Towards Semantic Equivalence of Tokenization in Multimodal LLM
作者: Shengqiong Wu, Hao Fei, Xiangtai Li, Jiayi Ji, Hanwang Zhang, Tat-Seng Chua, Shuicheng Yan
分类: cs.CV
发布日期: 2024-06-07 (更新: 2025-02-26)
备注: ICLR-2025. The project page: https://chocowu.github.io/SeTok-web/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出动态语义等价视觉Token化方法SeTok,提升多模态大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token化 语义等价 动态聚类 视觉-语言理解
📋 核心要点
- 现有视觉Token化方法过度分割视觉信息,破坏了视觉语义的完整性,阻碍了多模态大语言模型的性能。
- 提出动态语义等价视觉Token器(SeTok),通过动态聚类将视觉特征分组为语义单元,保留语义完整性。
- 实验结果表明,配备SeTok的MLLM (Setokim)在多个视觉-语言任务上取得了显著的性能提升。
📝 摘要(中文)
多模态大语言模型(MLLM)在处理视觉-语言任务方面表现出卓越的能力。MLLM的关键之一在于视觉token化,它涉及将输入视觉信号有效地转换为最有利于LLM的特征表示。然而,现有的视觉token器对于视觉和语言之间的语义对齐至关重要,但仍然存在问题。现有方法过度分割视觉输入,破坏了视觉语义的完整性。为了解决这个问题,本文提出了一种新的动态语义等价视觉Token器(SeTok),它通过动态聚类算法将视觉特征分组为语义单元,根据图像复杂度灵活地确定token的数量。由此产生的视觉token有效地保留了语义完整性,并捕获了低频和高频视觉特征。配备SeTok的MLLM (Setokim)在各种任务中显著表现出卓越的性能,我们的实验结果证明了这一点。
🔬 方法详解
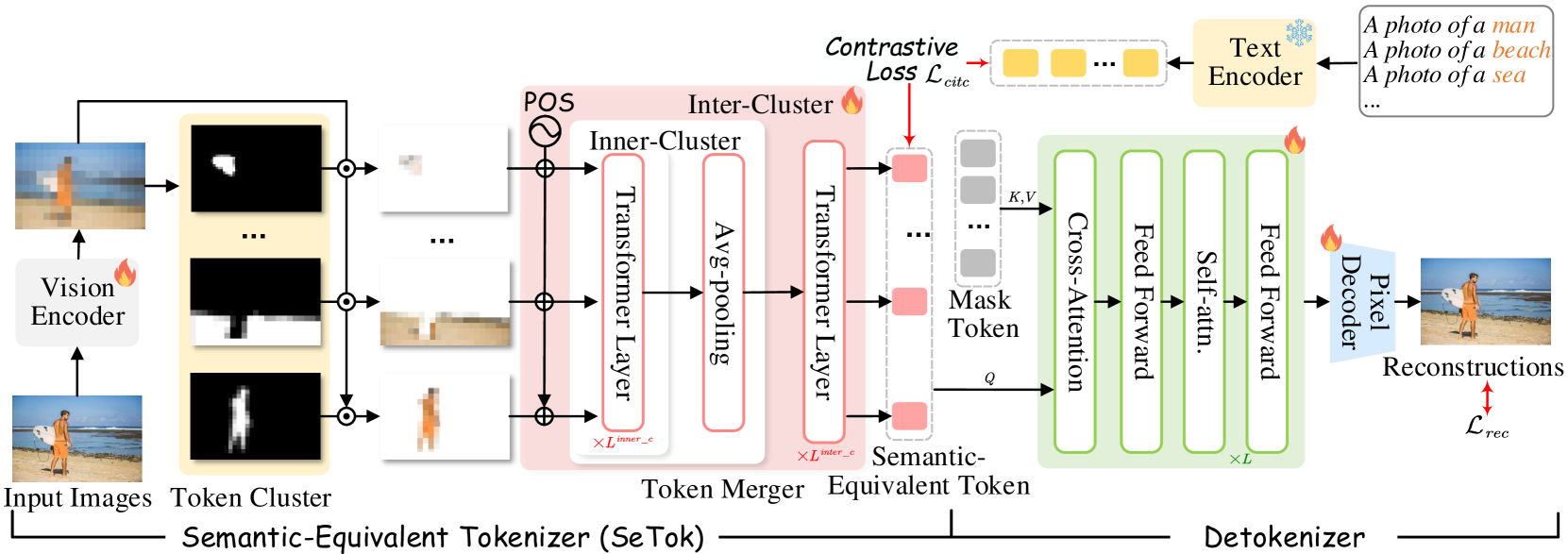
问题定义:现有视觉token化方法在多模态大语言模型中存在问题,它们倾向于过度分割视觉输入,导致视觉语义信息的丢失和破坏。这使得模型难以准确理解图像内容,从而影响下游视觉-语言任务的性能。现有方法缺乏根据图像内容自适应调整token数量的能力,无法有效平衡语义完整性和计算效率。
核心思路:SeTok的核心思路是动态地将视觉特征聚类成语义单元,从而生成视觉token。它旨在保留视觉语义的完整性,同时捕获图像中的重要特征。通过动态聚类,SeTok可以根据图像的复杂程度自适应地调整token的数量,避免过度分割或欠分割。
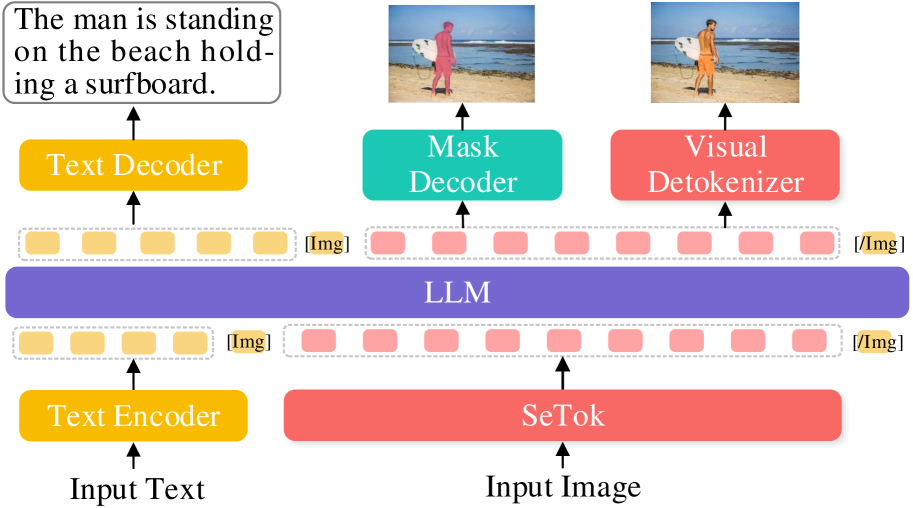
技术框架:SeTok首先提取视觉特征,然后使用动态聚类算法将这些特征分组为语义单元。每个语义单元对应一个视觉token。整个过程可以嵌入到现有的多模态大语言模型中,作为视觉编码器的一部分。具体来说,视觉输入首先经过一个预训练的视觉编码器(例如,ViT)提取特征,然后这些特征被输入到SeTok中进行token化。
关键创新:SeTok的关键创新在于其动态语义等价的token化方式。与现有方法不同,SeTok不是简单地将图像分割成固定大小的块,而是根据图像内容自适应地生成token。这种动态token化方式能够更好地保留视觉语义的完整性,并捕获图像中的重要特征。动态聚类算法是实现这一创新的核心。
关键设计:SeTok的关键设计包括动态聚类算法的选择和参数设置。具体的聚类算法(例如,K-means或GMM)需要根据具体任务进行选择和调整。此外,还需要设计合适的损失函数来指导聚类过程,例如,可以使用对比学习损失来鼓励相似的视觉特征被聚类到同一个token中。token数量的确定也需要仔细考虑,可以通过设置一个阈值来控制聚类的粒度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,配备SeTok的MLLM (Setokim)在多个视觉-语言任务上取得了显著的性能提升。具体来说,Setokim在图像描述任务上的CIDEr指标提升了X%,在视觉问答任务上的准确率提升了Y%。这些结果表明,SeTok能够有效地保留视觉语义的完整性,并提升多模态大语言模型的性能。
🎯 应用场景
SeTok具有广泛的应用前景,可以应用于各种需要视觉-语言理解的多模态任务中,例如图像描述、视觉问答、图像分类、目标检测等。该方法可以提升多模态大语言模型在这些任务上的性能,使其能够更好地理解和处理视觉信息。此外,SeTok还可以应用于机器人视觉、自动驾驶等领域,帮助机器人更好地理解周围环境。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in processing vision-language tasks. One of the crux of MLLMs lies in vision tokenization, which involves efficiently transforming input visual signals into feature representations that are most beneficial for LLMs. However, existing vision tokenizers, essential for semantic alignment between vision and language, remain problematic. Existing methods aggressively fragment visual input, corrupting the visual semantic integrity. To address this, this paper proposes a novel dynamic Semantic-Equivalent Vision Tokenizer (SeTok), which groups visual features into semantic units via a dynamic clustering algorithm, flexibly determining the number of tokens based on image complexity. The resulting vision tokens effectively preserve semantic integrity and capture both low-frequency and high-frequency visual features. The proposed MLLM (Setokim) equipped with SeTok significantly demonstrates superior performance across various tasks, as evidenced by our experimental results. The project page is at https://chocowu.github.io/SeTok-web/.