VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
作者: Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Zhe Chen, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, Ping Luo, Yu Qiao, Jifeng Dai
分类: cs.CV
发布日期: 2024-06-12 (更新: 2024-12-31)
备注: 44 pages
💡 一句话要点
VisionLLM v2:提出通用多模态大语言模型,统一视觉感知、理解和生成任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉语言任务 端到端训练 多任务学习 超级链接 视觉感知 图像生成 目标定位
📋 核心要点
- 现有MLLM通常局限于文本输出,限制了其在更广泛视觉任务中的应用,例如目标定位和图像编辑。
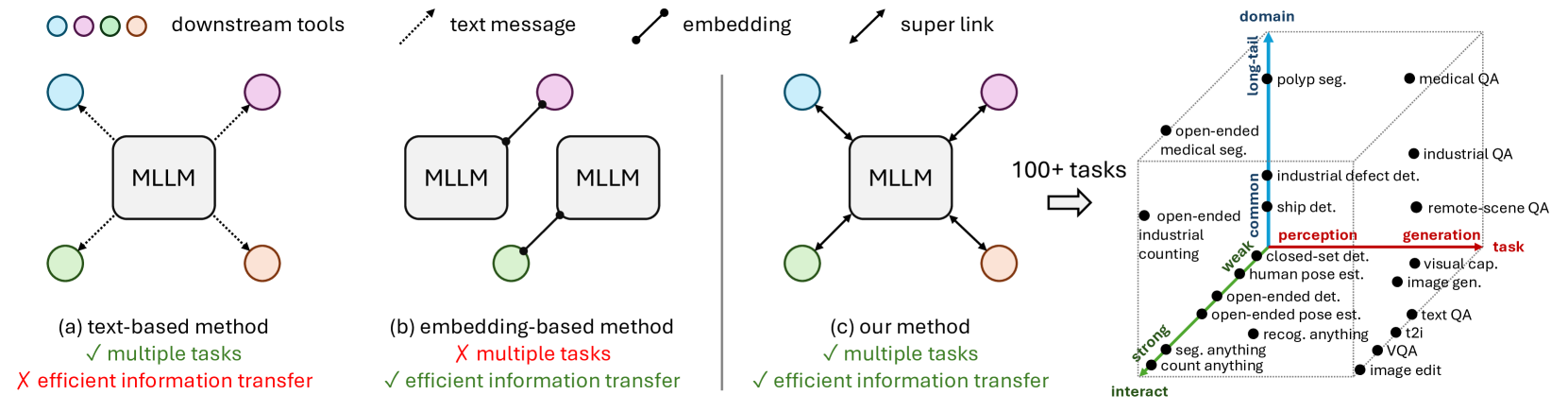
- VisionLLM v2 提出“超级链接”机制,连接MLLM与特定任务解码器,实现任务信息和梯度反馈的灵活传输。
- 通过在数百个视觉语言任务上进行端到端联合训练,VisionLLM v2 在各种任务上实现了与特定任务模型相当的性能。
📝 摘要(中文)
本文提出了VisionLLM v2,一个端到端的通用多模态大语言模型(MLLM),它在一个统一的框架内集成了视觉感知、理解和生成。与传统MLLM仅限于文本输出不同,VisionLLM v2显著扩展了其应用范围。它不仅擅长传统的视觉问答(VQA),而且擅长开放域、跨领域的视觉任务,如目标定位、姿态估计以及图像生成和编辑。为此,我们提出了一种新的信息传输机制,称为“超级链接”,作为连接MLLM与特定任务解码器的媒介。它不仅允许MLLM和多个下游解码器之间灵活地传输任务信息和梯度反馈,而且有效地解决了多任务场景中的训练冲突。此外,为了支持各种各样的任务,我们仔细收集和梳理了来自数百个公共视觉和视觉语言任务的训练数据。通过这种方式,我们的模型可以在数百个视觉语言任务上进行端到端的联合训练,并通过不同的用户提示使用一组共享参数泛化到这些任务,从而达到与特定任务模型相当的性能。我们相信VisionLLM v2将为MLLM的泛化提供一个新的视角。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)通常只能输出文本,无法直接应用于需要视觉输出的任务,例如目标定位、姿态估计和图像生成/编辑。此外,在多任务学习场景下,不同任务之间容易产生训练冲突,影响模型性能。
核心思路:VisionLLM v2 的核心思路是构建一个端到端的通用 MLLM,通过引入“超级链接”机制,将 MLLM 与特定任务的解码器连接起来,从而实现视觉感知、理解和生成任务的统一。这种设计允许模型灵活地处理各种视觉任务,并有效地解决多任务学习中的训练冲突。
技术框架:VisionLLM v2 的整体架构包含一个 MLLM 主干网络和多个特定任务的解码器。MLLM 负责处理输入图像和文本信息,提取视觉特征和语义信息。“超级链接”作为信息传输的桥梁,将 MLLM 的输出传递给相应的解码器。每个解码器负责完成特定的视觉任务,例如目标检测、姿态估计或图像生成。整个模型采用端到端的方式进行训练。
关键创新:VisionLLM v2 最重要的技术创新点在于“超级链接”机制。它允许任务信息和梯度反馈在 MLLM 和多个下游解码器之间灵活传输,从而有效地解决了多任务场景中的训练冲突。与传统的多任务学习方法相比,VisionLLM v2 能够更好地共享参数,提高模型的泛化能力。
关键设计:在训练过程中,VisionLLM v2 采用了大量的视觉和视觉语言数据,涵盖了数百个不同的任务。为了平衡不同任务之间的学习进度,论文可能采用了某种形式的动态权重调整策略。此外,解码器的具体结构根据任务的不同而有所差异,例如,目标检测解码器可能采用 Faster R-CNN 的结构,而图像生成解码器可能采用 GAN 或扩散模型的结构。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
VisionLLM v2 在多个视觉和视觉语言任务上取得了与特定任务模型相当的性能。通过在数百个任务上进行联合训练,该模型展现了强大的泛化能力。具体的性能数据和对比基线在论文中进行了详细的展示,但此处未知。
🎯 应用场景
VisionLLM v2 具有广泛的应用前景,例如智能助手、自动驾驶、机器人等领域。它可以用于处理各种视觉任务,例如视觉问答、目标检测、图像编辑等。该研究有助于推动通用人工智能的发展,使机器能够像人类一样理解和处理视觉信息。
📄 摘要(原文)
We present VisionLLM v2, an end-to-end generalist multimodal large model (MLLM) that unifies visual perception, understanding, and generation within a single framework. Unlike traditional MLLMs limited to text output, VisionLLM v2 significantly broadens its application scope. It excels not only in conventional visual question answering (VQA) but also in open-ended, cross-domain vision tasks such as object localization, pose estimation, and image generation and editing. To this end, we propose a new information transmission mechanism termed "super link", as a medium to connect MLLM with task-specific decoders. It not only allows flexible transmission of task information and gradient feedback between the MLLM and multiple downstream decoders but also effectively resolves training conflicts in multi-tasking scenarios. In addition, to support the diverse range of tasks, we carefully collected and combed training data from hundreds of public vision and vision-language tasks. In this way, our model can be joint-trained end-to-end on hundreds of vision language tasks and generalize to these tasks using a set of shared parameters through different user prompts, achieving performance comparable to task-specific models. We believe VisionLLM v2 will offer a new perspective on the generalization of MLLMs.