Efficient 3D Shape Generation via Diffusion Mamba with Bidirectional SSMs
作者: Shentong Mo
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-06-07
💡 一句话要点
提出Diffusion Mamba (DiM-3D)模型,高效生成高分辨率3D形状,解决传统扩散模型计算瓶颈。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D形状生成 扩散模型 Mamba架构 点云处理 高效计算 深度学习 ShapeNet 点云补全
📋 核心要点
- 传统扩散模型在处理高分辨率3D形状生成时,由于自注意力机制的计算复杂度呈立方增长,面临严重的可扩展性问题。
- DiM-3D采用Mamba架构,利用其选择性状态空间方法,实现了线性复杂度,从而避免了传统注意力机制的计算瓶颈。
- 实验表明,DiM-3D在ShapeNet数据集上取得了SOTA性能,并在3D点云补全任务中表现出色,验证了其高效性和可扩展性。
📝 摘要(中文)
本文提出了一种名为Diffusion Mamba (DiM-3D)的新型扩散架构,用于高效生成3D点云。针对传统扩散Transformer (DiT)因自注意力机制的立方复杂度而面临的可扩展性挑战,DiM-3D利用Mamba架构的固有优势,实现了与序列长度呈线性相关的复杂度,无需传统注意力机制。该模型显著降低了计算需求,缩短了推理时间。在ShapeNet基准测试中,DiM-3D在生成高保真度和多样化的3D形状方面达到了最先进的性能,并在3D点云补全等任务中表现出卓越的能力。实验结果表明,Diffusion Mamba框架在3D形状生成方面具有出色的可扩展性和效率,为高分辨率3D建模技术开辟了新的道路。
🔬 方法详解
问题定义:论文旨在解决高分辨率3D形状生成中,传统扩散模型(特别是基于Transformer的扩散模型)因自注意力机制带来的计算复杂度过高的问题。现有方法在处理高分辨率体素数据时,计算成本呈立方级增长,严重限制了其可扩展性和实际应用。
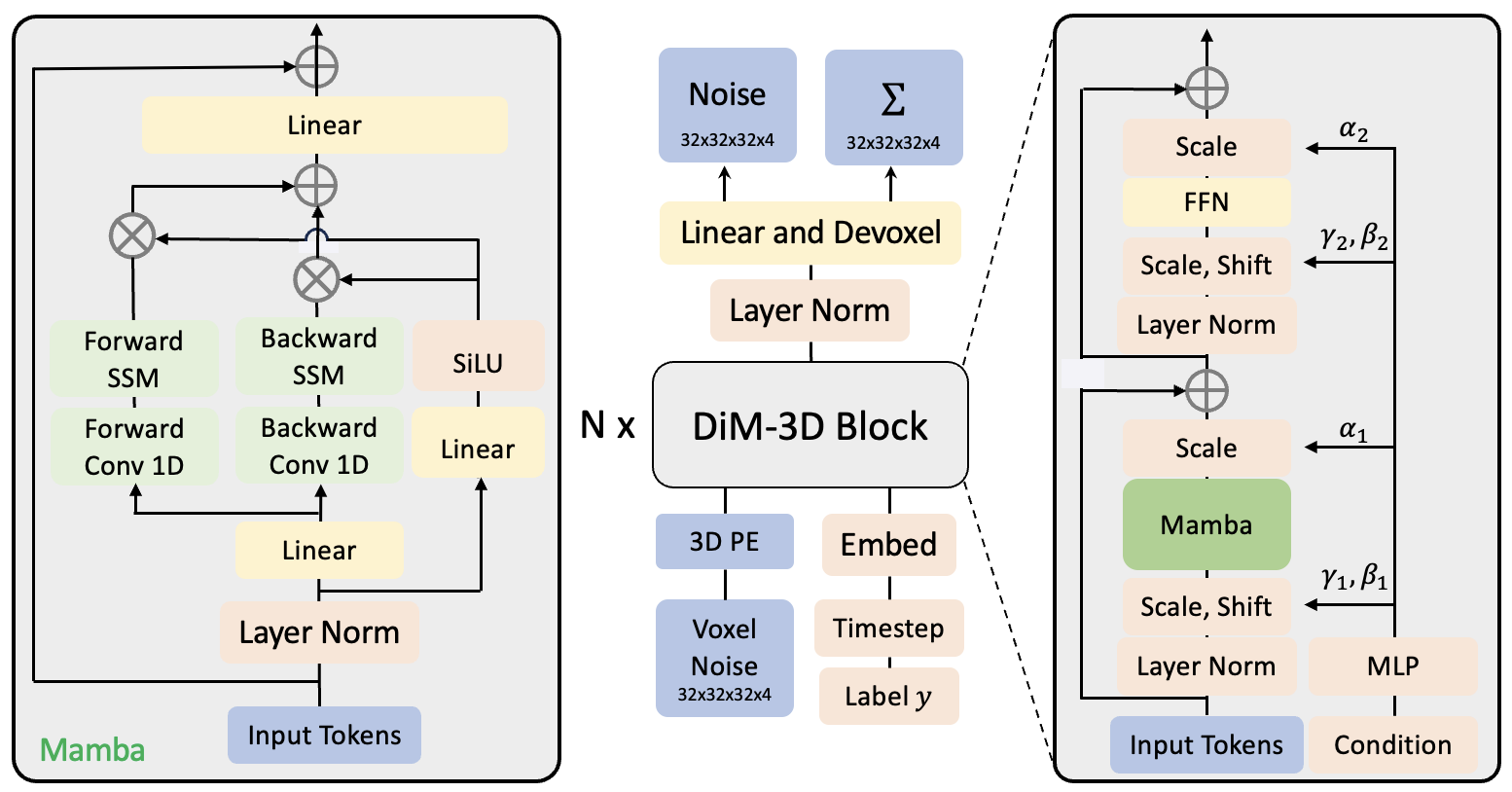
核心思路:论文的核心思路是利用Mamba架构替代传统的自注意力机制。Mamba架构通过选择性状态空间模型(Selective State Space Model, S6)实现高效的长序列建模,其计算复杂度与序列长度呈线性关系,从而显著降低了计算成本,提高了生成效率。
技术框架:DiM-3D的整体架构是一个扩散模型,包含前向扩散过程和反向生成过程。在前向扩散过程中,噪声逐渐添加到3D点云数据中。在反向生成过程中,DiM-3D模型逐步从噪声中恢复出3D形状。DiM-3D的核心模块是基于Mamba架构构建的,用于预测噪声并逐步生成3D点云。
关键创新:最重要的技术创新点在于将Mamba架构引入到3D形状生成扩散模型中,并设计了适用于3D点云数据的Mamba模块。与传统的基于Transformer的扩散模型相比,DiM-3D避免了自注意力机制的计算瓶颈,实现了更高的计算效率和可扩展性。
关键设计:论文中可能涉及的关键设计包括:Mamba模块的具体结构和参数设置,例如状态空间模型的维度、选择机制的实现方式等;损失函数的设计,用于指导模型学习如何从噪声中恢复出高质量的3D形状;以及训练策略,例如学习率的设置、优化器的选择等。这些细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
DiM-3D在ShapeNet数据集上取得了SOTA性能,证明了其生成高质量3D形状的能力。相较于传统扩散模型,DiM-3D在计算效率上具有显著优势,能够处理更高分辨率的3D数据。此外,DiM-3D在3D点云补全任务中表现出色,进一步验证了其在实际应用中的潜力。具体的性能数据和提升幅度需要在论文中查找(未知)。
🎯 应用场景
该研究成果可广泛应用于3D内容创作、计算机辅助设计(CAD)、机器人感知与导航、虚拟现实/增强现实(VR/AR)等领域。高效的3D形状生成能力能够加速产品设计流程,提升机器人对环境的理解能力,并为用户提供更逼真的沉浸式体验。未来,该技术有望推动高精度3D建模在各个行业的普及。
📄 摘要(原文)
Recent advancements in sequence modeling have led to the development of the Mamba architecture, noted for its selective state space approach, offering a promising avenue for efficient long sequence handling. However, its application in 3D shape generation, particularly at high resolutions, remains underexplored. Traditional diffusion transformers (DiT) with self-attention mechanisms, despite their potential, face scalability challenges due to the cubic complexity of attention operations as input length increases. This complexity becomes a significant hurdle when dealing with high-resolution voxel sizes. To address this challenge, we introduce a novel diffusion architecture tailored for 3D point clouds generation-Diffusion Mamba (DiM-3D). This architecture forgoes traditional attention mechanisms, instead utilizing the inherent efficiency of the Mamba architecture to maintain linear complexity with respect to sequence length. DiM-3D is characterized by fast inference times and substantially lower computational demands, quantified in reduced Gflops, thereby addressing the key scalability issues of prior models. Our empirical results on the ShapeNet benchmark demonstrate that DiM-3D achieves state-of-the-art performance in generating high-fidelity and diverse 3D shapes. Additionally, DiM-3D shows superior capabilities in tasks like 3D point cloud completion. This not only proves the model's scalability but also underscores its efficiency in generating detailed, high-resolution voxels necessary for advanced 3D shape modeling, particularly excelling in environments requiring high-resolution voxel sizes. Through these findings, we illustrate the exceptional scalability and efficiency of the Diffusion Mamba framework in 3D shape generation, setting a new standard for the field and paving the way for future explorations in high-resolution 3D modeling technologies.