Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
作者: Bowen Dang, Xi Zhao
分类: cs.CV, cs.GR
发布日期: 2024-06-09
备注: The 37th International Conference on Computer Animation and Social Agents (CASA 2024)
💡 一句话要点
提出解耦结构的场景中多样化3D人体姿态生成方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 3D人体姿态生成 场景交互 解耦结构 姿态先验 接触先验
📋 核心要点
- 现有方法依赖人-场景交互数据集,导致生成的人体姿态多样性受限,难以满足实际需求。
- 论文提出解耦姿态和交互生成过程,分别学习姿态先验和接触先验,再将人体自然地放入场景。
- 实验结果表明,该方法能生成更符合物理规律的交互,并展现出更丰富多样的人体姿态。
📝 摘要(中文)
本文提出了一种在场景中生成具有语义控制的多样化3D人体姿态的新方法。现有方法严重依赖于人-场景交互数据集,导致生成的人体姿态多样性有限。为了克服这一挑战,我们建议解耦姿态和交互生成过程。我们的方法包括三个阶段:姿态生成、接触生成和将人体放入场景。我们首先在人体数据集上训练姿态生成器,以学习丰富的姿态先验;然后在人-场景交互数据集上训练接触生成器,以学习人-场景接触先验。最后,放置模块以合适且自然的方式将人体放入场景中。在PROX数据集上的实验结果表明,我们的方法产生了更符合物理规律的交互,并展现出更多样化的人体姿态。此外,在MP3D-R数据集上的实验进一步验证了我们方法的泛化能力。
🔬 方法详解
问题定义:现有方法在生成场景中的3D人体姿态时,过度依赖人-场景交互数据集,导致生成姿态的多样性不足。这种依赖性限制了模型生成新颖和非典型姿态的能力,使其难以适应真实世界中复杂多变的场景。
核心思路:本文的核心思路是将3D人体姿态的生成过程解耦为姿态生成和交互生成两个独立的部分。通过分别学习人体姿态的先验知识和人与场景的交互先验知识,可以有效地提高生成姿态的多样性和真实感。这种解耦的设计允许模型在生成姿态时更加灵活,避免了对特定数据集的过度依赖。
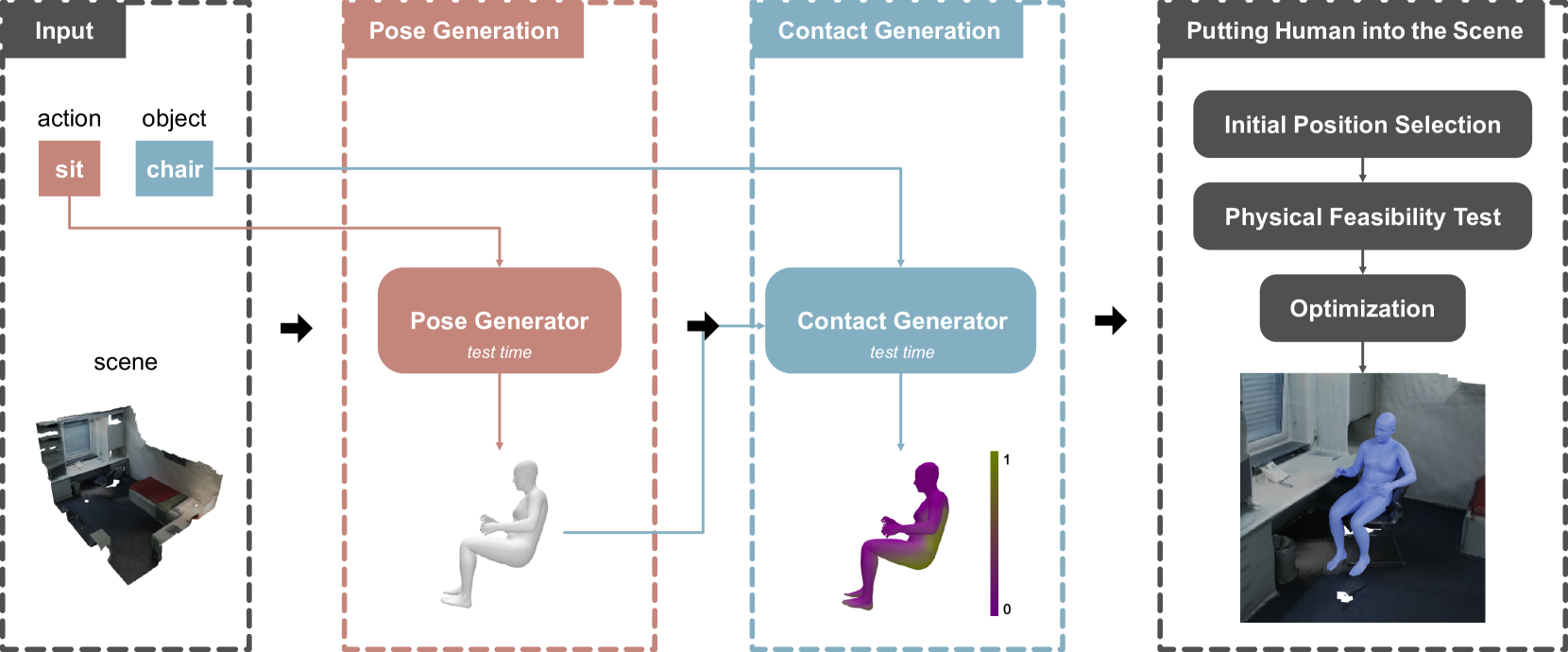
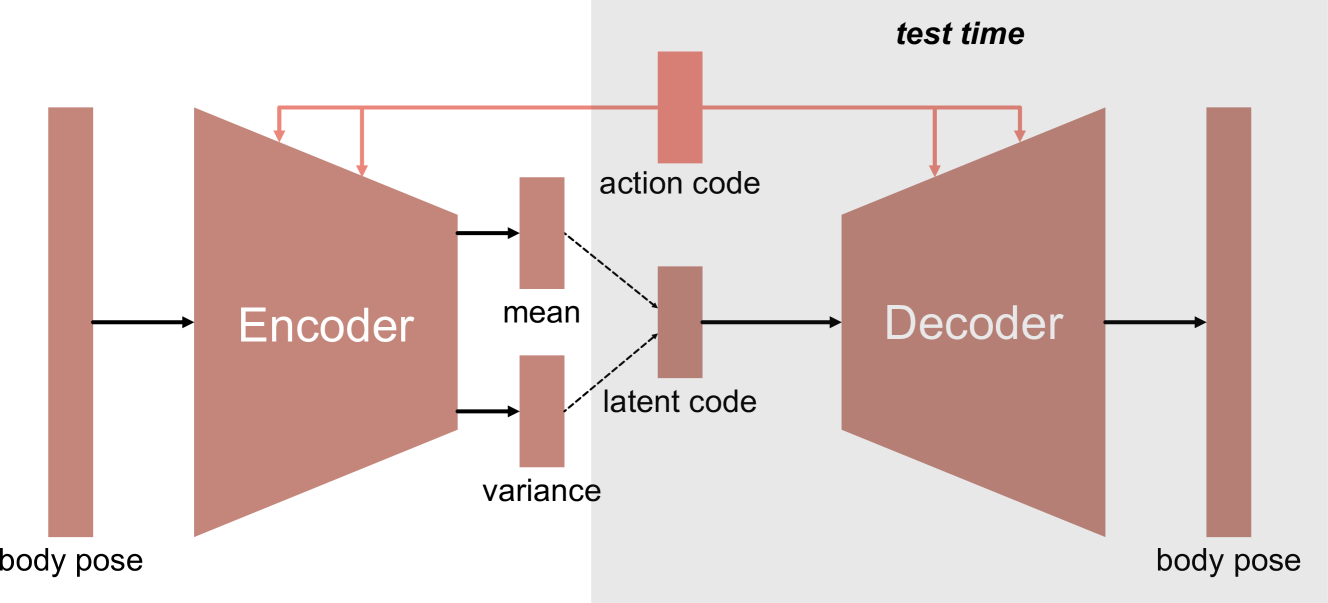
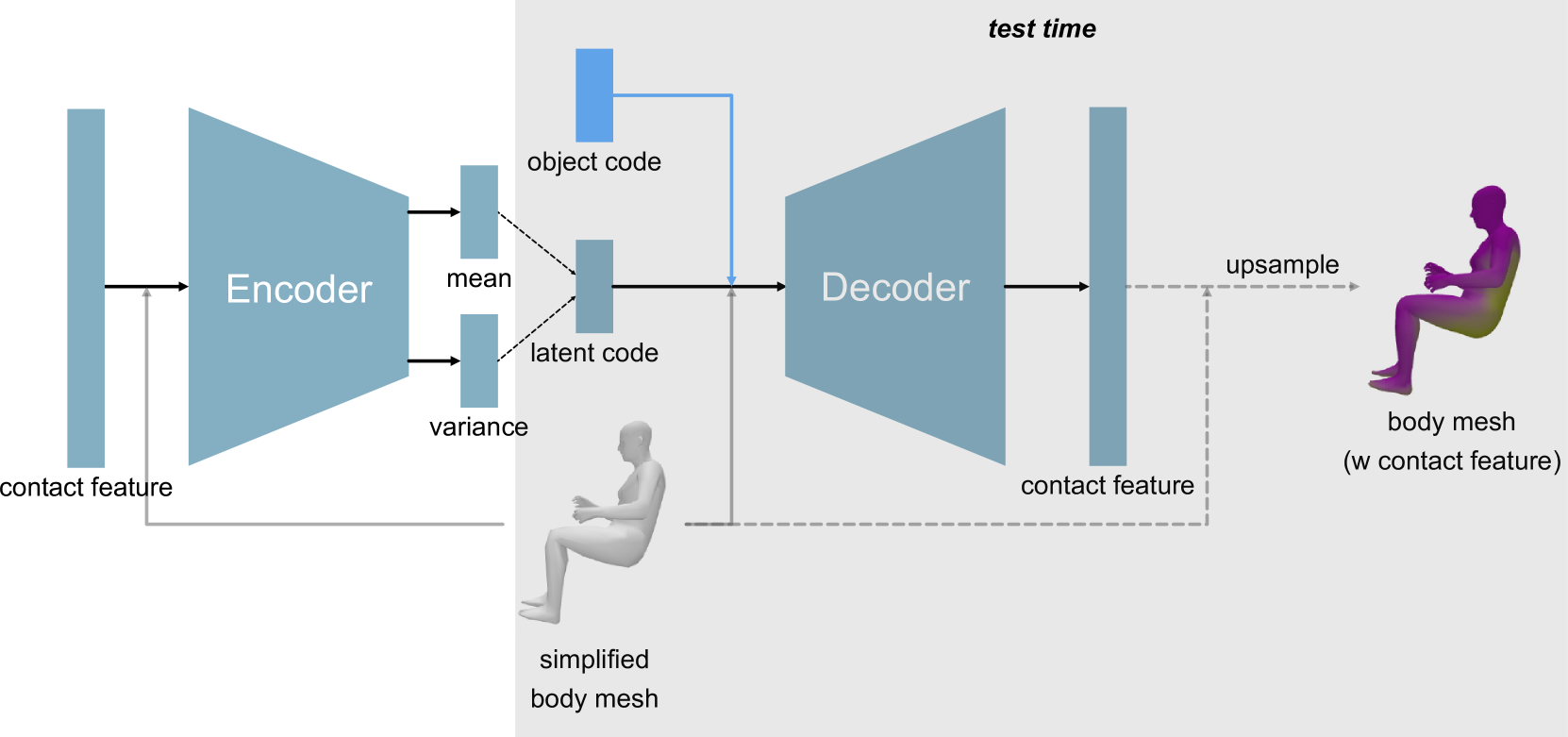
技术框架:该方法包含三个主要阶段:1) 姿态生成:使用在人体数据集上训练的姿态生成器,学习丰富的姿态先验。2) 接触生成:使用在人-场景交互数据集上训练的接触生成器,学习人-场景接触先验。3) 放置模块:将生成的人体姿态以合适且自然的方式放置到场景中。
关键创新:该方法最重要的创新点在于解耦了姿态生成和交互生成过程。与现有方法相比,这种解耦的设计能够更好地利用不同数据集的优势,从而提高生成姿态的多样性和真实感。此外,该方法还引入了接触生成模块,显式地建模了人与场景之间的交互关系,进一步提高了生成结果的物理合理性。
关键设计:姿态生成器和接触生成器的具体网络结构未知,但其训练分别依赖于人体姿态数据集和人-场景交互数据集。放置模块的具体实现细节未知,但其目标是将人体以自然的方式融入场景中,可能涉及到一些优化算法或启发式规则。损失函数的设计可能包括姿态的合理性损失、接触的合理性损失以及放置的合理性损失等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在PROX数据集上能够生成更符合物理规律的交互,并展现出更多样化的人体姿态。与现有方法相比,该方法能够生成更加新颖和非典型的人体姿态,从而更好地适应真实世界中复杂多变的场景。此外,在MP3D-R数据集上的实验进一步验证了该方法的泛化能力,表明该方法能够有效地应用于不同的场景。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、机器人仿真等领域。例如,在虚拟现实环境中,可以利用该方法生成更加真实和多样化的人体姿态,从而提高用户的沉浸感。在机器人仿真中,可以利用该方法生成更加符合物理规律的人体运动,从而提高机器人的运动规划和控制能力。此外,该方法还可以用于生成用于训练人工智能模型的合成数据。
📄 摘要(原文)
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.