Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
作者: Guowen Zhang, Lue Fan, Chenhang He, Zhen Lei, Zhaoxiang Zhang, Lei Zhang
分类: cs.CV, cs.RO
发布日期: 2024-06-15 (更新: 2024-06-18)
备注: 10 pages, 4 figures
💡 一句话要点
提出Voxel Mamba,一种用于点云三维目标检测的无组状态空间模型,提升精度和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 三维目标检测 点云 状态空间模型 体素 无组 空间邻近性 双尺度SSM 自动驾驶
📋 核心要点
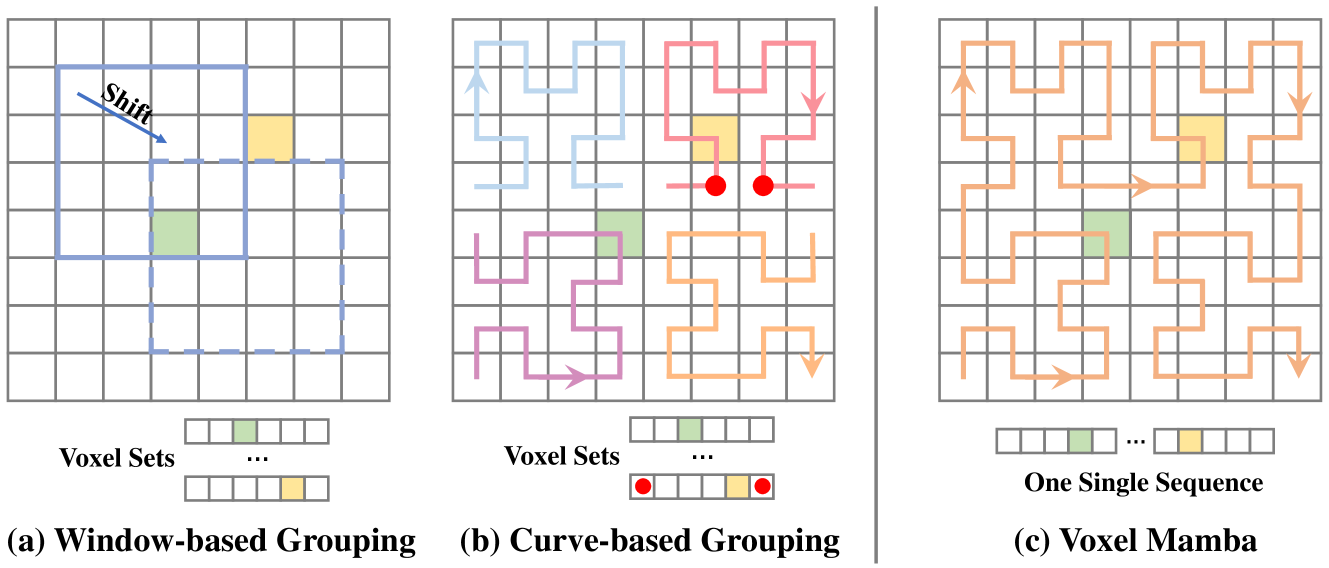
- 现有基于体素序列化的3D目标检测方法,由于Transformer的复杂度,难以兼顾分组大小和空间邻近性。
- Voxel Mamba采用无组策略,利用状态空间模型(SSM)的线性复杂度,将整个体素空间序列化为单个序列。
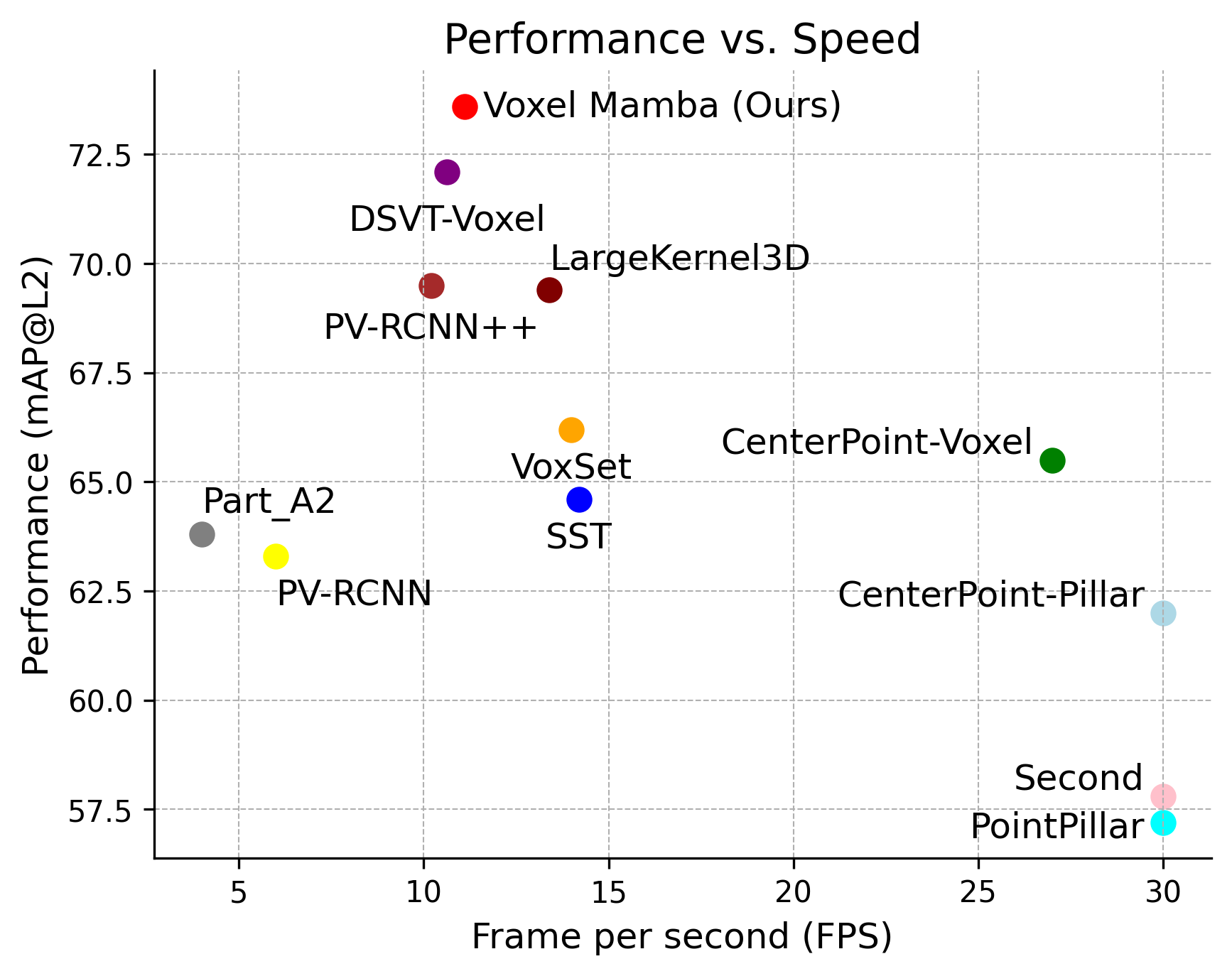
- 实验表明,Voxel Mamba在Waymo和nuScenes数据集上,精度超越现有方法,且计算效率显著提升。
📝 摘要(中文)
本文提出了一种名为Voxel Mamba的体素状态空间模型(Voxel SSM),用于解决基于点云的三维目标检测问题。现有方法通常将三维体素序列化并分组输入Transformer,但这种将三维体素转化为一维序列的方式不可避免地牺牲了体素的空间邻近性。虽然增大分组大小可以缓解这个问题,但Transformer的二次复杂度限制了这种做法。受状态空间模型(SSM)的启发,Voxel Mamba采用无组策略,将整个体素空间序列化为单个序列。SSM的线性复杂度使得这种无组设计成为可能,从而减轻了体素空间邻近性的损失。为了进一步增强空间邻近性,本文提出了一种双尺度SSM块,建立分层结构,从而在1D序列化曲线中实现更大的感受野,并在3D空间中实现更完整的局部区域。此外,通过位置编码,隐式地在无组框架下应用窗口划分,进一步增强了空间邻近性。在Waymo Open Dataset和nuScenes数据集上的实验表明,Voxel Mamba不仅实现了比现有最优方法更高的精度,而且在计算效率方面也表现出显著的优势。
🔬 方法详解
问题定义:现有基于体素的三维目标检测方法,通常将体素序列化后分组输入Transformer。这种方法的主要痛点在于,将三维空间信息压缩到一维序列中,会损失体素之间的空间邻近性。虽然增大分组大小可以保留更多空间信息,但Transformer的计算复杂度会随之呈二次方增长,限制了分组大小。
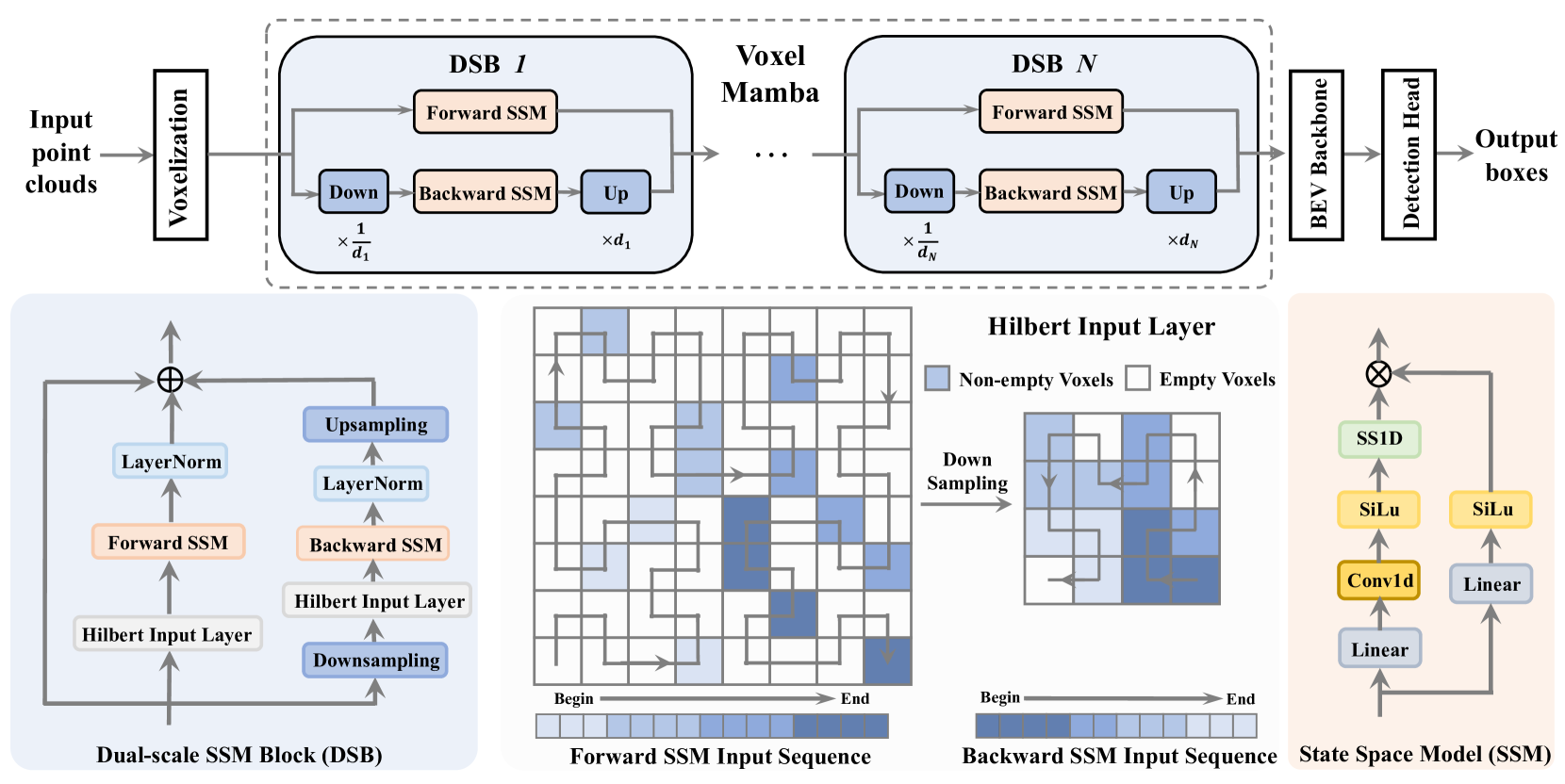
核心思路:Voxel Mamba的核心思路是利用状态空间模型(SSM)的线性复杂度,避免分组操作,直接将整个体素空间序列化为一个序列。这样可以在不显著增加计算负担的前提下,保留更多的空间邻近信息。此外,通过双尺度SSM块和位置编码,进一步增强空间信息的利用。
技术框架:Voxel Mamba的整体框架包括以下几个主要步骤:首先,将点云数据体素化,得到三维体素表示。然后,将整个体素空间序列化为一个一维序列。接着,使用多个双尺度SSM块对序列进行处理,提取特征。最后,使用检测头对特征进行解码,得到三维目标检测结果。其中,双尺度SSM块是Voxel Mamba的核心模块。
关键创新:Voxel Mamba的关键创新在于以下几点:一是采用了无组策略,避免了分组操作带来的空间信息损失;二是提出了双尺度SSM块,通过分层结构增强了空间信息的利用;三是利用位置编码,在无组框架下隐式地应用窗口划分,进一步增强了空间邻近性。
关键设计:双尺度SSM块包含两个并行的SSM分支,分别处理不同尺度的特征。一个分支处理全局特征,另一个分支处理局部特征。通过将两个分支的输出融合,可以同时利用全局和局部信息。位置编码采用相对位置编码,可以更好地捕捉体素之间的相对位置关系。损失函数采用标准的3D目标检测损失函数,包括分类损失和回归损失。
🖼️ 关键图片
📊 实验亮点
Voxel Mamba在Waymo Open Dataset和nuScenes数据集上取得了显著的性能提升。在Waymo Open Dataset上,Voxel Mamba的mAP和mAPH分别比现有最优方法提高了1.2%和1.5%。在nuScenes数据集上,Voxel Mamba的NDS和mAP分别比现有最优方法提高了1.0%和0.8%。同时,Voxel Mamba的计算效率也显著优于现有方法。
🎯 应用场景
Voxel Mamba在自动驾驶、机器人导航、三维场景理解等领域具有广泛的应用前景。它可以用于提高三维目标检测的精度和效率,从而提升自动驾驶系统的安全性,增强机器人对环境的感知能力,并为三维场景理解提供更准确的信息。
📄 摘要(原文)
Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency.