OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
作者: Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, Jiashuo Yu, Hao Tian, Jiasheng Zhou, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Zhenxiang Li, Pei Chu, Yi Wang, Min Dou, Changyao Tian, Xizhou Zhu, Lewei Lu, Yushi Chen, Junjun He, Zhongying Tu, Tong Lu, Yali Wang, Limin Wang, Dahua Lin, Yu Qiao, Botian Shi, Conghui He, Jifeng Dai
分类: cs.CV, cs.AI
发布日期: 2024-06-12 (更新: 2024-07-12)
🔗 代码/项目: GITHUB
💡 一句话要点
提出OmniCorpus,一个包含百亿级图像与文本交错的大规模多模态数据集,促进多模态大语言模型发展。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图像文本交错 大规模数据集 多模态大语言模型 数据引擎
📋 核心要点
- 现有图像-文本交错数据集规模和多样性不足,限制了多模态大语言模型的发展。
- OmniCorpus通过高效数据引擎,从多样化来源过滤和提取大规模高质量的图像-文本交错文档。
- 实验验证了OmniCorpus数据集的质量、可用性和有效性,为多模态模型研究提供数据基础。
📝 摘要(中文)
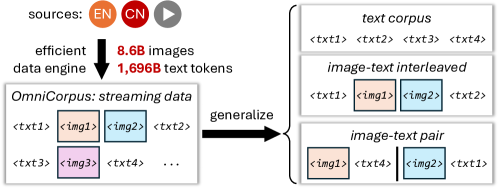
本文介绍OmniCorpus,一个包含百亿级别图像-文本交错的数据集。图像-文本交错数据以自然文档格式排列,符合互联网数据的呈现范式,并且与人类的阅读习惯非常相似。最近的研究表明,这种数据有助于多模态上下文学习,并在多模态微调期间保持大型语言模型的能力。然而,当前图像-文本交错数据的有限规模和多样性限制了多模态大型语言模型的发展。OmniCorpus使用高效的数据引擎过滤和提取大规模高质量文档,其中包含86亿张图像和16960亿个文本token。与同类数据集(例如MMC4、OBELICS)相比,我们的数据集1)规模扩大了15倍,同时保持了良好的数据质量;2)具有更多样化的来源,包括英语和非英语网站以及以视频为中心的网站;3)更加灵活,可以轻松地从图像-文本交错格式降级为纯文本语料库和图像-文本对。通过全面的分析和实验,我们验证了所提出数据集的质量、可用性和有效性。我们希望这能为未来的多模态模型研究提供坚实的数据基础。
🔬 方法详解
问题定义:现有图像-文本交错数据集的规模和多样性不足,无法满足训练高性能多模态大语言模型的需求。这些数据集通常规模较小,来源单一,限制了模型学习能力和泛化能力。现有方法难以有效处理大规模、多样化的互联网数据,并从中提取高质量的图像-文本交错数据。
核心思路:OmniCorpus的核心思路是构建一个大规模、高质量、多样化的图像-文本交错数据集,以促进多模态大语言模型的发展。通过设计高效的数据引擎,从互联网上抓取并过滤大规模数据,并进行清洗和处理,最终得到高质量的图像-文本交错数据。这种方法旨在解决现有数据集规模小、多样性不足的问题,为多模态模型提供更丰富、更全面的训练数据。
技术框架:OmniCorpus的构建流程主要包括以下几个阶段:1) 数据抓取:从互联网上抓取大规模的网页和文档数据,包括英文和非英文网站,以及视频网站。2) 数据过滤:使用一系列规则和模型对抓取的数据进行过滤,去除低质量、重复或不相关的数据。3) 数据清洗:对过滤后的数据进行清洗和处理,包括文本去噪、图像处理等。4) 数据组织:将清洗后的图像和文本数据组织成图像-文本交错的格式,并进行索引和存储。
关键创新:OmniCorpus的关键创新在于其数据集的规模和多样性。与现有数据集相比,OmniCorpus的规模扩大了15倍,并且包含了更多样化的数据来源,包括英文和非英文网站,以及视频网站。此外,OmniCorpus还具有更灵活的数据格式,可以轻松地从图像-文本交错格式降级为纯文本语料库和图像-文本对。
关键设计:OmniCorpus的数据引擎采用了多种技术来提高数据质量和效率。例如,使用基于规则和模型的过滤方法来去除低质量数据,使用高效的文本去噪算法来清洗文本数据,使用图像质量评估模型来筛选高质量图像。此外,OmniCorpus还采用了分布式存储和计算技术来处理大规模数据。
🖼️ 关键图片

📊 实验亮点
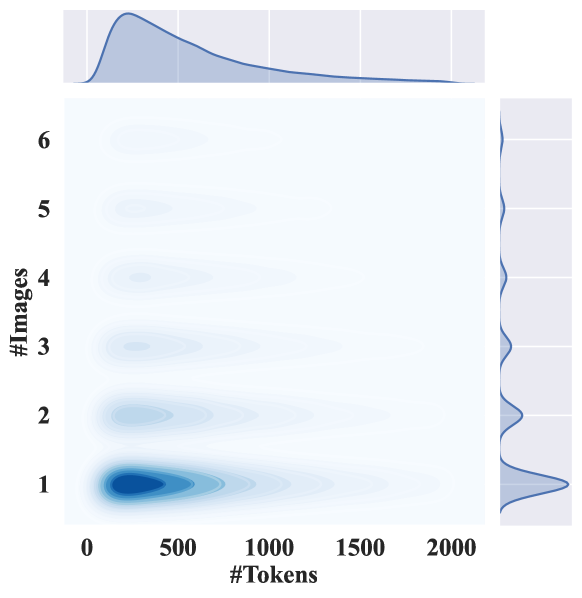
OmniCorpus数据集规模达到100亿级别,包含86亿张图像和16960亿个文本token,是现有同类数据集(如MMC4、OBELICS)的15倍。该数据集具有更广泛的数据来源,包括英文和非英文网站以及视频网站,保证了数据的多样性。实验验证了OmniCorpus数据集的质量、可用性和有效性,为多模态模型研究提供了坚实的数据基础。
🎯 应用场景
OmniCorpus数据集可广泛应用于多模态大语言模型的预训练和微调,提升模型在图像描述、视觉问答、多模态推理等任务上的性能。该数据集也可用于研究多模态上下文学习、跨语言理解等前沿问题,推动多模态人工智能的发展。此外,该数据集还可应用于搜索引擎、推荐系统等领域,提升用户体验。
📄 摘要(原文)
Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.