SimGen: Simulator-conditioned Driving Scene Generation
作者: Yunsong Zhou, Michael Simon, Zhenghao Peng, Sicheng Mo, Hongzi Zhu, Minyi Guo, Bolei Zhou
分类: cs.CV
发布日期: 2024-06-13 (更新: 2024-12-07)
备注: arXiv admin note: text overlap with arXiv:2403.09630 by other authors
💡 一句话要点
SimGen:提出模拟器条件下的驾驶场景生成框架,提升合成数据质量与多样性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 驾驶场景生成 合成数据 扩散模型 模拟器 自动驾驶 数据增强 BEV感知
📋 核心要点
- 现有方法在小规模数据集上训练,缺乏外观和布局多样性,容易过拟合,泛化能力不足。
- SimGen通过混合模拟器和真实世界数据,利用级联扩散模型,解决Sim-to-Real差距和多条件冲突。
- DIVA数据集包含真实和模拟驾驶数据,SimGen在BEV检测和分割任务上表现出改进,并应用于安全关键数据生成。
📝 摘要(中文)
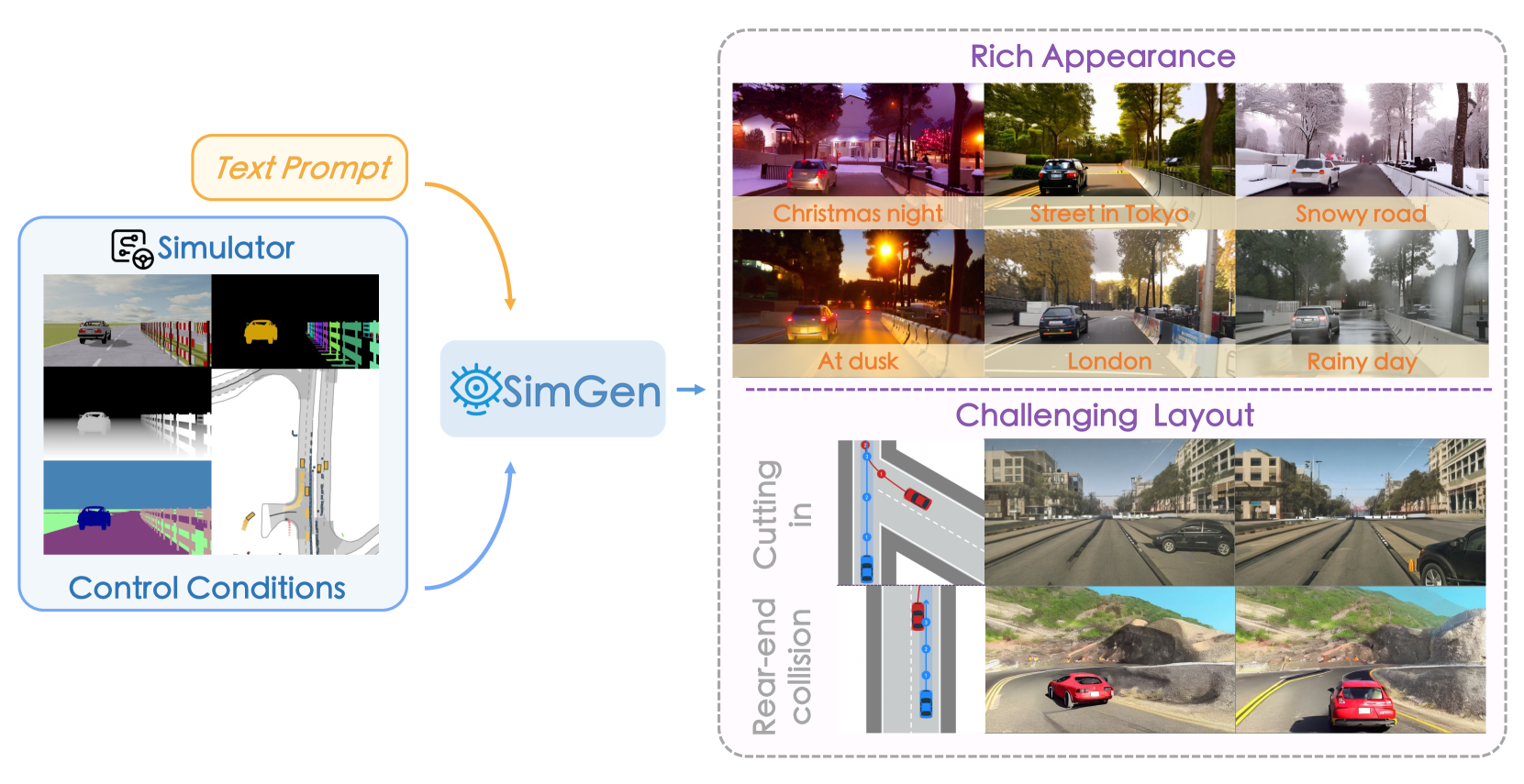
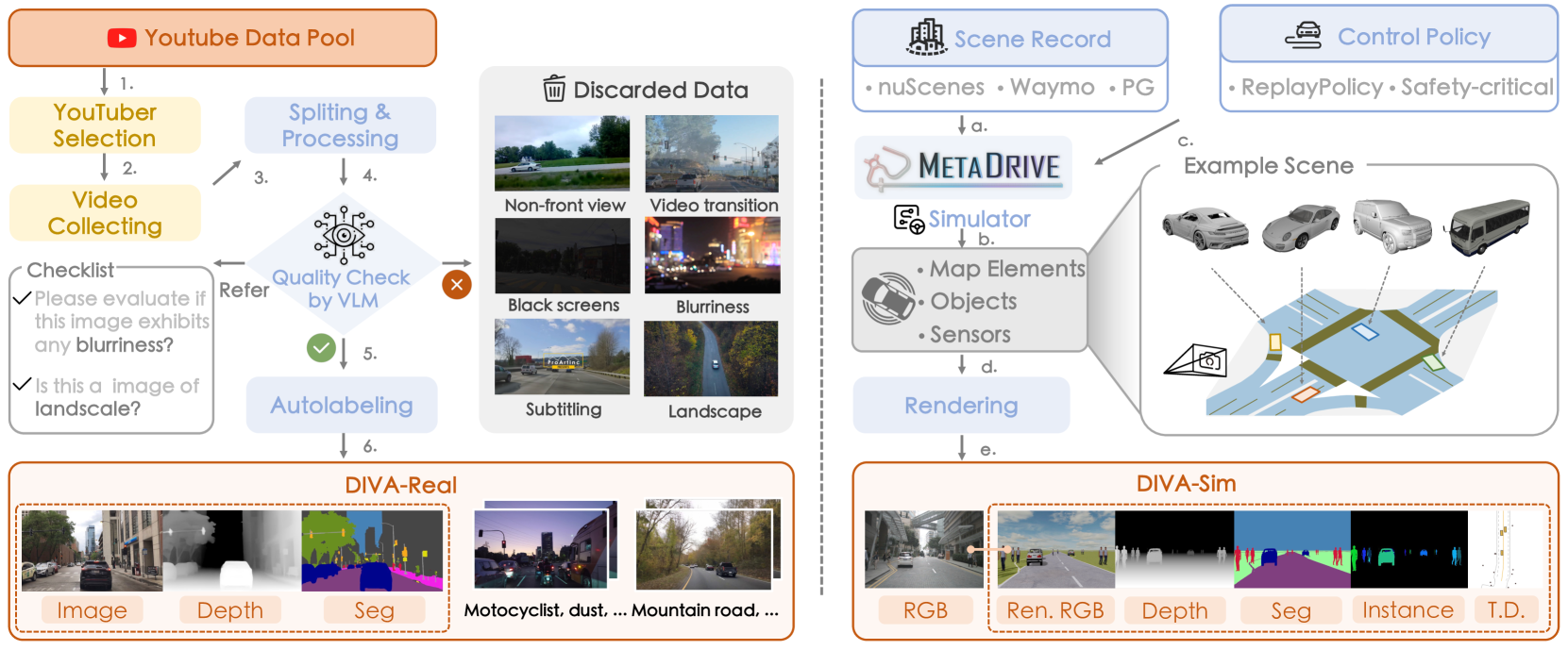
本文提出了一种名为SimGen的模拟器条件下的场景生成框架,旨在通过混合模拟器和真实世界的数据来学习生成多样化的驾驶场景,从而降低训练数据的标注成本。该框架采用了一种新颖的级联扩散管道,以解决模拟到真实的差距以及多条件冲突问题。为了增强生成的多样性,作者收集了一个名为DIVA的驾驶视频数据集,其中包含来自全球73个地点的超过147.5小时的真实驾驶视频以及来自MetaDrive模拟器的模拟驾驶数据。实验结果表明,SimGen在保持基于文本提示和模拟器布局的可控性的同时,实现了卓越的生成质量和多样性。此外,还证明了SimGen在BEV检测和分割任务中合成数据增强方面的改进,并展示了其在安全关键数据生成方面的能力。
🔬 方法详解
问题定义:现有基于扩散模型的驾驶场景生成方法,依赖于如nuScenes等小规模数据集,导致生成图像在外观和布局上缺乏多样性,容易过拟合验证集数据,泛化能力差。因此,如何生成具有更高质量、更多样性的驾驶场景,是本文要解决的核心问题。
核心思路:SimGen的核心思路是利用模拟器生成的数据和真实世界的数据进行混合训练,从而提高生成模型的多样性和泛化能力。通过模拟器提供场景布局等结构化信息,并结合真实数据学习场景的外观和细节,从而弥合模拟数据和真实数据之间的差距。
技术框架:SimGen采用级联扩散管道,包含多个阶段。首先,利用模拟器提供的场景布局(如车辆位置、道路结构等)作为条件,生成初始的场景图像。然后,通过后续的扩散阶段,逐步完善图像的细节和真实感,并结合文本提示等其他条件,实现对生成场景的精细控制。DIVA数据集用于训练该模型,包含真实世界和模拟数据。
关键创新:SimGen的关键创新在于其模拟器条件下的场景生成框架,以及级联扩散管道的设计。通过将模拟器提供的结构化信息与真实数据相结合,SimGen能够生成更加多样化和真实的驾驶场景。级联扩散管道能够有效地解决Sim-to-Real的差距,并处理多条件之间的冲突。
关键设计:SimGen的具体实现细节未知,但可以推测其损失函数可能包含对抗损失、感知损失等,以提高生成图像的真实感。网络结构可能采用U-Net等常用的扩散模型架构,并针对驾驶场景的特点进行优化。DIVA数据集的构建也是关键,需要保证数据的质量和多样性。
🖼️ 关键图片

📊 实验亮点
SimGen在驾驶场景生成任务上取得了优异的性能,能够生成高质量、多样化的驾驶场景。通过在BEV检测和分割任务上进行合成数据增强,证明了SimGen的有效性。具体性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
SimGen可用于自动驾驶系统的训练数据生成,尤其是在安全关键场景下,可以生成大量罕见但重要的corner case数据,提高自动驾驶系统的安全性和可靠性。此外,该方法还可以应用于虚拟现实、游戏等领域,生成逼真的驾驶场景。
📄 摘要(原文)
Controllable synthetic data generation can substantially lower the annotation cost of training data. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, overfitting often happens, where the trained models can only generate images based on the layout data from the validation set of the same dataset. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation.