Industrial Language-Image Dataset (ILID): Adapting Vision Foundation Models for Industrial Settings
作者: Keno Moenck, Duc Trung Thieu, Julian Koch, Thorsten Schüppstuhl
分类: cs.CV
发布日期: 2024-06-14
备注: Dataset at https://github.com/kenomo/ilid training- and evaluation-related code at https://github.com/kenomo/industrial-clip
💡 一句话要点
提出工业语言-图像数据集(ILID),并探索视觉基础模型在工业场景的迁移学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工业视觉 视觉基础模型 迁移学习 自监督学习 数据集构建
📋 核心要点
- 现有视觉基础模型在通用场景表现出色,但在工业领域应用受限,缺乏领域数据和针对性训练。
- 论文提出一种基于网络爬取自动构建工业语言-图像数据集(ILID)的流程,无需人工标注。
- 通过在ILID上进行自监督迁移学习,提升视觉基础模型在工业下游任务中的性能。
📝 摘要(中文)
近年来,大型语言模型(LLM)的发展也推动了计算机视觉领域在大型多模态数据集上训练模型,并以自监督/半监督的方式进行训练,从而产生了视觉基础模型(VFM),例如对比语言-图像预训练(CLIP)。这些模型在日常物体或场景上表现出良好的泛化能力和出色的性能,即使在下游任务(模型未经过训练的任务)上也是如此。然而,在工业环境等专业领域的应用仍然是一个开放的研究问题。为了获得足够的性能,对模型进行微调或在特定领域的数据上进行迁移学习是不可避免的。在这项工作中,我们一方面介绍了一种基于网络爬取数据生成工业语言-图像数据集(ILID)的流程;另一方面,我们展示了有效的自监督迁移学习,并讨论了在廉价获得的ILID上训练后的下游任务,这些任务不需要人工标注或干预。通过提出的方法,我们通过将来自关于基础模型、迁移学习策略和应用的最先进研究的方法转移到工业领域做出了贡献。
🔬 方法详解
问题定义:现有视觉基础模型在通用领域表现良好,但在工业场景下的应用效果不佳。主要原因是缺乏大规模的工业领域标注数据,导致模型无法很好地泛化到工业应用中。现有方法通常需要大量人工标注,成本高昂且效率低下。
核心思路:论文的核心思路是利用网络爬取技术,自动构建大规模的工业语言-图像数据集(ILID),从而避免人工标注的成本。然后,利用自监督学习方法,在ILID上对视觉基础模型进行迁移学习,使其适应工业场景的特点。
技术框架:该方法主要包含两个阶段:1) 数据集构建阶段:通过网络爬取,收集与工业相关的图像和文本数据,并构建ILID数据集。2) 模型训练阶段:在ILID数据集上,利用自监督学习方法(例如对比学习),对视觉基础模型进行预训练或微调,使其学习到工业领域的视觉特征。
关键创新:该方法的主要创新在于提出了一种自动构建工业领域数据集的流程,无需人工标注,大大降低了数据获取的成本。此外,通过自监督学习,可以有效地利用未标注的数据,提升模型在工业场景下的性能。
关键设计:数据集构建阶段的关键在于如何选择合适的关键词和爬取策略,以保证数据的质量和多样性。模型训练阶段的关键在于选择合适的自监督学习方法和损失函数,以及调整模型的超参数,以获得最佳的性能。
🖼️ 关键图片
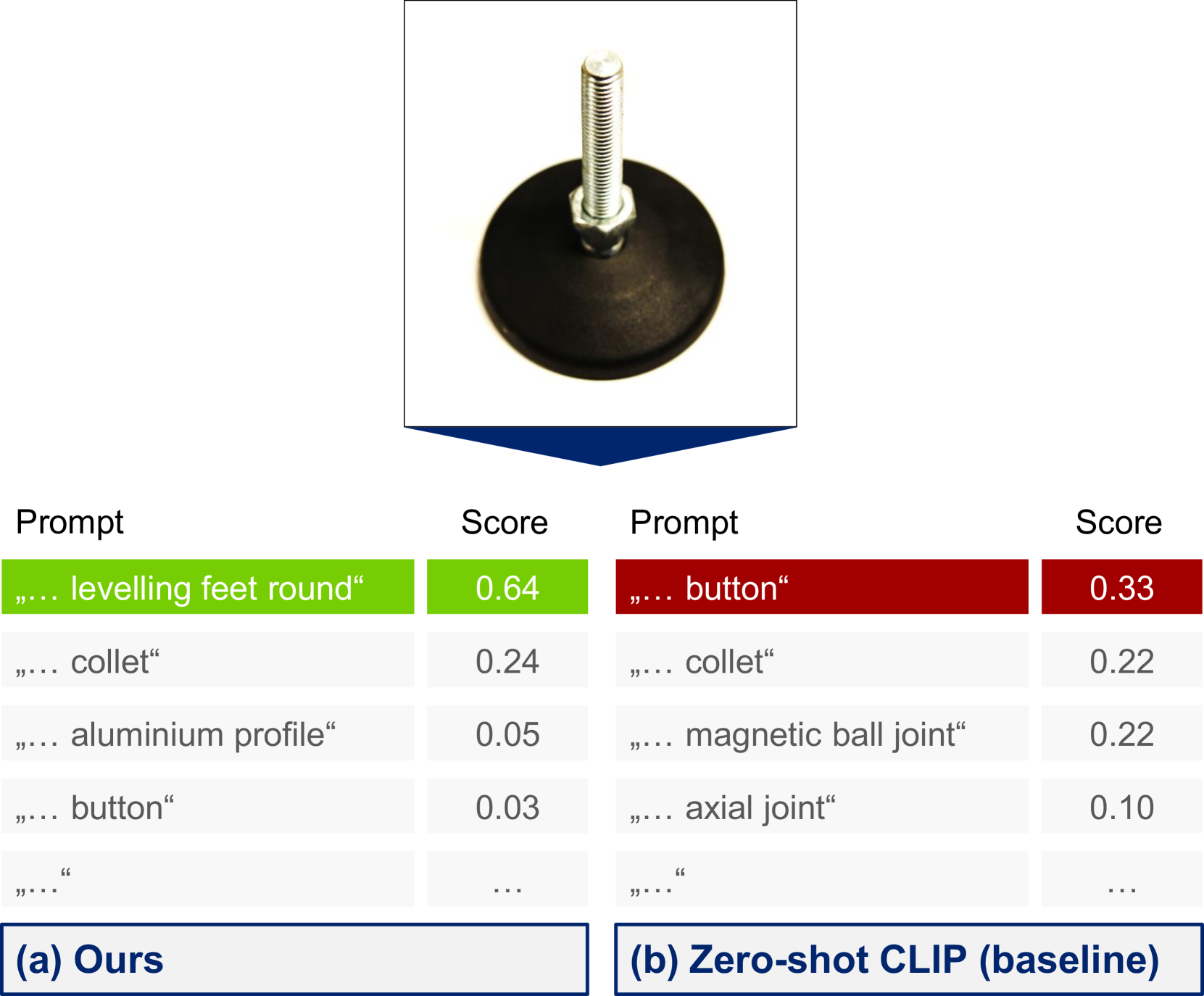
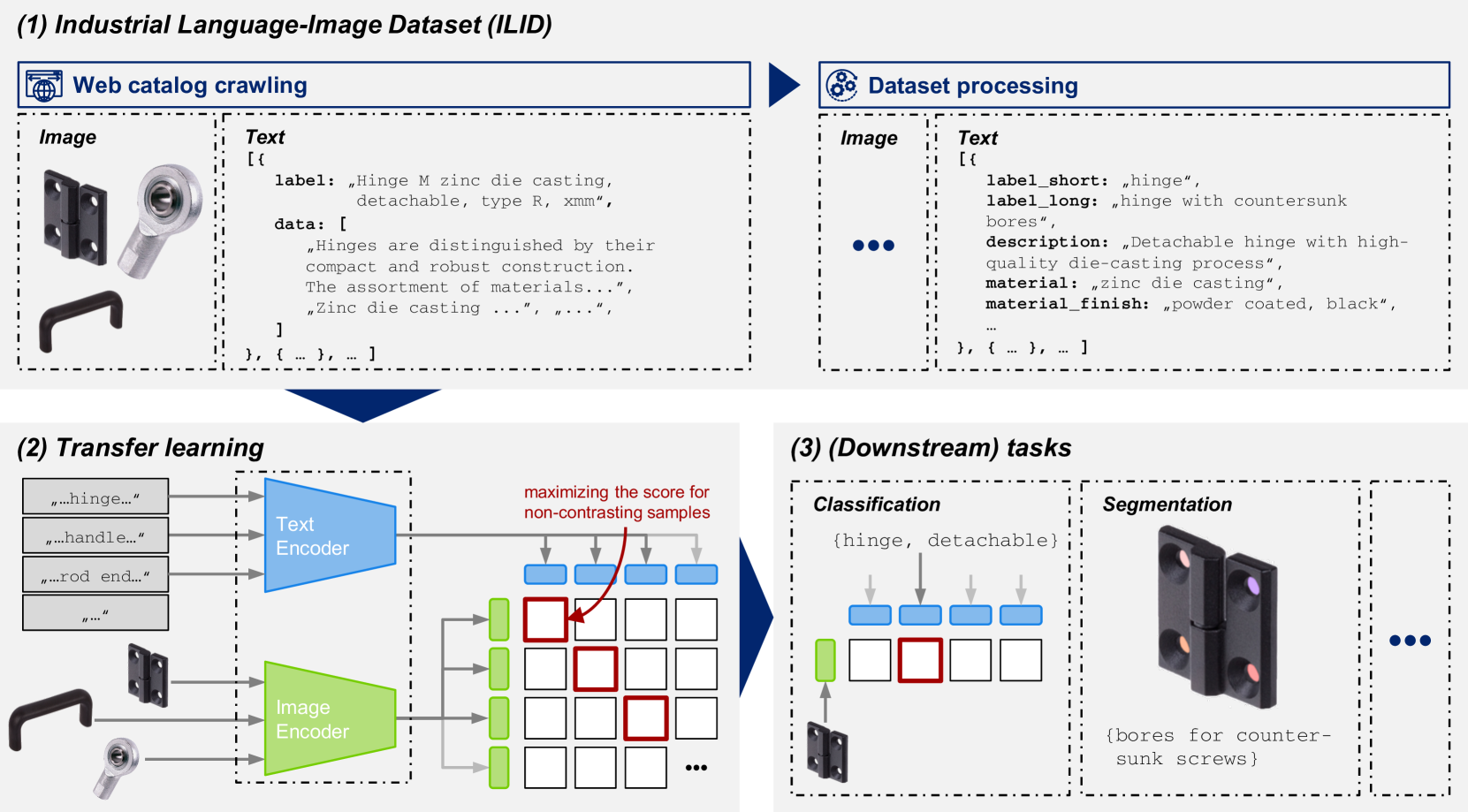

📊 实验亮点
论文提出了ILID数据集,并展示了在ILID上进行自监督迁移学习的有效性。虽然论文中没有给出具体的性能数据,但强调了该方法在无需人工标注的情况下,能够提升视觉基础模型在工业下游任务中的性能,为工业领域的视觉应用提供了新的思路。
🎯 应用场景
该研究成果可广泛应用于工业自动化、智能制造等领域。例如,可用于工业产品的缺陷检测、机器人视觉导航、设备状态监测等任务。通过提升视觉基础模型在工业场景下的性能,可以提高生产效率、降低生产成本,并实现更智能化的工业生产。
📄 摘要(原文)
In recent years, the upstream of Large Language Models (LLM) has also encouraged the computer vision community to work on substantial multimodal datasets and train models on a scale in a self-/semi-supervised manner, resulting in Vision Foundation Models (VFM), as, e.g., Contrastive Language-Image Pre-training (CLIP). The models generalize well and perform outstandingly on everyday objects or scenes, even on downstream tasks, tasks the model has not been trained on, while the application in specialized domains, as in an industrial context, is still an open research question. Here, fine-tuning the models or transfer learning on domain-specific data is unavoidable when objecting to adequate performance. In this work, we, on the one hand, introduce a pipeline to generate the Industrial Language-Image Dataset (ILID) based on web-crawled data; on the other hand, we demonstrate effective self-supervised transfer learning and discussing downstream tasks after training on the cheaply acquired ILID, which does not necessitate human labeling or intervention. With the proposed approach, we contribute by transferring approaches from state-of-the-art research around foundation models, transfer learning strategies, and applications to the industrial domain.