Open-Vocabulary Semantic Segmentation with Image Embedding Balancing
作者: Xiangheng Shan, Dongyue Wu, Guilin Zhu, Yuanjie Shao, Nong Sang, Changxin Gao
分类: cs.CV
发布日期: 2024-06-14
备注: CVPR2024
🔗 代码/项目: GITHUB
💡 一句话要点
EBSeg:通过图像嵌入平衡实现开放词汇语义分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 图像嵌入平衡 自适应解码器 语义结构一致性 CLIP模型
📋 核心要点
- 现有开放词汇语义分割方法易于过拟合训练类别,难以泛化到新类别,这是由于训练和新类别之间存在语义信息差距。
- EBSeg框架通过自适应平衡解码器(AdaB Decoder)生成并平衡训练类和新类的图像嵌入,从而提升泛化能力。
- EBSeg利用语义结构一致性损失(SSC Loss)对齐图像和文本特征空间,并结合SAM编码器补充空间信息,显著提升了分割性能。
📝 摘要(中文)
开放词汇语义分割是一项具有挑战性的任务,它要求模型输出超出封闭词汇表的图像语义掩码。尽管已经有很多工作利用强大的CLIP模型来完成这项任务,但由于训练类和新类之间语义信息的自然差距,它们仍然容易过度拟合训练类。为了克服这个挑战,我们提出了一个名为EBSeg的开放词汇语义分割新框架,它包含一个自适应平衡解码器(AdaB Decoder)和一个语义结构一致性损失(SSC Loss)。AdaB解码器旨在为训练类和新类生成不同的图像嵌入。随后,自适应地平衡这两种类型的嵌入,以充分利用它们识别训练类的能力和对新类的泛化能力。为了从CLIP中学习一致的语义结构,SSC Loss将图像特征空间中的类间亲和力与CLIP文本特征空间中的类间亲和力对齐,从而提高模型的泛化能力。此外,我们采用冻结的SAM图像编码器来补充CLIP特征由于低训练图像分辨率和CLIP固有的图像级监督而缺乏的空间信息。在各种基准上进行的大量实验表明,所提出的EBSeg优于最先进的方法。
🔬 方法详解
问题定义:开放词汇语义分割旨在识别图像中超出预定义类别集合的物体。现有方法,特别是基于CLIP的方法,虽然在零样本迁移上表现出潜力,但容易过拟合训练集中的类别,导致在新类别上的性能下降。这是因为训练集和新类别之间存在固有的语义差距,模型难以有效泛化。
核心思路:EBSeg的核心思路是通过平衡训练类别和新类别的图像嵌入,来缓解过拟合问题并提升泛化能力。具体来说,模型为这两类生成不同的嵌入,并自适应地调整它们的权重,从而更好地利用训练数据的判别能力和CLIP模型的泛化能力。此外,通过语义结构一致性损失,将图像特征空间中的类间关系与CLIP的文本特征空间对齐,从而学习到更鲁棒的语义表示。
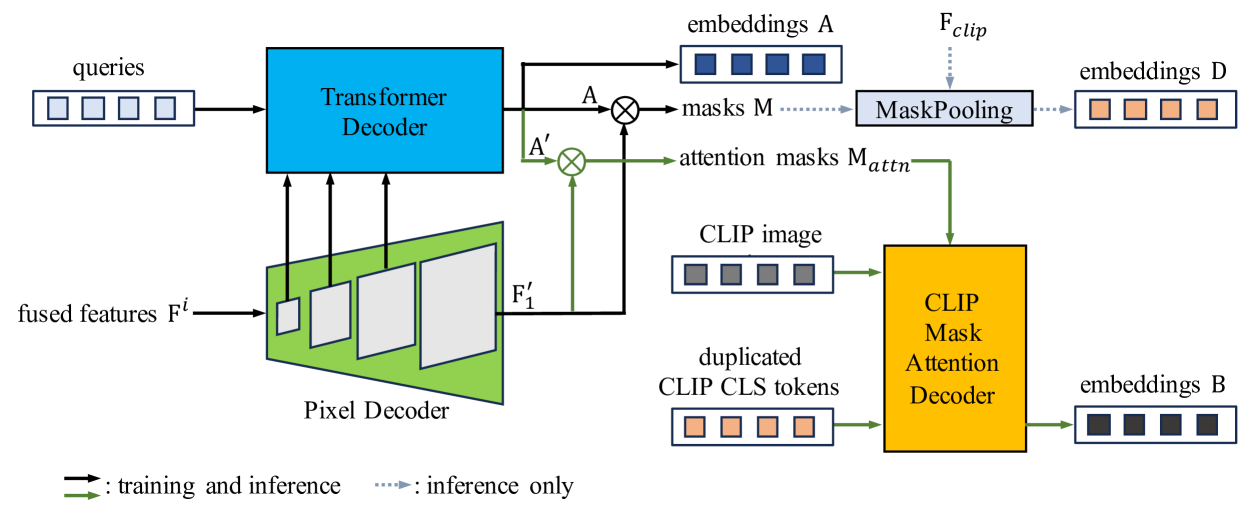
技术框架:EBSeg框架主要包含三个核心模块:CLIP图像编码器、自适应平衡解码器(AdaB Decoder)和SAM图像编码器。首先,CLIP图像编码器提取图像的全局特征。然后,AdaB Decoder基于这些特征生成训练类别和新类别的图像嵌入,并进行自适应平衡。同时,SAM图像编码器提供更精细的空间信息。最后,通过SSC Loss对齐图像和文本特征空间,并进行语义分割预测。
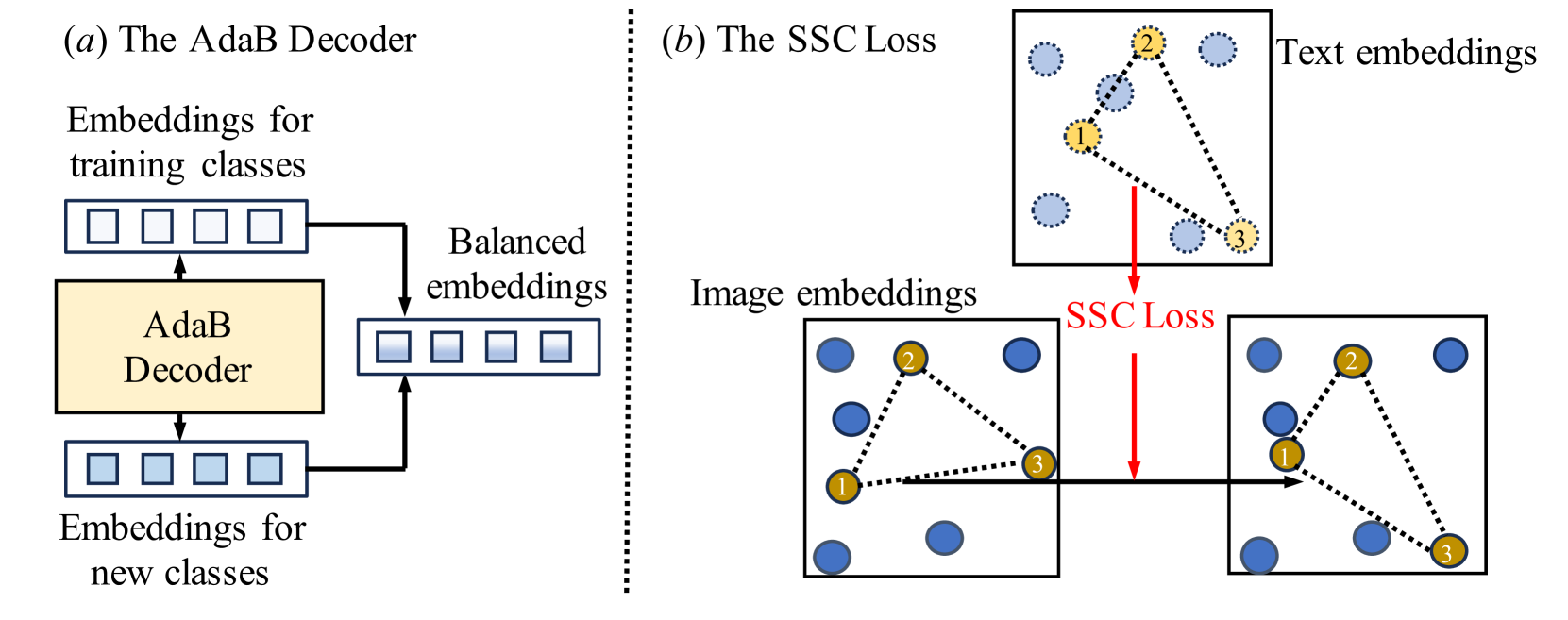
关键创新:EBSeg的关键创新在于AdaB Decoder和SSC Loss的设计。AdaB Decoder能够自适应地平衡训练类别和新类别的图像嵌入,从而缓解过拟合问题。SSC Loss通过对齐图像和文本特征空间中的类间关系,增强了模型的泛化能力。此外,结合SAM编码器补充空间信息也是一个重要的改进。
关键设计:AdaB Decoder包含两个分支,分别负责生成训练类别和新类别的图像嵌入。自适应平衡机制通过学习权重参数来调整这两个分支的输出。SSC Loss基于CLIP的文本特征计算类间亲和力矩阵,并将其作为监督信号,引导图像特征空间中的类间关系学习。SAM编码器采用冻结的权重,以避免与CLIP特征冲突。损失函数由分割损失和SSC Loss加权组成。
🖼️ 关键图片

📊 实验亮点
EBSeg在多个开放词汇语义分割基准测试中取得了显著的性能提升,超越了现有的最先进方法。实验结果表明,AdaB Decoder和SSC Loss能够有效地提高模型的泛化能力,使其在处理新类别时表现出更强的鲁棒性。具体性能数据请参考论文原文。
🎯 应用场景
EBSeg在机器人视觉、自动驾驶、遥感图像分析等领域具有广泛的应用前景。它可以使机器在没有预先训练的情况下识别新的物体类别,从而提高其适应性和智能化水平。例如,在机器人场景中,EBSeg可以帮助机器人识别未知的物体,并根据语义信息进行交互。
📄 摘要(原文)
Open-vocabulary semantic segmentation is a challenging task, which requires the model to output semantic masks of an image beyond a close-set vocabulary. Although many efforts have been made to utilize powerful CLIP models to accomplish this task, they are still easily overfitting to training classes due to the natural gaps in semantic information between training and new classes. To overcome this challenge, we propose a novel framework for openvocabulary semantic segmentation called EBSeg, incorporating an Adaptively Balanced Decoder (AdaB Decoder) and a Semantic Structure Consistency loss (SSC Loss). The AdaB Decoder is designed to generate different image embeddings for both training and new classes. Subsequently, these two types of embeddings are adaptively balanced to fully exploit their ability to recognize training classes and generalization ability for new classes. To learn a consistent semantic structure from CLIP, the SSC Loss aligns the inter-classes affinity in the image feature space with that in the text feature space of CLIP, thereby improving the generalization ability of our model. Furthermore, we employ a frozen SAM image encoder to complement the spatial information that CLIP features lack due to the low training image resolution and image-level supervision inherent in CLIP. Extensive experiments conducted across various benchmarks demonstrate that the proposed EBSeg outperforms the state-of-the-art methods. Our code and trained models will be here: https://github.com/slonetime/EBSeg.