Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models
作者: Yi-Fan Zhang, Qingsong Wen, Chaoyou Fu, Xue Wang, Zhang Zhang, Liang Wang, Rong Jin
分类: cs.CV
发布日期: 2024-06-12 (更新: 2024-06-14)
备注: Project page: https://github.com/yfzhang114/SliME
💡 一句话要点
SliME:面向高分辨率图像,通过局部压缩和全局专家混合提升多模态大模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 高分辨率图像 局部图像压缩 全局专家混合 交替训练 视觉问答 图像理解
📋 核心要点
- 现有LMM在高分辨率图像处理中,直接提升分辨率导致计算量巨大,且局部信息可能淹没全局上下文。
- SliME通过混合全局专家提取上下文,并使用可学习查询嵌入和相似性选择器压缩局部图像token。
- SliME采用交替训练策略平衡全局和局部学习,并在新数据集上训练,仅用200万数据即取得领先性能。
📝 摘要(中文)
本文深入研究了高分辨率对大型多模态模型(LMMs)的重要性。现有方法通常采用直接的分辨率提升策略,将图像分为全局和局部分支,局部图像块被调整到与全局视图相同的分辨率。这种方法在高分辨率下计算成本过高,且局部图像token的优势可能会削弱全局上下文。为此,我们提出了一个新框架和精细的优化策略。具体而言,我们基于不同适配器擅长不同任务的观察,使用混合适配器从全局视图中提取上下文信息。对于局部图像块,引入可学习的查询嵌入来减少图像token,并通过基于相似性的选择器进一步选择对用户问题最重要的token。实验结果表明,利用更少但信息量更大的局部图像token可以提高性能。此外,全局挖掘块和局部压缩块的同时端到端训练无法产生最佳结果,因此我们提倡交替训练方式,以确保全局和局部方面的平衡学习。最后,我们还引入了一个对图像细节有很高要求的具有挑战性的数据集,以增强局部压缩层的训练。所提出的方法,称为具有复杂任务、局部图像压缩和全局专家混合的LMM(SliME),仅使用200万训练数据就在各种基准测试中实现了领先的性能。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在处理高分辨率图像时面临计算效率和信息冗余的挑战。简单地将图像切分成多个局部patches并调整到相同分辨率,会导致计算量随着分辨率的提高而急剧增加。此外,大量的局部图像token可能会削弱全局上下文信息的表达,影响模型的整体性能。
核心思路:SliME的核心思路是“少即是多”,即利用更少但更具信息量的局部图像token来提升模型性能。通过全局专家混合提取全局上下文信息,并采用局部图像压缩技术减少token数量,从而在保证模型性能的同时降低计算成本。
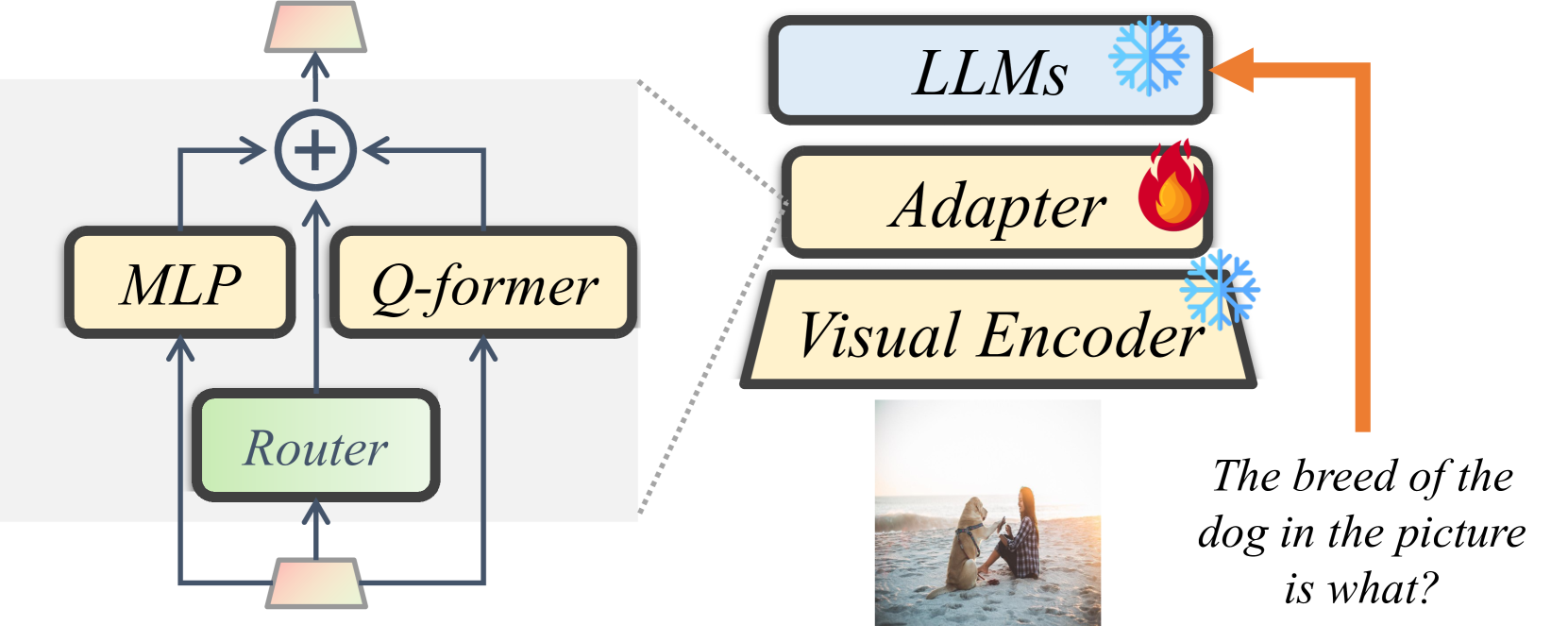
技术框架:SliME框架主要包含三个关键模块:全局专家混合模块、局部图像压缩模块和交替训练策略。全局专家混合模块利用多个适配器(adapters)从全局图像中提取上下文信息,每个适配器专注于不同的任务。局部图像压缩模块通过可学习的查询嵌入(query embeddings)减少图像token,并使用基于相似性的选择器(similarity-based selector)选择与用户问题最相关的token。交替训练策略则用于平衡全局和局部模块的学习。
关键创新:SliME的关键创新在于其局部图像压缩策略和全局专家混合机制。局部图像压缩策略通过可学习的查询嵌入和相似性选择器,有效地减少了局部图像token的数量,同时保留了关键信息。全局专家混合机制则利用多个适配器从全局图像中提取更丰富的上下文信息。此外,交替训练策略也保证了全局和局部模块的协同优化。
关键设计:在全局专家混合模块中,适配器的选择和组合方式是关键。论文可能采用了某种门控机制或注意力机制来动态地选择和组合不同的适配器。在局部图像压缩模块中,查询嵌入的初始化方式和相似性选择器的阈值设置是重要参数。此外,交替训练的轮数和学习率也需要仔细调整,以保证模型的收敛性和性能。
🖼️ 关键图片
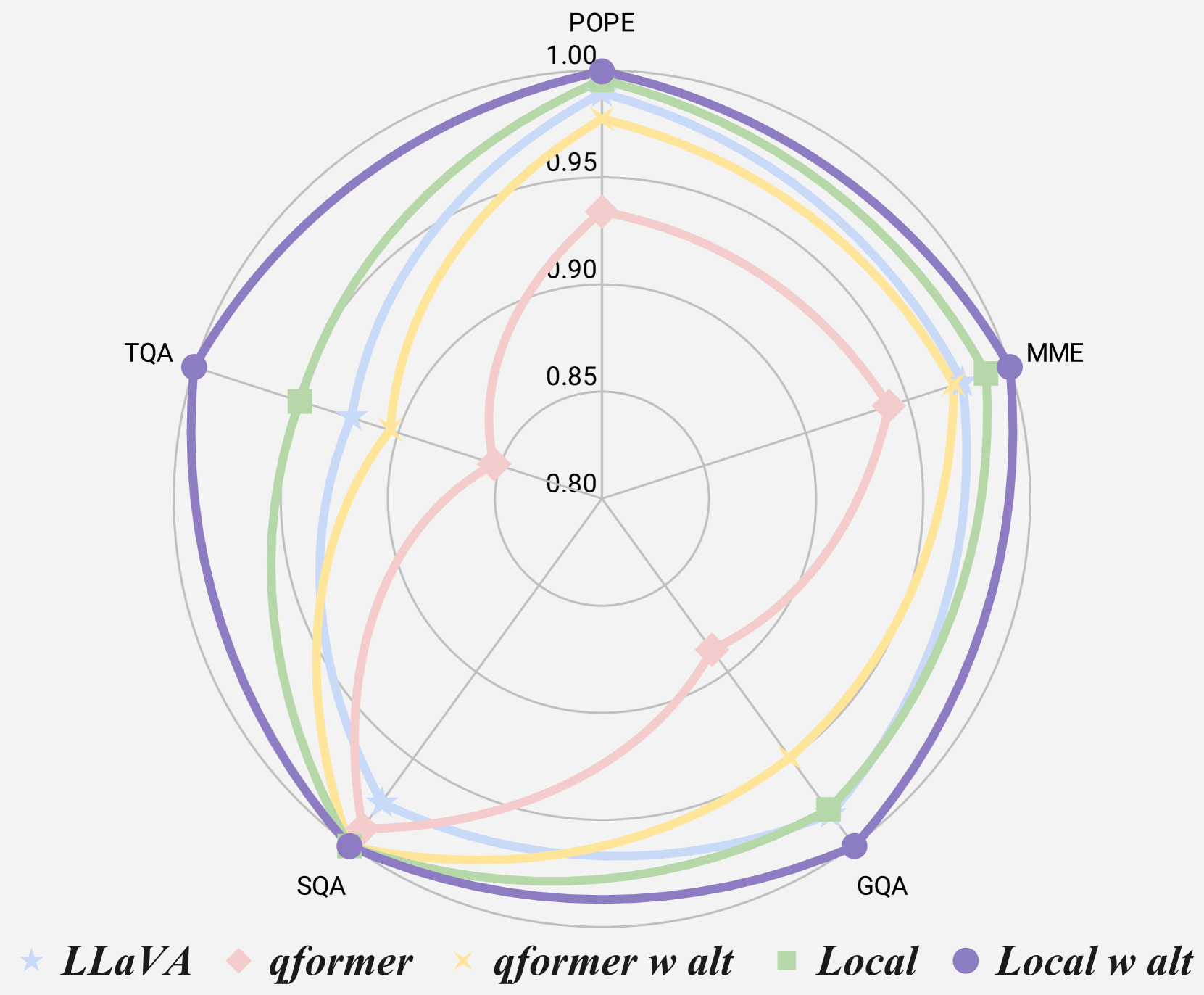

📊 实验亮点
SliME在多个基准测试中取得了领先的性能,证明了其在高分辨率图像处理方面的有效性。值得注意的是,SliME仅使用200万训练数据就达到了优异的性能,表明其具有很高的训练效率。实验结果验证了“少即是多”的理念,即利用更少但更具信息量的局部图像token可以显著提升模型性能。
🎯 应用场景
SliME具有广泛的应用前景,例如在高分辨率医学图像分析中,可以帮助医生更准确地诊断疾病;在遥感图像处理中,可以用于更精细的地物识别和变化检测;在自动驾驶领域,可以提升车辆对复杂环境的感知能力。该研究有助于推动多模态大模型在需要处理高分辨率图像的实际场景中的应用。
📄 摘要(原文)
Seeing clearly with high resolution is a foundation of Large Multimodal Models (LMMs), which has been proven to be vital for visual perception and reasoning. Existing works usually employ a straightforward resolution upscaling method, where the image consists of global and local branches, with the latter being the sliced image patches but resized to the same resolution as the former. This means that higher resolution requires more local patches, resulting in exorbitant computational expenses, and meanwhile, the dominance of local image tokens may diminish the global context. In this paper, we dive into the problems and propose a new framework as well as an elaborate optimization strategy. Specifically, we extract contextual information from the global view using a mixture of adapters, based on the observation that different adapters excel at different tasks. With regard to local patches, learnable query embeddings are introduced to reduce image tokens, the most important tokens accounting for the user question will be further selected by a similarity-based selector. Our empirical results demonstrate a `less is more' pattern, where \textit{utilizing fewer but more informative local image tokens leads to improved performance}. Besides, a significant challenge lies in the training strategy, as simultaneous end-to-end training of the global mining block and local compression block does not yield optimal results. We thus advocate for an alternating training way, ensuring balanced learning between global and local aspects. Finally, we also introduce a challenging dataset with high requirements for image detail, enhancing the training of the local compression layer. The proposed method, termed LMM with Sophisticated Tasks, Local image compression, and Mixture of global Experts (SliME), achieves leading performance across various benchmarks with only 2 million training data.