MoME: Mixture of Multimodal Experts for Cancer Survival Prediction
作者: Conghao Xiong, Hao Chen, Hao Zheng, Dong Wei, Yefeng Zheng, Joseph J. Y. Sung, Irwin King
分类: eess.IV, cs.CV
发布日期: 2024-06-14
备注: 8 + 1/2 pages, early accepted to MICCAI2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出MoME模型,通过多模态专家混合解决癌症生存预测中异构数据融合问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 癌症生存预测 多模态融合 全切片图像 基因组数据 异构数据 深度学习 专家混合
📋 核心要点
- 现有癌症生存预测方法难以有效融合全切片图像和基因组数据,无法充分捕捉模态间的复杂异构性和交互。
- 提出有偏渐进编码范式,通过迭代编码和融合,利用一种模态作为参考来编码另一种模态,实现模态间的深度融合。
- 引入多模态专家混合层,动态选择专家,灵活适应不同场景,平衡或有偏地关注不同模态,提升预测性能。
📝 摘要(中文)
生存分析是一项具有挑战性的任务,需要整合全切片图像(WSIs)和基因组数据以进行全面的决策。这项任务面临两个主要挑战:显著的异质性以及两种模态之间复杂的模态间和模态内交互。以往的方法利用协同注意力机制,在分别编码后仅融合一次来自两种模态的特征。然而,由于模态之间的异构性,这些方法不足以建模复杂的任务。为了解决这些问题,我们提出了一种有偏渐进编码(BPE)范式,同时执行编码和融合。该范式在编码另一种模态时使用一种模态作为参考。它通过多次交替迭代实现模态的深度融合,逐步减少跨模态差异并促进互补交互。除了模态异质性之外,生存分析还涉及来自WSI、基因组及其组合的各种生物标志物。关键生物标志物可能存在于不同模态中,并且个体差异很大,因此需要模型灵活地适应特定场景。因此,我们进一步提出了一个多模态专家混合(MoME)层,以在BPE范式的每个阶段动态选择定制的专家。专家以不同程度地结合来自另一种模态的参考信息,从而在编码过程中能够平衡或有偏地关注不同的模态。大量的实验结果表明了我们的方法在各种数据集上的优越性能,包括TCGA-BLCA、TCGA-UCEC和TCGA-LUAD。
🔬 方法详解
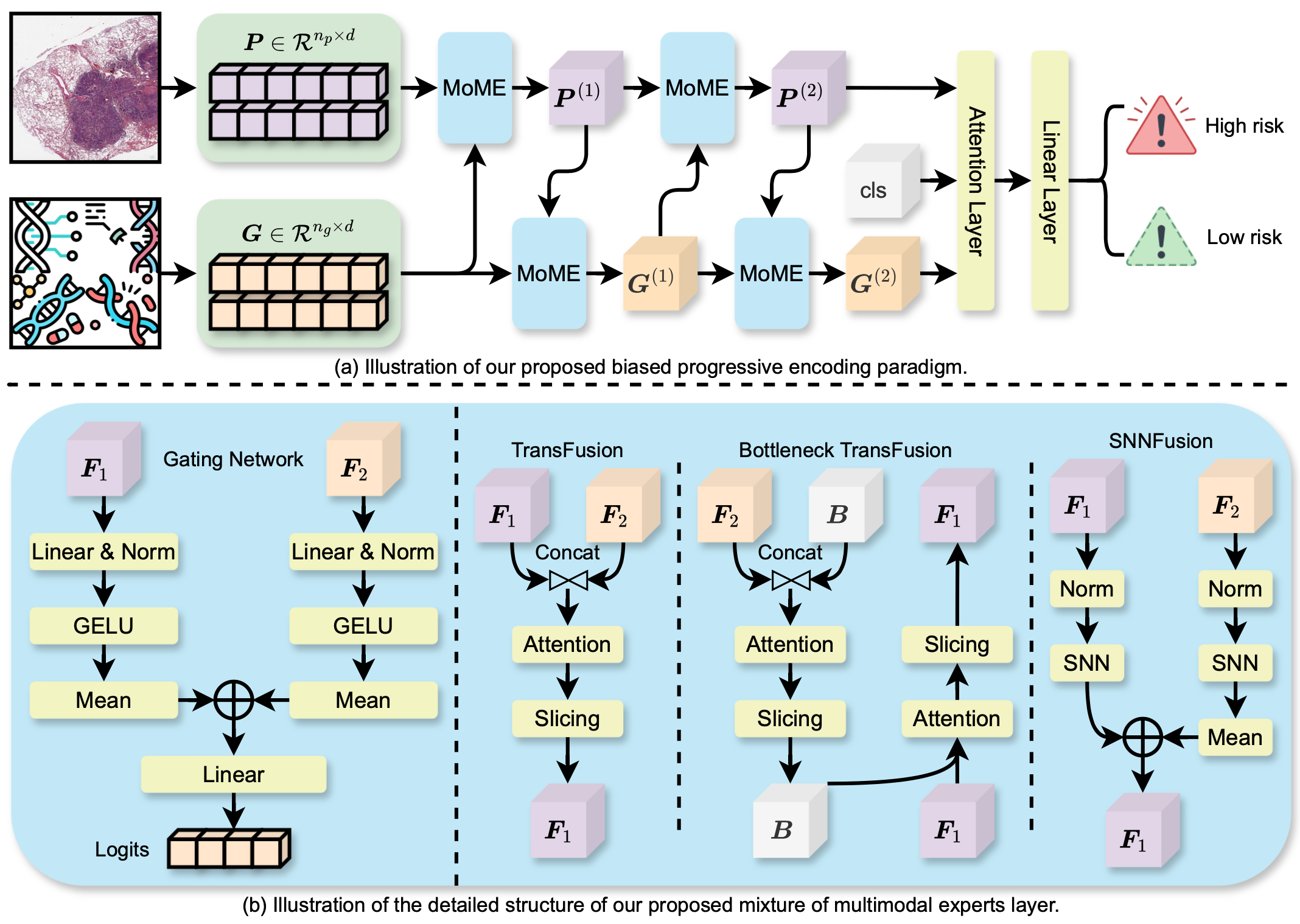
问题定义:论文旨在解决癌症生存预测中,如何有效融合全切片图像(WSI)和基因组数据的问题。现有方法,如基于协同注意力机制的方法,在分别编码后仅进行一次特征融合,无法充分建模两种模态之间复杂的异构性和交互关系,导致预测精度受限。
核心思路:论文的核心思路是设计一种能够逐步融合多模态信息的编码范式。通过迭代地将一种模态的信息作为参考来编码另一种模态,从而逐步减小模态间的差异,并促进互补交互。此外,通过引入多模态专家混合层,使模型能够根据不同样本动态地选择合适的专家,从而更好地适应不同场景。
技术框架:整体框架包含两个主要部分:有偏渐进编码(BPE)和多模态专家混合(MoME)。BPE通过多次迭代,交替使用一种模态作为参考来编码另一种模态,实现深度融合。MoME层位于BPE的每个阶段,负责动态选择专家,每个专家以不同程度地结合来自另一种模态的参考信息。最终,融合后的特征用于生存预测。
关键创新:论文的关键创新在于提出了有偏渐进编码(BPE)范式和多模态专家混合(MoME)层。BPE通过迭代编码和融合,有效解决了模态异构性问题。MoME层则使模型能够灵活地适应不同场景,动态选择合适的专家,从而更好地利用多模态信息。与现有方法相比,该方法能够更有效地建模模态间的复杂交互关系。
关键设计:BPE的迭代次数是一个重要的参数,需要根据具体数据集进行调整。MoME层中专家的数量和类型也需要根据先验知识或数据驱动的方式进行选择。损失函数通常采用生存分析中常用的损失函数,如Cox比例风险模型中的部分似然函数。网络结构方面,可以使用卷积神经网络(CNN)提取WSI特征,使用全连接网络或图神经网络(GNN)处理基因组数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MoME模型在TCGA-BLCA、TCGA-UCEC和TCGA-LUAD等多个癌症数据集上均取得了优于现有方法的性能。相较于基线模型,MoME在C-index等指标上取得了显著提升,验证了其在癌症生存预测中的有效性。
🎯 应用场景
该研究成果可应用于临床癌症生存预测,辅助医生进行更精准的诊断和治疗方案制定。通过整合病理图像和基因组数据,可以更全面地评估患者的风险,并为个性化治疗提供依据。未来,该方法有望推广到其他疾病的生存分析和多模态数据融合任务中。
📄 摘要(原文)
Survival analysis, as a challenging task, requires integrating Whole Slide Images (WSIs) and genomic data for comprehensive decision-making. There are two main challenges in this task: significant heterogeneity and complex inter- and intra-modal interactions between the two modalities. Previous approaches utilize co-attention methods, which fuse features from both modalities only once after separate encoding. However, these approaches are insufficient for modeling the complex task due to the heterogeneous nature between the modalities. To address these issues, we propose a Biased Progressive Encoding (BPE) paradigm, performing encoding and fusion simultaneously. This paradigm uses one modality as a reference when encoding the other. It enables deep fusion of the modalities through multiple alternating iterations, progressively reducing the cross-modal disparities and facilitating complementary interactions. Besides modality heterogeneity, survival analysis involves various biomarkers from WSIs, genomics, and their combinations. The critical biomarkers may exist in different modalities under individual variations, necessitating flexible adaptation of the models to specific scenarios. Therefore, we further propose a Mixture of Multimodal Experts (MoME) layer to dynamically selects tailored experts in each stage of the BPE paradigm. Experts incorporate reference information from another modality to varying degrees, enabling a balanced or biased focus on different modalities during the encoding process. Extensive experimental results demonstrate the superior performance of our method on various datasets, including TCGA-BLCA, TCGA-UCEC and TCGA-LUAD. Codes are available at https://github.com/BearCleverProud/MoME.