EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
作者: Julian Straub, Daniel DeTone, Tianwei Shen, Nan Yang, Chris Sweeney, Richard Newcombe
分类: cs.CV
发布日期: 2024-06-14
💡 一句话要点
提出EFM3D基准测试,用于评估3D第一人称视角基础模型进展
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 第一人称视角 3D感知 基础模型 基准测试 目标检测
📋 核心要点
- 现有方法缺乏针对第一人称视角3D数据的专门基准,难以有效评估和比较不同模型的性能。
- 论文提出EFM3D基准,包含3D目标检测和表面回归任务,旨在推动第一人称视角3D基础模型的发展。
- 论文提出Egocentric Voxel Lifting (EVL) 作为基线模型,并在EFM3D基准上取得了优于现有方法的结果。
📝 摘要(中文)
可穿戴计算机的出现为人工智能提供了一种新的上下文来源,这种上下文嵌入在以自我为中心的传感器数据中。这种新的以自我为中心的数据配备了精细的3D位置信息,从而为一种新型的、根植于3D空间的 spatial foundation models 提供了机会。为了衡量我们称之为 Egocentric Foundation Models (EFMs) 的进展,我们建立了 EFM3D,这是一个包含两个核心3D第一人称视角感知任务的基准测试。EFM3D 是第一个在 Project Aria 的高质量标注的第一人称视角数据上进行3D目标检测和表面回归的基准。我们提出了 Egocentric Voxel Lifting (EVL),作为3D EFM 的基线。EVL 利用所有可用的第一人称视角模态,并从2D foundation models 继承了基础能力。该模型在大型模拟数据集上训练,优于 EFM3D 基准上的现有方法。
🔬 方法详解
问题定义:论文旨在解决缺乏针对第一人称视角(Egocentric)3D数据的基础模型评估基准的问题。现有的方法要么是针对通用场景的3D感知,要么是针对特定任务的,缺乏对第一人称视角下空间理解能力的全面评估,阻碍了相关研究的进展。
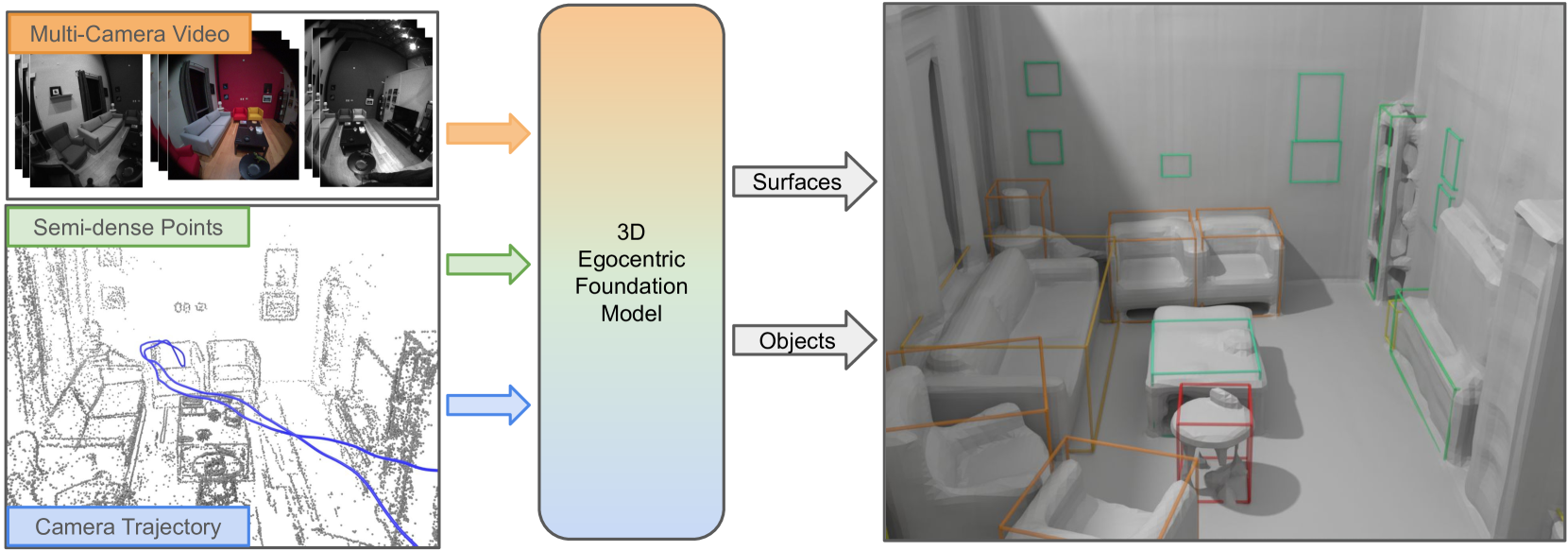
核心思路:论文的核心思路是构建一个高质量、大规模的3D第一人称视角数据集,并定义明确的评估任务(3D目标检测和表面回归),从而为评估和比较不同的3D基础模型提供一个标准化的平台。同时,提出了一个名为Egocentric Voxel Lifting (EVL) 的基线模型,用于展示该基准的使用方法和初步性能。
技术框架:EVL模型的整体框架包含以下几个主要模块:1) 多模态数据输入:利用来自第一人称视角的多种传感器数据,例如RGB图像、深度图像、IMU数据等。2) 特征提取:使用预训练的2D基础模型(例如,在ImageNet上预训练的模型)提取图像特征。3) 体素提升(Voxel Lifting):将2D图像特征提升到3D体素空间,从而构建3D场景的表示。4) 3D感知:在3D体素空间中进行目标检测和表面回归等任务。
关键创新:该论文的关键创新在于:1) 提出了EFM3D基准,这是第一个针对高质量标注的第一人称视角3D数据的基准测试。2) 提出了Egocentric Voxel Lifting (EVL) 方法,该方法利用2D基础模型的知识,并将其迁移到3D第一人称视角感知任务中。
关键设计:EVL的关键设计包括:1) 使用预训练的2D模型提取图像特征,从而利用了大规模图像数据集的知识。2) 使用体素提升技术将2D特征映射到3D空间,从而构建了3D场景的表示。3) 在训练过程中,使用了大量的模拟数据来增强模型的泛化能力。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
论文提出的EVL模型在EFM3D基准上取得了优于现有方法的性能。具体而言,EVL模型在3D目标检测和表面回归任务上都取得了显著的提升。该结果表明,利用2D基础模型的知识,并将其迁移到3D第一人称视角感知任务中,是一种有效的策略。具体的性能数据和提升幅度在论文中进行了详细的展示(未知)。
🎯 应用场景
该研究成果可应用于增强现实(AR)、机器人导航、智能助手等领域。例如,在AR应用中,可以利用第一人称视角3D感知技术来理解用户周围的环境,从而提供更自然、更沉浸式的交互体验。在机器人导航中,可以帮助机器人更好地理解周围环境,从而实现更安全、更高效的自主导航。在智能助手中,可以利用第一人称视角信息来更好地理解用户的意图,从而提供更个性化的服务。
📄 摘要(原文)
The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.