Towards Vision-Language Geo-Foundation Model: A Survey
作者: Yue Zhou, Zhihang Zhong, Xue Yang
分类: cs.CV
发布日期: 2024-06-13 (更新: 2026-01-04)
备注: 18 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
综述性论文:面向视觉-语言地理基础模型(VLGFM)的研究进展与未来方向。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 地理空间数据 地球观测 多模态学习 基础模型 遥感图像 图像-文本检索
📋 核心要点
- 现有VLFMs在地球观测任务中表现不佳,主要原因是缺乏针对地理空间数据的训练。
- 本文聚焦于视觉-语言地理基础模型(VLGFMs),旨在利用大规模多模态地理空间数据提升模型性能。
- 本文是首个针对VLGFMs的全面综述,涵盖数据构建、模型架构和多模态地理空间任务应用等核心技术。
📝 摘要(中文)
视觉-语言基础模型(VLFMs)在图像描述、图像-文本检索、视觉问答和视觉定位等多种多模态任务中取得了显著进展。然而,大多数方法依赖于通用图像数据集的训练,缺乏地理空间数据导致其在地球观测方面的性能较差。近年来,涌现出大量地理空间图像-文本对数据集,以及在这些数据集上微调的VLFMs。这些新方法旨在利用大规模、多模态的地理空间数据来构建具有多样化地理感知能力的通用智能模型,我们称之为视觉-语言地理基础模型(VLGFMs)。本文全面回顾了VLGFMs,总结和分析了该领域的最新进展。特别地,我们介绍了VLGFMs兴起的背景和动机,强调了其独特的研究意义。然后,我们系统地总结了VLGFMs中采用的核心技术,包括数据构建、模型架构以及各种多模态地理空间任务的应用。最后,我们总结了关于未来研究方向的见解、问题和讨论。据我们所知,这是第一篇关于VLGFMs的全面文献综述。我们将持续追踪相关工作,地址为https://github.com/zytx121/Awesome-VLGFM。
🔬 方法详解
问题定义:现有视觉-语言基础模型(VLFMs)在处理地球观测任务时,由于缺乏地理空间数据的训练,性能显著下降。这些模型通常在通用图像数据集上进行训练,无法有效捕捉地理空间图像和文本之间的复杂关系。因此,如何构建能够理解和处理地理空间信息的VLFMs成为一个关键问题。
核心思路:本文的核心思路是综述并分析近年来涌现的视觉-语言地理基础模型(VLGFMs)。这些模型通过利用大规模的地理空间图像-文本对数据进行训练或微调,从而提升模型在地球观测任务中的性能。通过对现有VLGFMs的研究,可以更好地理解如何有效地利用地理空间数据来构建更强大的多模态模型。
技术框架:本文的综述框架主要包括以下几个方面:首先,介绍VLGFMs的背景和动机,强调其研究意义。其次,系统地总结VLGFMs中采用的核心技术,包括地理空间数据的构建方法、模型架构的设计以及各种多模态地理空间任务的应用。最后,对VLGFMs的未来研究方向进行展望,提出见解、问题和讨论。
关键创新:本文最重要的创新点在于它是首个针对视觉-语言地理基础模型(VLGFMs)的全面文献综述。与以往的视觉-语言模型综述不同,本文专注于地理空间领域,深入探讨了如何利用地理空间数据来提升模型在地球观测任务中的性能。
关键设计:本文的关键设计在于对VLGFMs的核心技术进行了系统性的总结和分析,包括数据构建、模型架构和应用。在数据构建方面,综述了各种地理空间图像-文本对数据集的构建方法。在模型架构方面,分析了不同VLFMs的设计思路和特点。在应用方面,探讨了VLGFMs在各种多模态地理空间任务中的应用,例如地理图像描述、地理图像-文本检索等。
🖼️ 关键图片

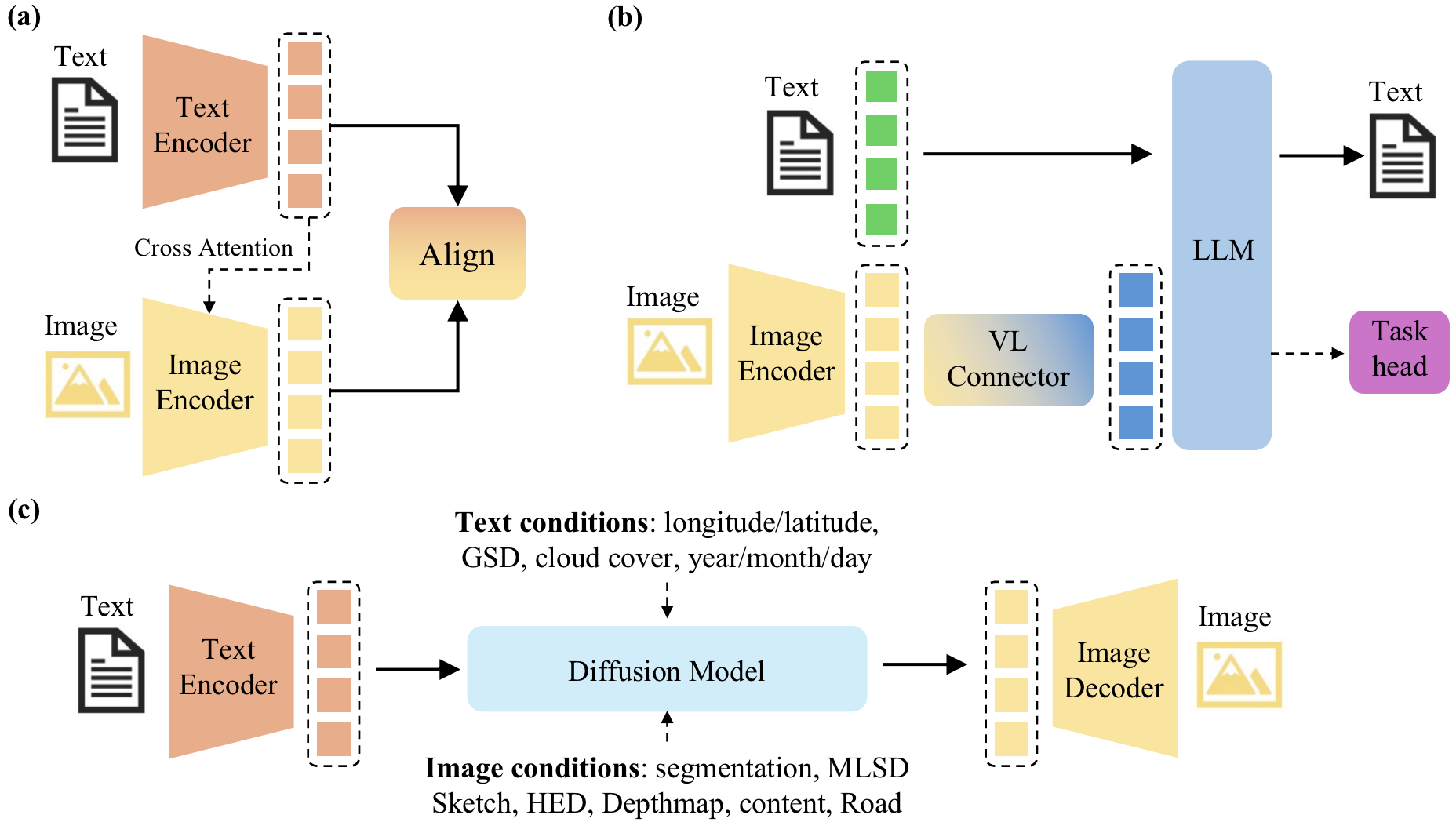
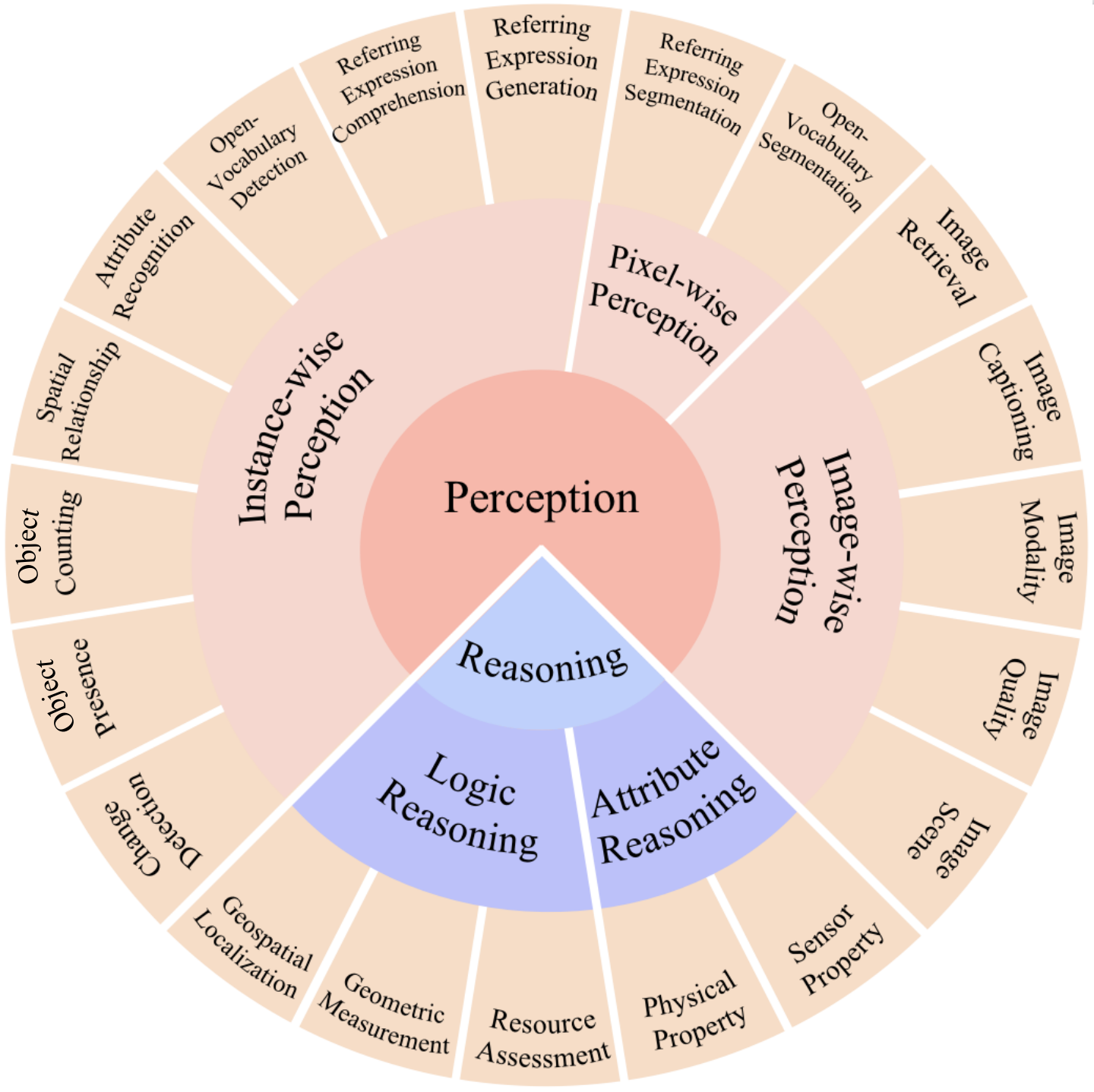
📊 实验亮点
本文作为首篇VLGFM的综述,系统性地整理了该领域的研究进展,为后续研究者提供了清晰的路线图。通过分析现有模型的优缺点,指出了未来可能的研究方向,例如如何更好地融合不同来源的地理空间数据,以及如何设计更有效的模型架构来提升性能。
🎯 应用场景
该研究成果可应用于智慧城市建设、环境监测、灾害预警、农业遥感等领域。通过构建更强大的视觉-语言地理基础模型,可以实现对地球观测数据的更有效理解和利用,为相关领域的决策提供支持,并促进可持续发展。
📄 摘要(原文)
Vision-Language Foundation Models (VLFMs) have made remarkable progress on various multimodal tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding. However, most methods rely on training with general image datasets, and the lack of geospatial data leads to poor performance on earth observation. Numerous geospatial image-text pair datasets and VLFMs fine-tuned on them have been proposed recently. These new approaches aim to leverage large-scale, multimodal geospatial data to build versatile intelligent models with diverse geo-perceptive capabilities, which we refer to as Vision-Language Geo-Foundation Models (VLGFMs). This paper thoroughly reviews VLGFMs, summarizing and analyzing recent developments in the field. In particular, we introduce the background and motivation behind the rise of VLGFMs, highlighting their unique research significance. Then, we systematically summarize the core technologies employed in VLGFMs, including data construction, model architectures, and applications of various multimodal geospatial tasks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To the best of our knowledge, this is the first comprehensive literature review of VLGFMs. We keep tracing related works at https://github.com/zytx121/Awesome-VLGFM.