Dual Attribute-Spatial Relation Alignment for 3D Visual Grounding
作者: Yue Xu, Kaizhi Yang, Jiebo Luo, Xuejin Chen
分类: cs.CV, cs.MM
发布日期: 2024-06-13
💡 一句话要点
提出DASANet,通过双分支对齐属性-空间关系特征实现更精准的3D视觉定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 视觉语言 属性关系 空间关系 注意力机制 点云处理 跨模态对齐
📋 核心要点
- 现有3D视觉定位方法难以有效建模和对齐语言与3D场景中的属性和空间关系。
- DASANet通过双分支结构分别建模和对齐对象属性和空间关系,并利用交叉注意力融合全局上下文。
- 实验表明,DASANet在Nr3D数据集上取得了领先的定位精度,并具有良好的可解释性。
📝 摘要(中文)
本文针对3D视觉定位这一新兴研究领域,旨在建立3D物理世界与自然语言之间的联系,这对于实现具身智能至关重要。我们提出了DASANet,一个双重属性-空间关系对齐网络,它分别建模和对齐语言和3D视觉模态之间的对象属性和空间关系特征。我们将语言和3D点云输入分解为两个独立的部分,并设计了一个双分支注意力模块来分别建模分解后的输入,同时通过交叉注意力在属性-空间特征融合中保留全局上下文。我们的DASANet在Nr3D数据集上实现了65.1%的最高定位精度,比最佳竞争对手高出1.3%。此外,两个分支的可视化证明了我们的方法是高效且高度可解释的。
🔬 方法详解
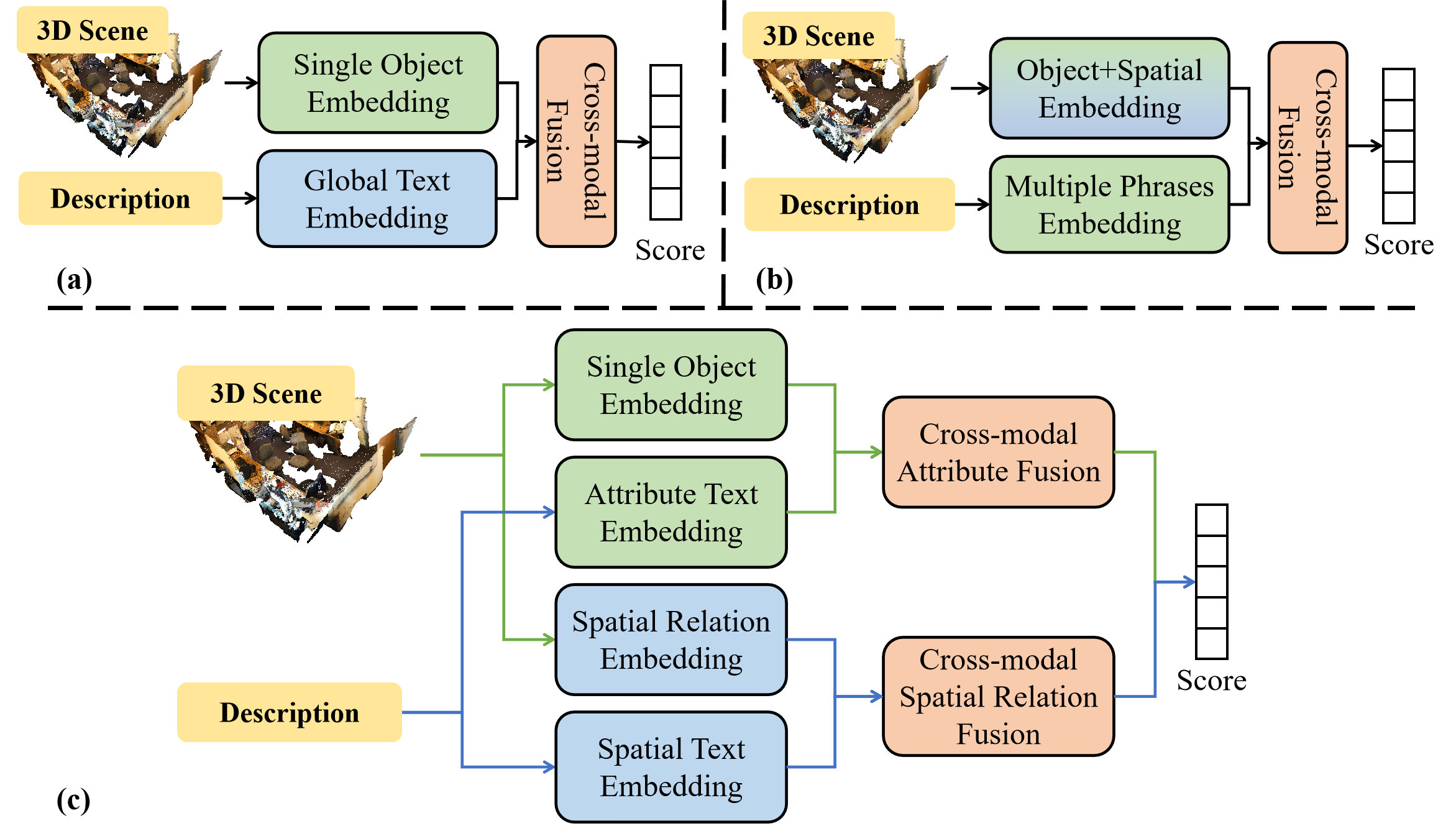
问题定义:3D视觉定位旨在根据自然语言描述在3D场景中找到对应的目标物体。现有方法通常难以有效区分和对齐语言描述中的属性信息(如颜色、材质)和空间关系信息(如方位、距离),导致定位精度受限。现有方法的痛点在于无法充分利用属性和空间关系这两种关键信息,并且缺乏对它们之间关系的有效建模。
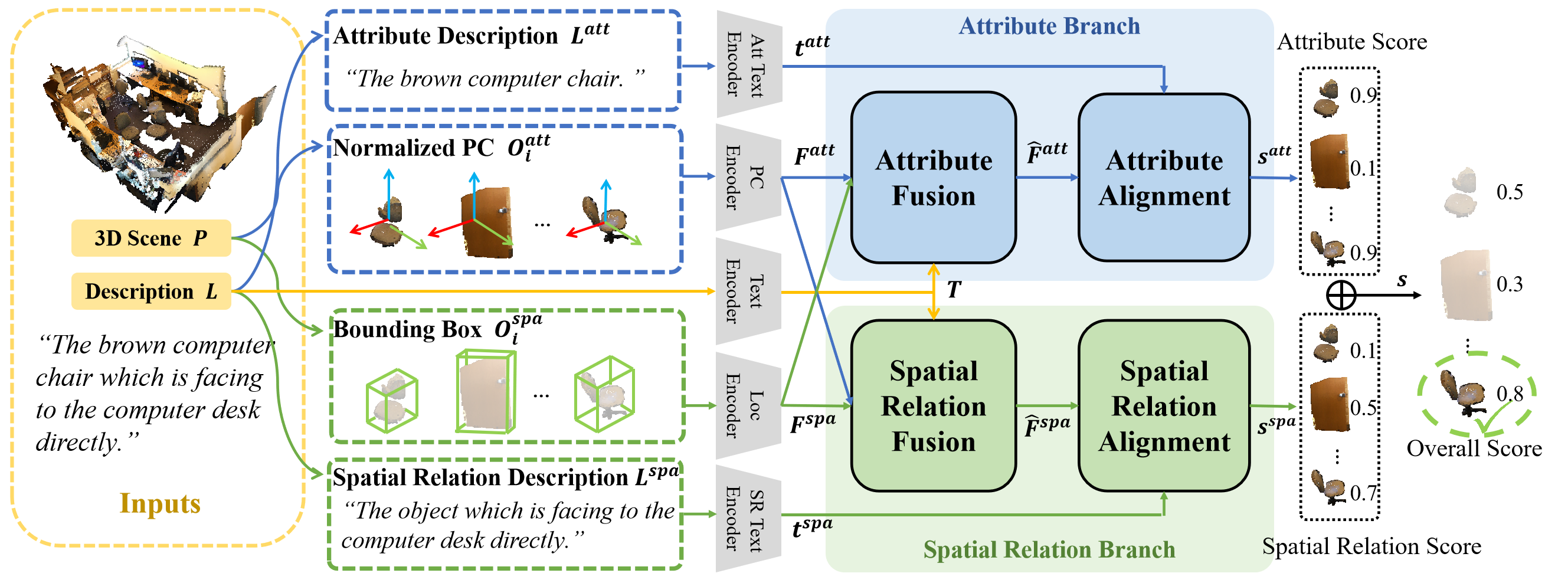
核心思路:DASANet的核心思路是将语言和3D点云输入都分解为属性和空间关系两个分支,然后分别对这两个分支进行建模和对齐。通过这种方式,可以更有效地捕捉和利用属性和空间关系信息,从而提高定位精度。同时,使用交叉注意力机制来融合两个分支的信息,保留全局上下文。
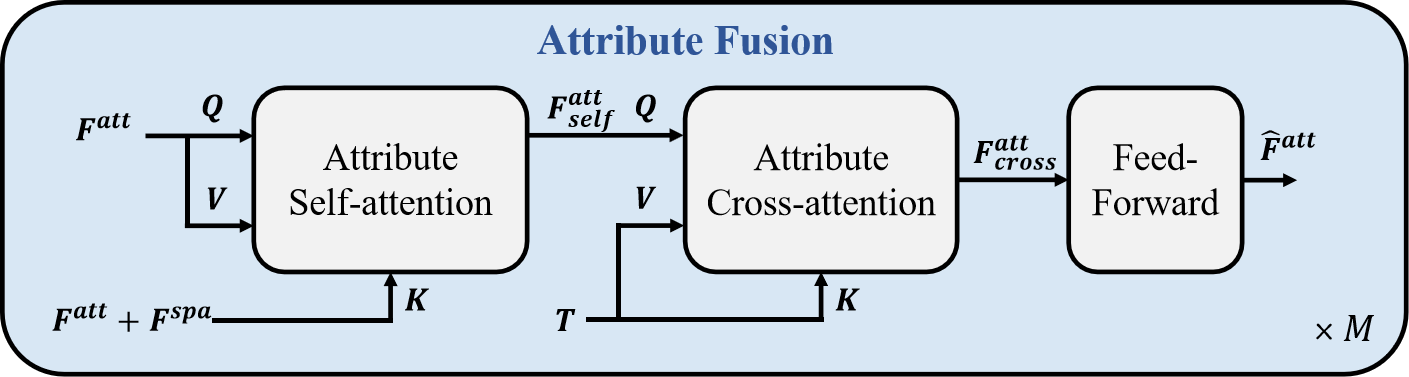
技术框架:DASANet的整体架构包含以下几个主要模块:1) 输入分解模块:将语言描述和3D点云数据分别分解为属性分支和空间关系分支。2) 双分支注意力模块:分别对属性分支和空间关系分支进行建模,提取特征。3) 交叉注意力融合模块:利用交叉注意力机制融合两个分支的特征,保留全局上下文信息。4) 定位预测模块:根据融合后的特征预测目标物体的位置。
关键创新:DASANet的关键创新在于双分支属性-空间关系对齐网络结构。与现有方法相比,DASANet能够更有效地建模和对齐语言和3D场景中的属性和空间关系信息。通过将输入分解为两个分支,并分别进行建模,可以更好地捕捉和利用这两种关键信息。此外,交叉注意力机制的使用也增强了模型对全局上下文的理解。
关键设计:DASANet的关键设计包括:1) 使用预训练的语言模型(如BERT)提取语言特征。2) 使用PointNet++提取3D点云特征。3) 设计了专门的注意力机制来建模属性和空间关系分支。4) 使用交叉熵损失函数来训练模型。
🖼️ 关键图片
📊 实验亮点
DASANet在Nr3D数据集上取得了显著的性能提升,定位精度达到65.1%,比当前最佳方法高出1.3%。消融实验验证了双分支结构和交叉注意力机制的有效性。可视化结果表明,该模型能够准确地关注到与语言描述相关的属性和空间关系区域,具有良好的可解释性。
🎯 应用场景
3D视觉定位技术在机器人导航、增强现实、智能家居等领域具有广泛的应用前景。例如,机器人可以根据用户的语音指令在室内环境中找到指定的物体;增强现实应用可以将虚拟物体放置在真实场景中的特定位置。该研究成果有助于提升这些应用的用户体验和智能化水平,并为未来的具身智能发展奠定基础。
📄 摘要(原文)
3D visual grounding is an emerging research area dedicated to making connections between the 3D physical world and natural language, which is crucial for achieving embodied intelligence. In this paper, we propose DASANet, a Dual Attribute-Spatial relation Alignment Network that separately models and aligns object attributes and spatial relation features between language and 3D vision modalities. We decompose both the language and 3D point cloud input into two separate parts and design a dual-branch attention module to separately model the decomposed inputs while preserving global context in attribute-spatial feature fusion by cross attentions. Our DASANet achieves the highest grounding accuracy 65.1% on the Nr3D dataset, 1.3% higher than the best competitor. Besides, the visualization of the two branches proves that our method is efficient and highly interpretable.