Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
作者: Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
分类: cs.CV
发布日期: 2024-06-14
💡 一句话要点
提出Med-HallMark医学幻觉检测基准与MediHall Score评估指标,并构建MediHallDetector模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 视觉语言模型 幻觉检测 多模态学习 医疗AI 基准测试 评估指标
📋 核心要点
- 现有医学领域缺乏专门针对大型视觉语言模型(LVLM)幻觉检测和评估的基准和方法。
- 提出Med-HallMark基准,包含多任务幻觉支持、多方面幻觉数据和分层幻觉分类,并设计MediHall Score评估指标。
- 构建MediHallDetector模型,通过多任务训练提升幻觉检测精度,实验表明MediHall Score能更细致地评估幻觉影响。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在医疗保健应用中日益重要,包括医学视觉问答和影像报告生成。虽然这些模型继承了基础大型语言模型(LLMs)的强大能力,但也继承了产生幻觉的倾向——这在高风险的医疗环境中是一个重大问题,因为容错空间极小。然而,目前还没有专门用于医学领域幻觉检测和评估的方法或基准。为了弥合这一差距,我们推出了Med-HallMark,这是第一个专门为医学多模态领域内的幻觉检测和评估而设计的基准。该基准提供多任务幻觉支持、多方面的幻觉数据和分层幻觉分类。此外,我们提出了一种新的医学评估指标MediHall Score,旨在通过考虑幻觉的严重程度和类型,采用分层评分系统来评估LVLM的幻觉,从而实现对潜在临床影响的细粒度评估。我们还提出了MediHallDetector,一种用于精确幻觉检测的新型医学LVLM,它采用多任务训练进行幻觉检测。通过广泛的实验评估,我们使用我们的基准为流行的LVLM建立了基线。研究结果表明,与传统指标相比,MediHall Score提供了对幻觉影响的更细致的理解,并证明了MediHallDetector的增强性能。我们希望这项工作能够显著提高LVLM在医疗应用中的可靠性。这项工作的所有资源将很快发布。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLM)在医学领域应用中存在的幻觉问题,即模型生成不真实或与输入不一致的信息。现有方法缺乏针对医学图像和文本的幻觉检测基准和评估指标,无法有效评估和降低LVLM在医疗场景中的风险。
核心思路:论文的核心思路是构建一个专门针对医学领域的幻觉检测基准(Med-HallMark)和一个评估指标(MediHall Score),并基于此训练一个更精确的幻觉检测模型(MediHallDetector)。通过提供高质量的幻觉数据和细粒度的评估标准,促进LVLM在医学领域的可靠应用。
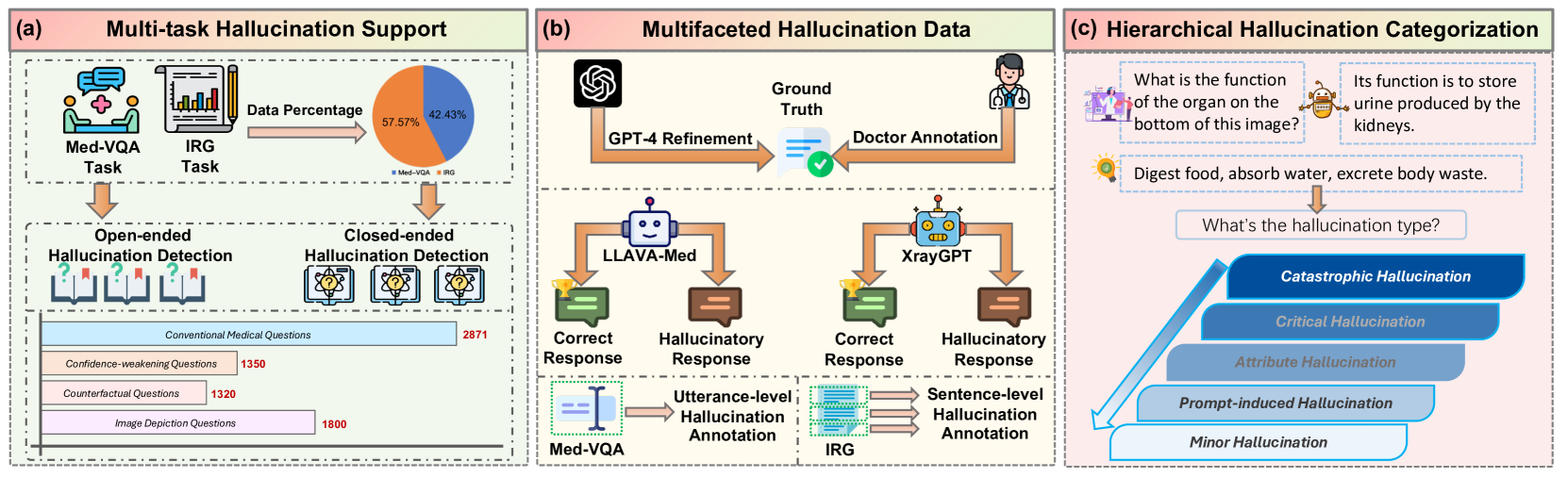
技术框架:整体框架包含三个主要部分:1) Med-HallMark基准的构建,包括多任务幻觉数据收集和分层幻觉分类;2) MediHall Score评估指标的设计,考虑幻觉的严重程度和类型;3) MediHallDetector模型的训练,采用多任务学习框架,同时进行幻觉检测和相关任务的学习。
关键创新:论文的关键创新在于:1) 首次提出了针对医学领域的幻觉检测基准Med-HallMark,填补了该领域的空白;2) 设计了MediHall Score评估指标,能够更细致地评估幻觉的临床影响;3) 构建了MediHallDetector模型,通过多任务学习提高了幻觉检测的准确性。
关键设计:Med-HallMark基准包含多种类型的幻觉数据,例如对象幻觉、属性幻觉和关系幻觉。MediHall Score采用分层评分系统,根据幻觉的类型和严重程度进行加权。MediHallDetector模型采用Transformer架构,并使用交叉熵损失函数进行训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MediHall Score能够更细致地评估幻觉的临床影响,相比传统指标具有优势。MediHallDetector模型在Med-HallMark基准上取得了显著的性能提升,表明其在医学幻觉检测方面具有更高的准确性。具体性能数据将在论文发布后公开。
🎯 应用场景
该研究成果可应用于医学影像诊断、医学报告生成、医学视觉问答等领域,提高医疗AI系统的可靠性和安全性。通过更准确地检测和评估LVLM的幻觉,可以减少误诊和漏诊的风险,辅助医生做出更明智的决策,并最终改善患者的治疗效果。未来,该研究可以推广到其他高风险领域,如金融和法律。
📄 摘要(原文)
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.