3D-AVS: LiDAR-based 3D Auto-Vocabulary Segmentation
作者: Weijie Wei, Osman Ülger, Fatemeh Karimi Nejadasl, Theo Gevers, Martin R. Oswald
分类: cs.CV
发布日期: 2024-06-13 (更新: 2025-03-30)
备注: v3 is the camera-ready version for CVPR 2025, while v2 serves as both a preview and the camera-ready version for the CVPR 2024 OpenSun3D Workshop
🔗 代码/项目: GITHUB
💡 一句话要点
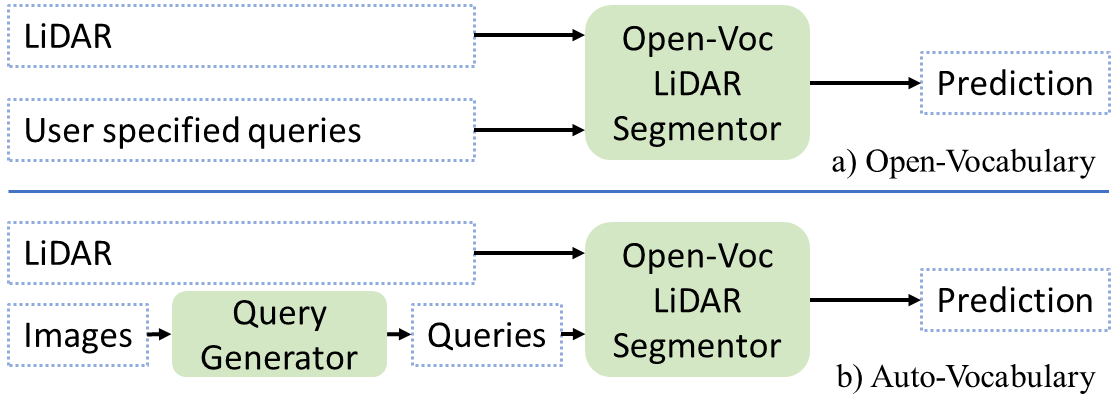
提出3D-AVS,实现无需人工干预的LiDAR点云自动词汇分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 点云分割 开放词汇分割 自动词汇生成 三维场景理解 LiDAR 语义分割 无监督学习
📋 核心要点
- 现有开放词汇分割方法依赖人工标注或文本提示,限制了其在实际场景中的可扩展性。
- 3D-AVS自动为每个输入生成词汇表,无需人工干预,并结合图像和点云信息提高鲁棒性。
- 引入无标注的TPSS指标评估生成词汇表的质量,并在nuScenes和ScanNet200上验证了有效性。
📝 摘要(中文)
开放词汇分割(OVS)方法在检测未见过的物体类别方面展现出潜力,但类别必须已知,并且需要人工提供,通过文本提示或预先标记的数据集,这限制了它们的可扩展性。我们提出3D-AVS,一种用于3D点云自动词汇分割的方法,其词汇表是未知的,并且为每个输入在运行时自动生成,从而消除了人工干预,并且通常为更丰富的注释提供更大的词汇表。3D-AVS首先从图像或点云数据中识别语义实体,然后使用自动生成的词汇表分割所有点。我们的方法结合了基于图像和基于点的识别,增强了在具有挑战性的光照条件下的鲁棒性,其中来自LiDAR的几何信息尤其有价值。我们的基于点的识别采用稀疏掩码注意力池化(SMAP)模块来丰富识别对象的多样性。为了解决评估未知词汇表的挑战,并避免来自标签同义词、层次结构或语义重叠的注释偏差,我们引入了无注释的文本-点语义相似度(TPSS)指标来评估生成的词汇表质量。我们在nuScenes和ScanNet200上的评估证明了3D-AVS生成具有准确点分割的语义类的能力。
🔬 方法详解
问题定义:现有开放词汇分割方法需要预定义的词汇表或人工提供的文本提示,这限制了它们在实际应用中的灵活性和可扩展性。尤其是在3D场景理解中,手动标注大规模点云数据集的语义类别既耗时又昂贵。因此,如何自动生成适用于特定场景的语义词汇表,并在此基础上进行点云分割,是一个亟待解决的问题。
核心思路:3D-AVS的核心思路是摆脱对预定义词汇表的依赖,通过分析输入数据(图像和点云)的内在结构,自动生成一个针对该场景的语义词汇表。然后,利用这个自动生成的词汇表对点云进行分割。这种方法的关键在于如何有效地从数据中提取语义信息,并将其转化为可用于分割的词汇表。
技术框架:3D-AVS的整体框架包含以下几个主要步骤:1) 语义实体识别:从图像和点云数据中识别出潜在的语义实体。该模块同时利用图像和点云信息,以提高识别的鲁棒性,尤其是在光照条件不佳的情况下。2) 词汇表生成:基于识别出的语义实体,自动生成一个针对该场景的词汇表。3) 点云分割:使用生成的词汇表对点云进行分割,将每个点分配到相应的语义类别。
关键创新:3D-AVS最重要的创新点在于其自动生成词汇表的能力。与传统的开放词汇分割方法相比,3D-AVS无需人工干预,可以根据输入数据自动调整词汇表,从而更好地适应不同的场景和任务。此外,提出的Sparse Masked Attention Pooling (SMAP)模块旨在丰富识别对象的种类,提升了识别的多样性。
关键设计:在点云识别方面,采用了Sparse Masked Attention Pooling (SMAP)模块,该模块的具体结构和参数设置未知。为了评估自动生成的词汇表的质量,论文提出了Text-Point Semantic Similarity (TPSS)指标,该指标无需人工标注,通过计算文本和点云之间的语义相似度来评估词汇表的准确性。TPSS指标的具体计算方法未知。
🖼️ 关键图片


📊 实验亮点
3D-AVS在nuScenes和ScanNet200数据集上进行了评估,证明了其生成具有准确点分割的语义类的能力。虽然论文中没有给出具体的性能数据和对比基线,但强调了该方法能够自动生成高质量的词汇表,并实现准确的点云分割。提出的TPSS指标为评估自动生成的词汇表提供了一种新的方法。
🎯 应用场景
3D-AVS在自动驾驶、机器人导航、三维场景理解等领域具有广泛的应用前景。它可以用于自动生成场景的语义地图,帮助自动驾驶车辆理解周围环境,或者帮助机器人在未知环境中进行导航和操作。此外,该方法还可以应用于城市规划、建筑设计等领域,为三维场景的分析和理解提供更高效的工具。
📄 摘要(原文)
Open-Vocabulary Segmentation (OVS) methods offer promising capabilities in detecting unseen object categories, but the category must be known and needs to be provided by a human, either via a text prompt or pre-labeled datasets, thus limiting their scalability. We propose 3D-AVS, a method for Auto-Vocabulary Segmentation of 3D point clouds for which the vocabulary is unknown and auto-generated for each input at runtime, thus eliminating the human in the loop and typically providing a substantially larger vocabulary for richer annotations. 3D-AVS first recognizes semantic entities from image or point cloud data and then segments all points with the automatically generated vocabulary. Our method incorporates both image-based and point-based recognition, enhancing robustness under challenging lighting conditions where geometric information from LiDAR is especially valuable. Our point-based recognition features a Sparse Masked Attention Pooling (SMAP) module to enrich the diversity of recognized objects. To address the challenges of evaluating unknown vocabularies and avoid annotation biases from label synonyms, hierarchies, or semantic overlaps, we introduce the annotation-free Text-Point Semantic Similarity (TPSS) metric for assessing generated vocabulary quality. Our evaluations on nuScenes and ScanNet200 demonstrate 3D-AVS's ability to generate semantic classes with accurate point-wise segmentations. Codes will be released at https://github.com/ozzyou/3D-AVS