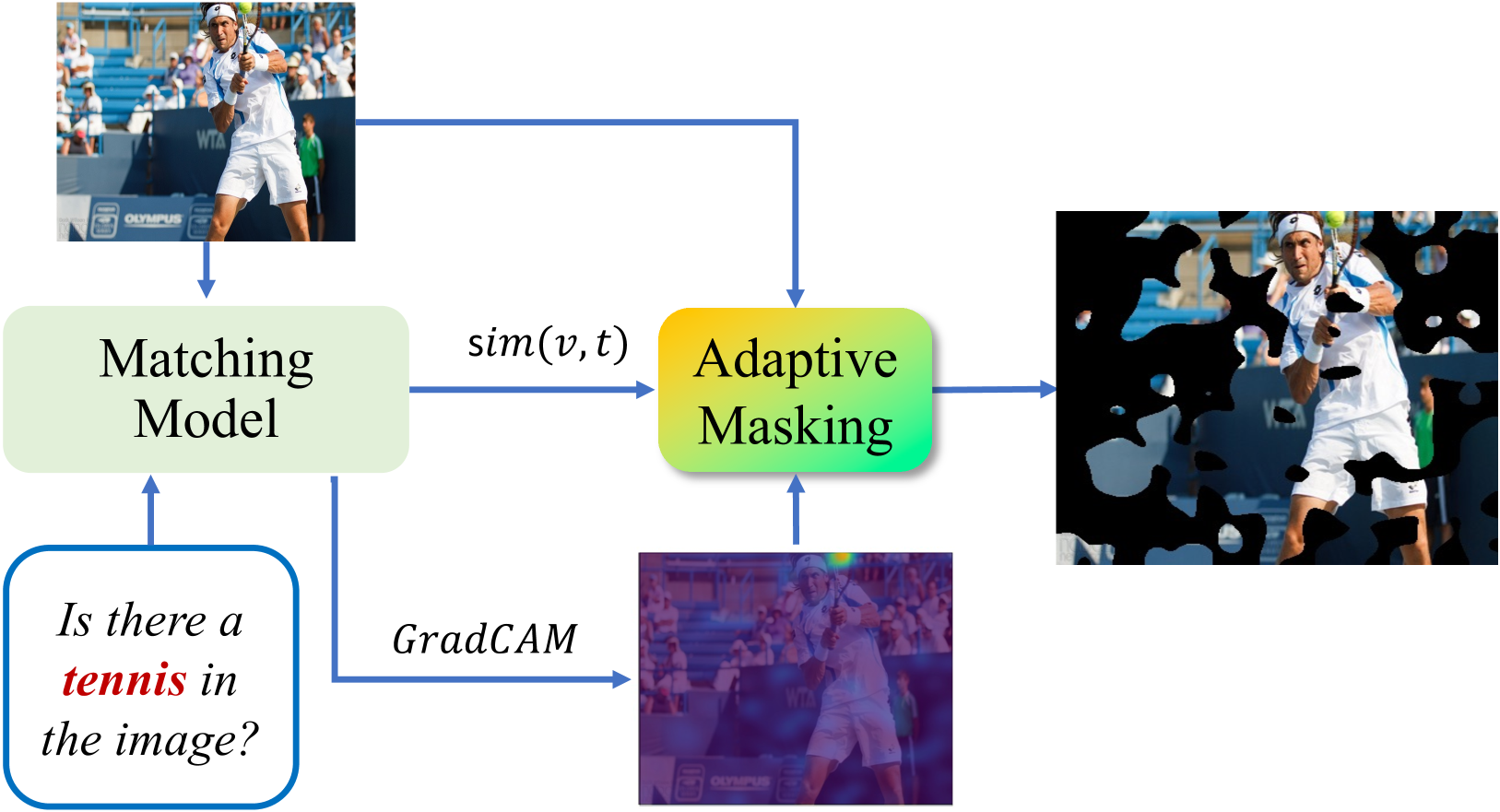
技术框架:AGLA 包含以下主要步骤:1) 输入图像和 prompt;2) 使用图像-prompt匹配方案提取与 prompt 相关的局部特征,生成增强图像;3) 从原始图像提取全局特征,从增强图像提取局部特征;4) 将全局特征和局部特征组装起来,用于生成文本描述,并通过校准的 logit 分布来缓解幻觉。
关键创新:AGLA 的关键创新在于提出了全局和局部注意力组装机制,将全局特征和局部特征结合起来,用于生成和判别。此外,图像-prompt匹配方案能够有效地提取与 prompt 相关的局部特征,增强模型的判别能力。AGLA 是一种无训练且即插即用的方法,易于集成到现有的 LVLM 中。
关键设计:图像-prompt匹配方案的具体实现方式未知,论文中可能使用了某种注意力机制或特征提取方法来突出显示与 prompt 相关的局部特征。校准的 logit 分布的具体计算方式也未知,可能涉及到某种加权或融合策略,以平衡全局特征和局部特征的影响。
🖼️ 关键图片

📊 实验亮点
论文通过大量实验验证了AGLA在缓解LVLM幻觉方面的有效性,证明了其在判别和生成任务中的广泛适用性。具体的性能数据和对比基线未知,但摘要强调了AGLA的优越性,表明其在相关指标上取得了显著提升。AGLA作为一种无训练且即插即用的方法,具有很高的实用价值。
🎯 应用场景
该研究成果可应用于各种需要视觉语言理解的场景,例如图像描述生成、视觉问答、图像编辑等。通过缓解对象幻觉问题,可以提高LVLM在这些任务中的准确性和可靠性,从而提升用户体验。该方法还有潜力应用于机器人导航、自动驾驶等领域,增强机器对环境的感知和理解能力。
📄 摘要(原文)
Despite great success across various multimodal tasks, Large Vision-Language Models (LVLMs) often encounter object hallucinations with generated textual responses being inconsistent with the actual objects in images. We examine different LVLMs and pinpoint that one root cause of object hallucinations lies with deficient attention on discriminative image features. Specifically, LVLMs often predominantly attend to prompt-irrelevant global features instead of prompt-relevant local features, undermining their visual grounding capacity and leading to object hallucinations. We propose Assembly of Global and Local Attention (AGLA), a training-free and plug-and-play approach that mitigates hallucinations by assembling global features for response generation and local features for visual discrimination simultaneously. Specifically, we introduce an image-prompt matching scheme that captures prompt-relevant local features from images, leading to an augmented view of the input image where prompt-relevant content is highlighted while irrelevant distractions are suppressed. Hallucinations can thus be mitigated with a calibrated logit distribution that is from generative global features of the original image and discriminative local features of the augmented image. Extensive experiments show the superiority of AGLA in LVLM hallucination mitigation, demonstrating its wide applicability across both discriminative and generative tasks. Our code is available at https://github.com/Lackel/AGLA.