ConsistDreamer: 3D-Consistent 2D Diffusion for High-Fidelity Scene Editing
作者: Jun-Kun Chen, Samuel Rota Bulò, Norman Müller, Lorenzo Porzi, Peter Kontschieder, Yu-Xiong Wang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-06-13
备注: CVPR 2024
💡 一句话要点
ConsistDreamer:利用3D一致性2D扩散模型实现高保真场景编辑
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D一致性 场景编辑 扩散模型 计算机视觉 自监督学习
📋 核心要点
- 现有2D扩散模型在场景编辑中缺乏3D一致性,导致编辑结果在不同视角下不协调。
- ConsistDreamer通过引入周围视图、3D一致的结构化噪声和自监督一致性训练,增强了2D扩散模型的3D感知能力。
- 实验表明,ConsistDreamer在复杂场景编辑中显著提升了图像质量和3D一致性,尤其擅长处理复杂图案。
📝 摘要(中文)
本文提出ConsistDreamer,一种新颖的框架,通过3D感知和3D一致性来提升2D扩散模型,从而实现高保真、指令引导的场景编辑。为了克服2D扩散模型中缺乏3D一致性的根本限制,我们的关键见解是引入三种协同策略,增强2D扩散模型的输入,使其具有3D感知能力,并在训练过程中显式地强制执行3D一致性。具体来说,我们设计了周围视图作为2D扩散模型的上下文丰富输入,并生成3D一致的结构化噪声,而不是图像独立的噪声。此外,我们在每个场景的编辑过程中引入了自监督的一致性强化训练。广泛的评估表明,我们的ConsistDreamer在各种场景和编辑指令下,特别是在ScanNet++中复杂的、大规模室内场景中,实现了最先进的指令引导场景编辑性能,并显著提高了清晰度和精细纹理。值得注意的是,ConsistDreamer是第一个能够成功编辑复杂(例如,格子/方格)图案的作品。
🔬 方法详解
问题定义:现有2D扩散模型在进行场景编辑时,由于缺乏对场景3D结构的理解,生成的编辑结果在不同视角下往往不一致,导致场景编辑的真实感和可用性降低。尤其是在处理具有复杂纹理或几何结构的场景时,这种不一致性问题更加突出。
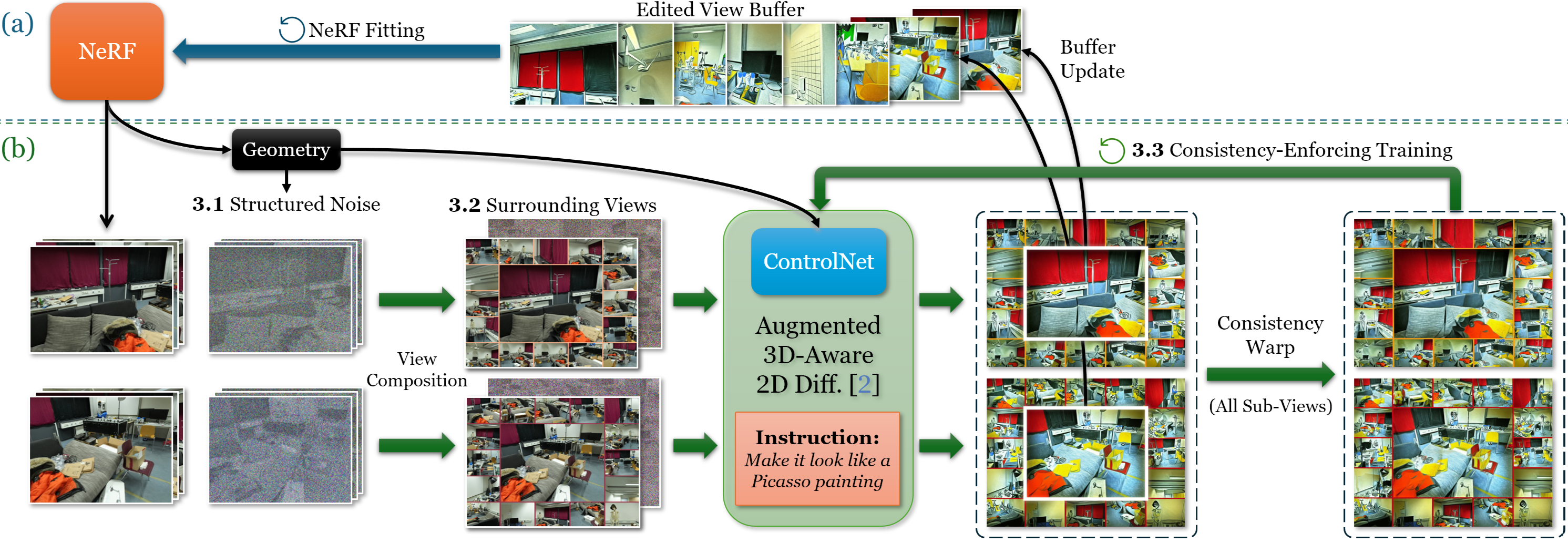
核心思路:ConsistDreamer的核心思路是通过增强2D扩散模型的输入,使其具备3D感知能力,并显式地在训练过程中强制执行3D一致性。具体来说,该方法利用周围视图作为上下文信息,生成3D一致的结构化噪声,并引入自监督学习来保证编辑结果在不同视角下的一致性。
技术框架:ConsistDreamer的整体框架包含以下几个主要模块:1) 周围视图生成模块:用于生成场景的多个周围视图,作为2D扩散模型的输入。2) 3D一致噪声生成模块:生成与场景3D结构一致的结构化噪声,替代传统的图像独立噪声。3) 2D扩散模型:以周围视图和3D一致噪声作为输入,生成编辑后的图像。4) 自监督一致性训练模块:通过比较不同视角下的编辑结果,利用自监督学习来强制执行3D一致性。
关键创新:ConsistDreamer的关键创新在于其3D一致性建模方法。与以往直接在2D图像上进行编辑的方法不同,ConsistDreamer通过引入周围视图和3D一致的结构化噪声,使2D扩散模型能够感知场景的3D结构,从而生成在不同视角下一致的编辑结果。此外,自监督一致性训练进一步增强了模型的3D一致性。
关键设计:在周围视图生成模块中,可以使用不同的视角选择策略,例如随机采样或基于视点覆盖率的采样。3D一致噪声生成模块可以利用深度信息或几何先验来生成与场景结构对齐的噪声。自监督一致性训练可以使用不同的损失函数来衡量不同视角下编辑结果的一致性,例如像素级差异或特征级差异。
🖼️ 关键图片


📊 实验亮点
ConsistDreamer在ScanNet++等复杂室内场景编辑任务上取得了显著的性能提升。实验结果表明,ConsistDreamer能够生成具有更高清晰度和更精细纹理的编辑结果,尤其擅长处理复杂的格子/方格图案。与其他基线方法相比,ConsistDreamer在3D一致性指标上也有显著提升,表明其能够生成在不同视角下更加一致的编辑结果。
🎯 应用场景
ConsistDreamer在虚拟现实、增强现实、游戏开发、室内设计等领域具有广泛的应用前景。它可以用于创建逼真的虚拟场景、编辑现有的3D模型、生成具有艺术风格的场景图像等。该技术能够提升用户在虚拟环境中的沉浸感和交互体验,并为内容创作者提供更强大的编辑工具。
📄 摘要(原文)
This paper proposes ConsistDreamer - a novel framework that lifts 2D diffusion models with 3D awareness and 3D consistency, thus enabling high-fidelity instruction-guided scene editing. To overcome the fundamental limitation of missing 3D consistency in 2D diffusion models, our key insight is to introduce three synergetic strategies that augment the input of the 2D diffusion model to become 3D-aware and to explicitly enforce 3D consistency during the training process. Specifically, we design surrounding views as context-rich input for the 2D diffusion model, and generate 3D-consistent, structured noise instead of image-independent noise. Moreover, we introduce self-supervised consistency-enforcing training within the per-scene editing procedure. Extensive evaluation shows that our ConsistDreamer achieves state-of-the-art performance for instruction-guided scene editing across various scenes and editing instructions, particularly in complicated large-scale indoor scenes from ScanNet++, with significantly improved sharpness and fine-grained textures. Notably, ConsistDreamer stands as the first work capable of successfully editing complex (e.g., plaid/checkered) patterns. Our project page is at immortalco.github.io/ConsistDreamer.