ReMI: A Dataset for Reasoning with Multiple Images
作者: Mehran Kazemi, Nishanth Dikkala, Ankit Anand, Petar Devic, Ishita Dasgupta, Fangyu Liu, Bahare Fatemi, Pranjal Awasthi, Dee Guo, Sreenivas Gollapudi, Ahmed Qureshi
分类: cs.CV, cs.CL
发布日期: 2024-06-13
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
ReMI:一个用于多图推理的大型语言模型评测数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多图推理 大型语言模型 基准数据集 多模态学习 视觉推理
📋 核心要点
- 现有大型语言模型在多图推理能力方面仍有不足,缺乏专门的评测基准来衡量和改进这一能力。
- ReMI数据集旨在通过涵盖多种推理领域和场景,为评估LLM的多图推理能力提供一个全面的基准。
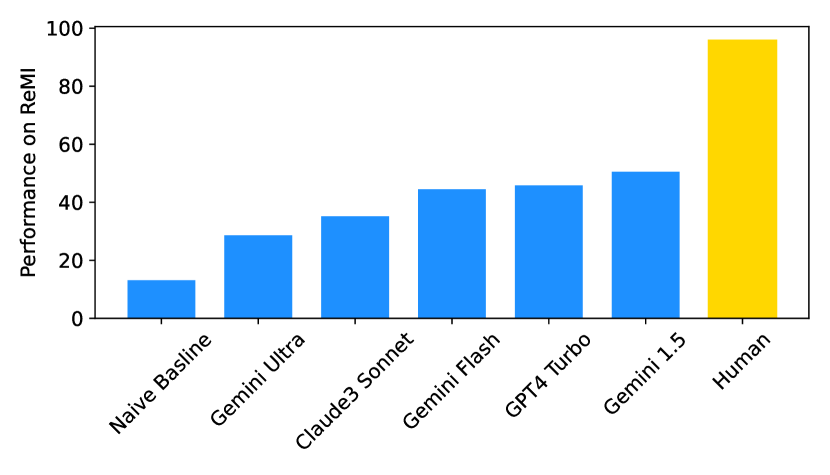
- 实验结果表明,现有LLM在ReMI数据集上的表现与人类水平存在显著差距,揭示了多图推理的挑战。
📝 摘要(中文)
随着大型语言模型(LLMs)的不断进步,创建新的基准来有效评估其不断扩展的能力并确定需要改进的领域至关重要。本文重点关注多图推理,这是当前最先进的LLM中涌现出的一种能力。我们推出了ReMI,一个旨在评估LLM多图推理能力的基准数据集。该数据集涵盖了广泛的任务,跨越了数学、物理、逻辑、代码、表格/图表理解以及空间和时间推理等各种推理领域。它还涵盖了多图推理场景中发现的各种特征。我们使用ReMI对几种最先进的LLM进行了基准测试,发现它们的性能与人类水平的熟练程度之间存在巨大差距。这突显了多图推理中的挑战以及进一步研究的必要性。我们的分析还揭示了不同模型的优势和劣势,阐明了当前可实现的推理类型以及未来模型需要改进的领域。为了促进该领域的进一步研究,我们将公开发布ReMI:https://huggingface.co/datasets/mehrankazemi/ReMI。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多图推理能力评估方面缺乏标准基准的问题。现有的LLMs虽然在单图或文本推理方面取得了显著进展,但在需要综合多张图片信息进行复杂推理的任务中表现仍然不足。缺乏一个全面、多样化的数据集来有效评估和指导LLMs在多图推理方面的改进。
核心思路:论文的核心思路是构建一个包含多种推理类型和场景的多图推理数据集ReMI。通过ReMI,可以系统地评估LLMs在不同推理任务上的表现,并识别其优势和劣势。这种方法旨在推动LLMs在多图推理方面的研究和发展。
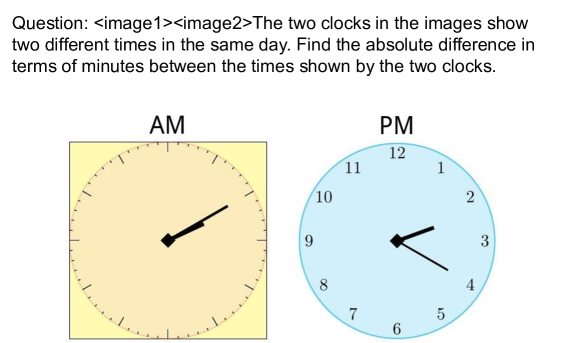
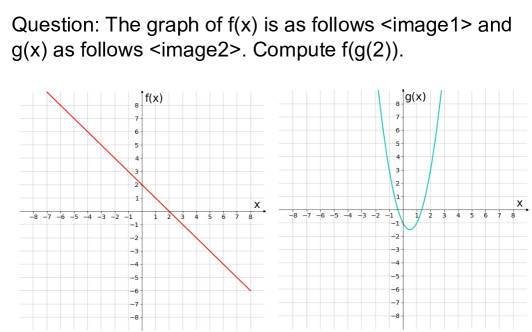
技术框架:ReMI数据集的构建流程主要包括以下几个阶段: 1. 任务定义:确定涵盖数学、物理、逻辑、代码、表格/图表理解、空间和时间推理等多种推理类型。 2. 数据收集与生成:收集或生成包含多张图片和对应推理问题的数据样本。 3. 数据标注与验证:对数据进行标注,并进行人工验证以确保数据质量。 4. 数据集发布:将数据集公开发布,供研究人员使用。
关键创新:ReMI数据集的关键创新在于其对多图推理任务的全面覆盖和多样性。它不仅包含常见的视觉推理任务,还涵盖了需要结合多种知识和推理能力的复杂场景,例如结合物理知识进行推理、理解代码逻辑等。这种多样性使得ReMI能够更全面地评估LLMs的多图推理能力。
关键设计:ReMI数据集包含多种类型的推理任务,每种任务都包含一定数量的样本。数据集的组织方式使得研究人员可以方便地选择特定类型的任务进行评估。此外,数据集还提供了评估指标,用于衡量LLMs在不同任务上的表现。具体的数据生成和标注细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文使用ReMI数据集对多个最先进的LLM进行了基准测试,结果表明这些模型在多图推理方面的性能与人类水平存在显著差距。具体性能数据和对比基线未在摘要中给出,属于未知信息。该结果突显了当前LLM在多图推理方面的不足,并为未来的研究方向提供了指导。
🎯 应用场景
ReMI数据集可应用于开发更强大的多模态人工智能系统,例如智能助手、自动驾驶和医疗诊断等领域。通过提升LLM的多图推理能力,可以使其更好地理解和处理复杂的多模态信息,从而在实际应用中发挥更大的作用。未来,ReMI可以作为评估和改进多模态模型的重要基准。
📄 摘要(原文)
With the continuous advancement of large language models (LLMs), it is essential to create new benchmarks to effectively evaluate their expanding capabilities and identify areas for improvement. This work focuses on multi-image reasoning, an emerging capability in state-of-the-art LLMs. We introduce ReMI, a dataset designed to assess LLMs' ability to Reason with Multiple Images. This dataset encompasses a diverse range of tasks, spanning various reasoning domains such as math, physics, logic, code, table/chart understanding, and spatial and temporal reasoning. It also covers a broad spectrum of characteristics found in multi-image reasoning scenarios. We have benchmarked several cutting-edge LLMs using ReMI and found a substantial gap between their performance and human-level proficiency. This highlights the challenges in multi-image reasoning and the need for further research. Our analysis also reveals the strengths and weaknesses of different models, shedding light on the types of reasoning that are currently attainable and areas where future models require improvement. To foster further research in this area, we are releasing ReMI publicly: https://huggingface.co/datasets/mehrankazemi/ReMI.