Visual Representation Learning with Stochastic Frame Prediction
作者: Huiwon Jang, Dongyoung Kim, Junsu Kim, Jinwoo Shin, Pieter Abbeel, Younggyo Seo
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2024-06-11 (更新: 2024-08-08)
备注: International Conference on Machine Learning (ICML) 2024
💡 一句话要点
提出基于随机帧预测的视觉表征学习框架,提升视频理解和机器人学习任务性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 视觉表征学习 随机帧预测 掩码图像建模 视频理解
📋 核心要点
- 帧预测具有不确定性,单一帧可能对应多个未来帧,这给自监督图像表征学习带来了挑战。
- 论文提出训练随机帧预测模型,捕捉帧预测中的不确定性,并将其用于表征学习,提升模型泛化能力。
- 引入掩码图像建模作为辅助目标,结合共享解码器架构,协同学习帧间时间信息和帧内密集信息。
📝 摘要(中文)
本文提出了一种基于随机帧预测的自监督图像表征学习方法,旨在解决帧预测的不确定性问题。该方法通过训练一个随机帧预测模型来学习帧之间的时间信息,并引入辅助的掩码图像建模目标,结合共享解码器架构,以学习帧内的密集信息。这种架构能够以协同且计算高效的方式结合两个目标。实验结果表明,该框架在视频标签传播和基于视觉的机器人学习等多种任务中表现出色,包括视频分割、姿态跟踪、基于视觉的机器人运动和操作任务。
🔬 方法详解
问题定义:现有基于帧预测的自监督学习方法面临着帧预测不确定性的挑战。由于单个当前帧可能对应多个可能的未来帧,传统的确定性预测方法难以有效地学习到鲁棒的图像表征,限制了其在复杂场景下的应用。
核心思路:论文的核心思路是利用随机视频生成模型来捕捉帧预测中的不确定性。通过学习预测未来帧的概率分布,而不是单一的未来帧,模型能够更好地理解视频中的潜在变化和多种可能性,从而学习到更具泛化能力的图像表征。
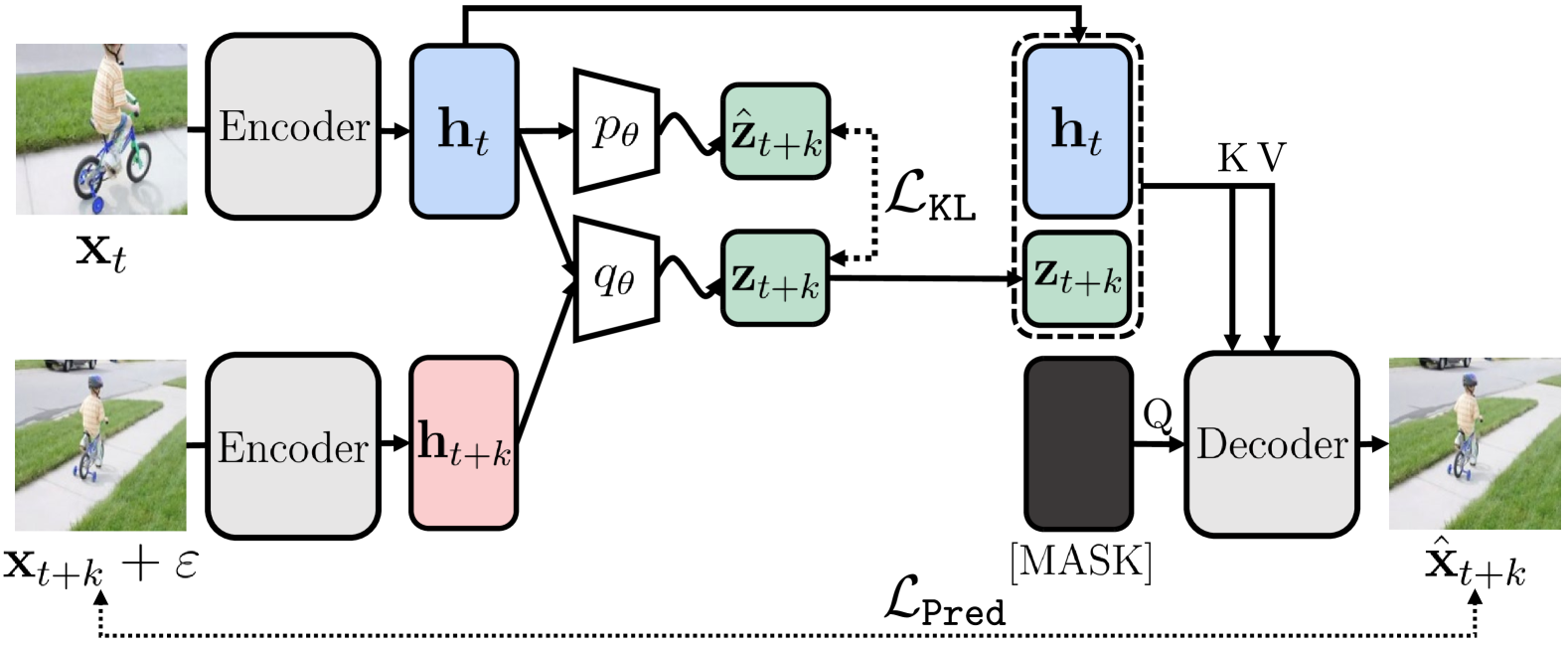
技术框架:该框架包含一个随机帧预测模型和一个辅助的掩码图像建模模块。随机帧预测模型负责学习帧之间的时间信息,通过编码器-解码器结构预测未来帧的概率分布。掩码图像建模模块则通过预测被遮挡的图像区域来学习帧内的密集信息。两个模块共享解码器架构,实现协同训练。整体流程为:输入当前帧,通过编码器提取特征,然后分别输入到随机帧预测解码器和掩码图像建模解码器,最后通过相应的损失函数进行优化。
关键创新:该方法最重要的创新点在于将随机帧预测与掩码图像建模相结合,并采用共享解码器架构。随机帧预测能够捕捉时间维度上的不确定性,而掩码图像建模能够学习空间维度上的密集信息。共享解码器架构使得两个目标能够以协同且计算高效的方式进行学习,避免了模型参数的冗余。
关键设计:随机帧预测模型采用变分自编码器(VAE)结构,通过学习隐变量的分布来捕捉未来帧的不确定性。掩码图像建模采用随机遮挡策略,遮挡部分图像区域,然后训练模型预测被遮挡区域的内容。损失函数包括随机帧预测的重构损失和KL散度损失,以及掩码图像建模的重构损失。具体的网络结构和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
论文在视频分割、姿态跟踪、机器人运动和操作等多个任务上进行了实验验证。实验结果表明,该方法在这些任务上均取得了显著的性能提升,证明了其有效性。具体的性能数据和对比基线在论文中有详细描述,但此处未知。
🎯 应用场景
该研究成果可应用于视频理解、机器人学习等领域。例如,可以用于视频监控中的异常行为检测、自动驾驶中的场景理解和预测、机器人操作中的视觉伺服控制等。通过学习更鲁棒的图像表征,可以提升这些应用在复杂环境下的性能和可靠性,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Self-supervised learning of image representations by predicting future frames is a promising direction but still remains a challenge. This is because of the under-determined nature of frame prediction; multiple potential futures can arise from a single current frame. To tackle this challenge, in this paper, we revisit the idea of stochastic video generation that learns to capture uncertainty in frame prediction and explore its effectiveness for representation learning. Specifically, we design a framework that trains a stochastic frame prediction model to learn temporal information between frames. Moreover, to learn dense information within each frame, we introduce an auxiliary masked image modeling objective along with a shared decoder architecture. We find this architecture allows for combining both objectives in a synergistic and compute-efficient manner. We demonstrate the effectiveness of our framework on a variety of tasks from video label propagation and vision-based robot learning domains, such as video segmentation, pose tracking, vision-based robotic locomotion, and manipulation tasks. Code is available on the project webpage: https://sites.google.com/view/2024rsp.