Instruct 4D-to-4D: Editing 4D Scenes as Pseudo-3D Scenes Using 2D Diffusion
作者: Linzhan Mou, Jun-Kun Chen, Yu-Xiong Wang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-06-13
备注: CVPR 2024
💡 一句话要点
Instruct 4D-to-4D:利用2D扩散模型实现高质量、时空一致的4D场景编辑
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D场景编辑 2D扩散模型 时空一致性 指令引导编辑 伪3D场景 光流引导 深度投影
📋 核心要点
- 现有动态场景编辑方法缺乏时空一致性,通常采用逐帧编辑,忽略了帧间依赖。
- Instruct 4D-to-4D将4D场景视为伪3D场景,解耦为时间一致性视频编辑和伪3D场景编辑两个子问题。
- 该方法在多种场景和编辑指令下进行了评估,结果表明其在时空一致性和细节清晰度方面均优于现有技术。
📝 摘要(中文)
本文提出了Instruct 4D-to-4D方法,旨在利用2D扩散模型实现4D感知和时空一致性,从而生成高质量的指令引导动态场景编辑结果。传统的2D扩散模型在动态场景编辑中的应用常常导致不一致性,这主要是由于其固有的逐帧编辑方法。为了解决将指令引导编辑扩展到4D的复杂性,我们的关键见解是将4D场景视为伪3D场景,并将其解耦为两个子问题:实现视频编辑中的时间一致性,并将这些编辑应用于伪3D场景。为此,我们首先使用anchor-aware注意力模块增强了Instruct-Pix2Pix (IP2P)模型,以进行批量处理和一致性编辑。此外,我们以滑动窗口方式集成了光流引导的外观传播,以实现更精确的帧间编辑,并结合基于深度的投影来管理伪3D场景的大量数据,然后进行迭代编辑以实现收敛。我们在各种场景和编辑指令中广泛评估了我们的方法,并证明它实现了空间和时间上一致的编辑结果,与现有技术相比,细节和清晰度显著提高。值得注意的是,Instruct 4D-to-4D具有通用性,适用于单目和具有挑战性的多相机场景。
🔬 方法详解
问题定义:现有方法在动态场景编辑中,特别是指令引导的编辑中,由于缺乏对时间维度信息的有效利用,导致编辑结果在时间上不一致,出现闪烁、形变等问题。逐帧编辑的方式无法保证整体场景的连贯性和真实感。
核心思路:将4D(3D空间+时间)场景视为伪3D场景,从而将4D编辑问题转化为一个在伪3D空间中进行编辑的问题。通过这种方式,可以利用现有的3D场景编辑技术,并针对时间维度进行优化,从而实现时空一致的编辑效果。
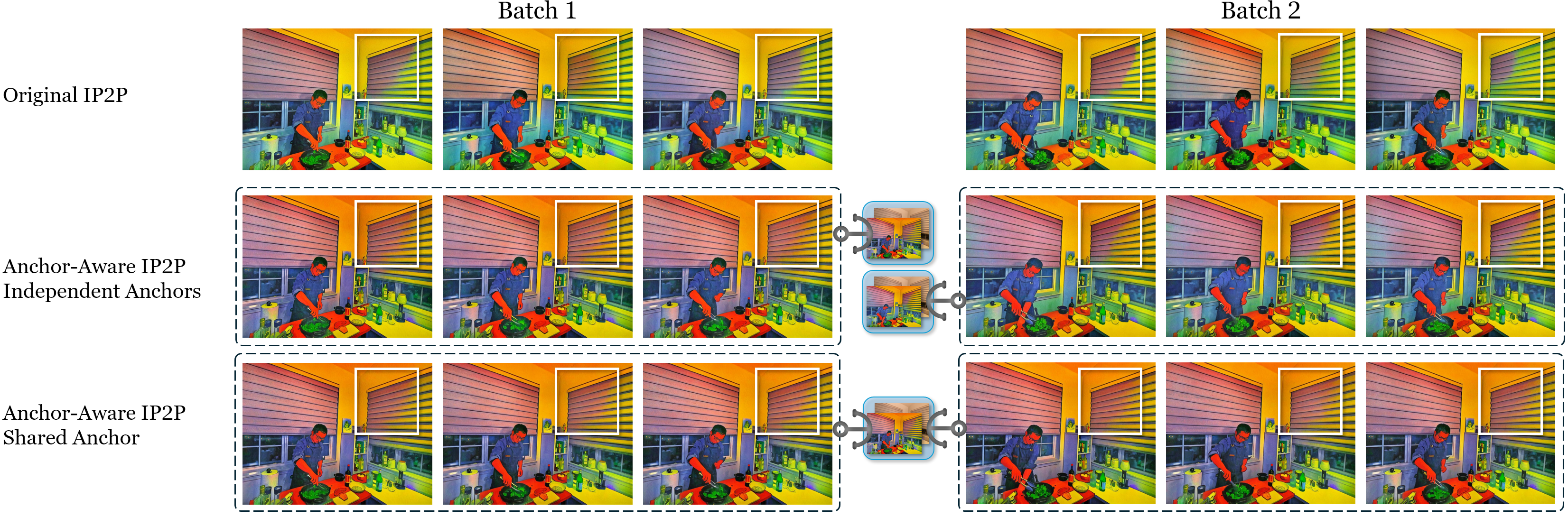
技术框架:Instruct 4D-to-4D主要包含以下几个模块:1) 基于Anchor-aware注意力机制增强的Instruct-Pix2Pix (IP2P)模型,用于实现初始的指令引导编辑;2) 光流引导的外观传播模块,用于在相邻帧之间传递编辑信息,保证时间一致性;3) 基于深度的投影模块,用于将2D编辑结果投影到伪3D空间中;4) 迭代编辑模块,通过多次迭代优化,最终得到高质量的编辑结果。
关键创新:该方法的核心创新在于将4D场景编辑问题转化为伪3D场景编辑问题,并利用2D扩散模型进行处理。Anchor-aware注意力机制和光流引导的外观传播模块是保证时间一致性的关键。此外,基于深度的投影模块实现了2D编辑到3D空间的有效转换。
关键设计:Anchor-aware注意力机制通过引入anchor帧,使得模型在处理每一帧时都能考虑到全局信息,从而保证编辑的一致性。光流引导的外观传播模块利用光流信息,将编辑信息从一帧传递到另一帧,从而减少了帧间的不一致性。迭代编辑模块通过多次迭代优化,逐步提高编辑质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Instruct 4D-to-4D在时空一致性和编辑质量方面均优于现有方法。与基线方法相比,该方法能够生成更清晰、更真实的编辑结果,并且在时间维度上更加稳定。该方法在单目和多相机场景下均表现出良好的性能,证明了其通用性和鲁棒性。
🎯 应用场景
Instruct 4D-to-4D可应用于电影特效制作、游戏开发、虚拟现实/增强现实内容生成等领域。该技术能够根据用户指令,对动态场景进行精确、一致的编辑,极大地提升了内容创作的效率和质量。未来,该技术有望应用于自动驾驶、机器人导航等领域,实现对动态环境的智能理解和编辑。
📄 摘要(原文)
This paper proposes Instruct 4D-to-4D that achieves 4D awareness and spatial-temporal consistency for 2D diffusion models to generate high-quality instruction-guided dynamic scene editing results. Traditional applications of 2D diffusion models in dynamic scene editing often result in inconsistency, primarily due to their inherent frame-by-frame editing methodology. Addressing the complexities of extending instruction-guided editing to 4D, our key insight is to treat a 4D scene as a pseudo-3D scene, decoupled into two sub-problems: achieving temporal consistency in video editing and applying these edits to the pseudo-3D scene. Following this, we first enhance the Instruct-Pix2Pix (IP2P) model with an anchor-aware attention module for batch processing and consistent editing. Additionally, we integrate optical flow-guided appearance propagation in a sliding window fashion for more precise frame-to-frame editing and incorporate depth-based projection to manage the extensive data of pseudo-3D scenes, followed by iterative editing to achieve convergence. We extensively evaluate our approach in various scenes and editing instructions, and demonstrate that it achieves spatially and temporally consistent editing results, with significantly enhanced detail and sharpness over the prior art. Notably, Instruct 4D-to-4D is general and applicable to both monocular and challenging multi-camera scenes. Code and more results are available at immortalco.github.io/Instruct-4D-to-4D.