Depth Anything V2
作者: Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
分类: cs.CV
发布日期: 2024-06-13
备注: Project page: https://depth-anything-v2.github.io
💡 一句话要点
Depth Anything V2:通过大规模合成数据和知识蒸馏,实现高效鲁棒的单目深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 深度学习 知识蒸馏 合成数据 伪标签 模型泛化 机器人视觉
📋 核心要点
- 现有单目深度估计模型在泛化性和效率上存在不足,尤其是在真实场景中。
- Depth Anything V2 核心在于利用大规模合成数据训练教师模型,再通过伪标签指导学生模型,提升泛化能力。
- 实验表明,该方法在效率和精度上均优于现有方法,并构建了更全面的评估基准。
📝 摘要(中文)
本文提出了Depth Anything V2。我们没有追求花哨的技术,而是旨在揭示构建强大单目深度估计模型的关键发现。与V1相比,该版本通过三个关键实践产生了更精细、更鲁棒的深度预测:1) 用合成图像替换所有带标签的真实图像,2) 扩大教师模型的能力,3) 通过大规模伪标签真实图像的桥梁来指导学生模型。与基于Stable Diffusion的最新模型相比,我们的模型效率更高(速度快10倍以上)且更准确。我们提供不同规模的模型(从25M到1.3B参数)以支持广泛的场景。受益于其强大的泛化能力,我们使用度量深度标签对它们进行微调,以获得我们的度量深度模型。除了我们的模型之外,考虑到当前测试集中有限的多样性和频繁的噪声,我们构建了一个具有精确注释和多样化场景的通用评估基准,以促进未来的研究。
🔬 方法详解
问题定义:单目深度估计旨在从单张图像预测场景的深度信息。现有方法通常依赖于真实世界标注数据,但标注成本高昂且数据多样性有限,导致模型泛化能力不足。此外,基于扩散模型的深度估计方法虽然精度较高,但计算效率较低,难以满足实时应用需求。
核心思路:Depth Anything V2 的核心思路是利用大规模合成数据训练一个强大的教师模型,然后使用该教师模型生成伪标签,用于训练学生模型。这种方法可以有效利用合成数据的规模优势,同时通过知识蒸馏将教师模型的泛化能力传递给学生模型,从而提高模型在真实场景中的性能。
技术框架:Depth Anything V2 的整体框架包括三个主要步骤:1) 使用大规模合成数据训练教师模型;2) 使用训练好的教师模型对大规模真实图像数据集进行深度预测,生成伪标签;3) 使用带有伪标签的真实图像数据集训练学生模型。该框架允许使用不同规模的学生模型,以适应不同的计算资源和应用场景。
关键创新:Depth Anything V2 的关键创新在于其训练策略,即完全依赖合成数据训练教师模型,并通过伪标签的方式将知识迁移到学生模型。这种方法避免了对真实世界标注数据的依赖,降低了训练成本,并提高了模型的泛化能力。此外,该方法在效率上优于基于扩散模型的深度估计方法。
关键设计:Depth Anything V2 使用了大规模的合成数据集进行教师模型的训练。教师模型采用较大的网络结构,以提高其深度预测能力。在伪标签生成阶段,使用了多种数据增强技术,以提高伪标签的质量。学生模型可以使用不同大小的网络结构,以适应不同的计算资源。损失函数方面,使用了深度回归损失和梯度损失,以提高深度预测的精度和细节。
🖼️ 关键图片
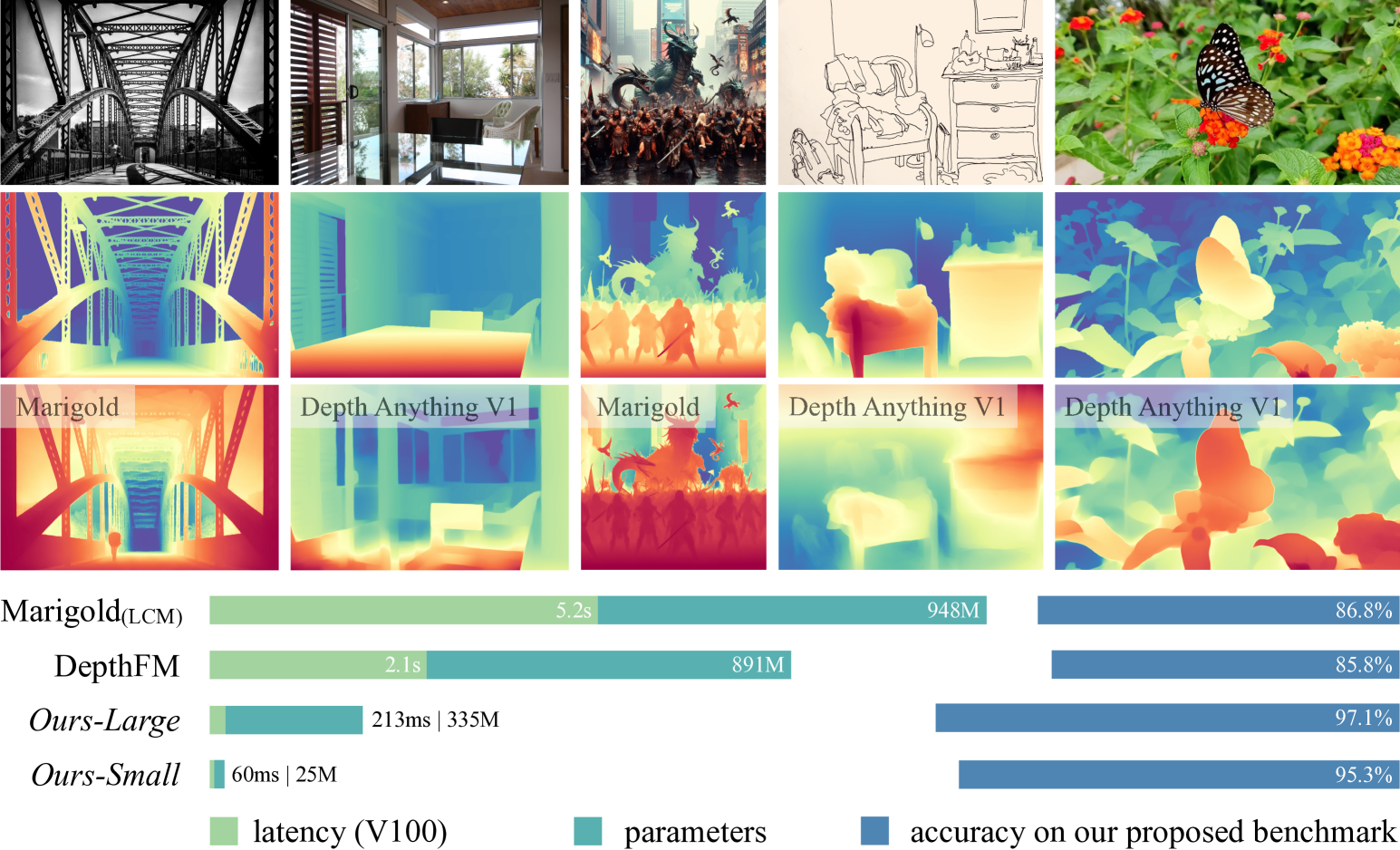


📊 实验亮点
Depth Anything V2 在效率和精度上均优于现有方法。与基于Stable Diffusion的最新模型相比,该模型速度快10倍以上,且精度更高。该论文还构建了一个具有精确注释和多样化场景的通用评估基准,为未来的研究提供了参考。不同规模的模型(从25M到1.3B参数)支持广泛的场景。
🎯 应用场景
Depth Anything V2 在机器人导航、自动驾驶、增强现实、虚拟现实等领域具有广泛的应用前景。它可以为机器人提供环境感知能力,帮助自动驾驶车辆进行场景理解,并为AR/VR应用提供逼真的深度信息,提升用户体验。该研究的成果有助于推动深度估计技术在实际场景中的应用。
📄 摘要(原文)
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.