Training-Free Video Editing via Optical Flow-Enhanced Score Distillation
作者: Lianghan Zhu, Yanqi Bao, Jing Huo, Jing Wu, Yu-Kun Lai, Wenbin Li, Yang Gao
分类: cs.CV
发布日期: 2024-06-07 (更新: 2026-01-04)
💡 一句话要点
提出基于光流增强Score Distillation的免训练视频编辑方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频编辑 免训练学习 Score Distillation 光流估计 内容一致性 时间连续性 预训练模型
📋 核心要点
- 现有免训练视频编辑方法依赖视频输入反演,易丢失原始视频信息,且推理过程中的特征和注意力操作易导致过度编辑。
- 论文提出基于Score Distillation的迭代优化框架,从原始视频出发,结合内容保持损失,避免信息丢失和过度编辑。
- 引入全局一致性损失和光流引导的局部梯度平滑,提升编辑结果的时间连续性和内容一致性,实验表明方法有效。
📝 摘要(中文)
本文提出了一种基于预训练文本到视频模型的免训练视频编辑方法,该方法利用Score Distillation范式,通过编辑梯度引导的多步迭代优化原始视频,最终获得目标视频。该方法从原始视频出发进行迭代优化,并结合内容保持损失,确保了视频未编辑区域的维护,并抑制过度编辑。为了进一步保证视频内容一致性和时间连续性,引入了全局一致性辅助损失和基于光流预测的局部编辑梯度平滑。实验结果表明,与现有方法相比,该方法在未编辑区域的保持、局部时间连续性和全局内容一致性等多个维度上实现了可比或更优的性能。
🔬 方法详解
问题定义:现有的免训练视频编辑方法主要依赖于视频输入反演和在推理过程中对中间特征和注意力进行操作来实现内容编辑。然而,反演过程具有有损性,导致难以维护视频中未编辑的区域。此外,在推理过程中对特征和注意力进行操作可能会导致意外的过度编辑,并且在局部时间连续性和全局内容一致性方面面临挑战。
核心思路:本文的核心思路是通过Score Distillation范式,利用预训练的文本到视频模型,迭代优化原始视频,使其逐步向目标视频靠拢。这种方法避免了反演过程中的信息损失,并能更好地控制编辑的范围和程度。通过从原始视频出发进行优化,并结合内容保持损失,可以有效地保留未编辑区域的信息。
技术框架:该方法主要包含以下几个关键模块:1) 基于预训练文本到视频模型的Score Distillation模块,用于生成编辑梯度;2) 迭代优化模块,通过多步迭代更新原始视频;3) 内容保持损失模块,用于约束未编辑区域的变化;4) 全局一致性辅助损失模块,用于保证视频内容的一致性;5) 基于光流预测的局部编辑梯度平滑模块,用于保证视频的时间连续性。整体流程是从原始视频开始,通过Score Distillation计算编辑梯度,然后利用优化器更新视频,并结合内容保持损失、全局一致性损失和梯度平滑进行约束,重复迭代直至收敛。
关键创新:该方法最重要的创新点在于将Score Distillation范式应用于免训练视频编辑,并结合内容保持损失、全局一致性损失和光流引导的局部梯度平滑,有效地解决了现有方法中存在的未编辑区域信息丢失、过度编辑以及时间连续性和内容一致性问题。与现有方法相比,该方法不需要进行任何训练,并且能够更好地控制编辑的范围和程度。
关键设计:内容保持损失采用L1或L2损失,用于约束编辑后的视频与原始视频在未编辑区域的差异。全局一致性辅助损失可以使用CLIP loss等方法,用于保证视频内容与文本描述的一致性。光流预测采用现有的光流估计网络,用于计算相邻帧之间的光流信息,并用于平滑局部编辑梯度。迭代优化过程中的步长和迭代次数需要根据具体任务进行调整。
🖼️ 关键图片

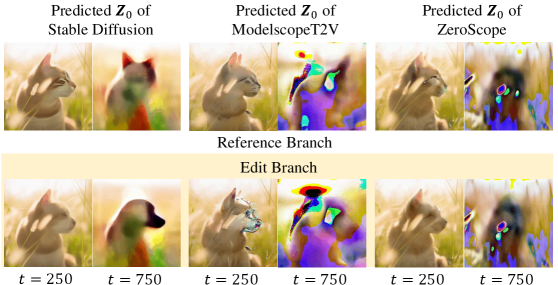

📊 实验亮点
实验结果表明,该方法在多个维度上优于或可媲美当前最先进的方法。具体来说,该方法在保持未编辑区域的原始信息方面表现出色,有效避免了过度编辑的问题。同时,该方法在局部时间连续性和全局内容一致性方面也取得了显著提升,使得编辑后的视频更加自然流畅。定量指标和定性结果均验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于多种视频编辑场景,例如电影特效制作、广告创意设计、社交媒体内容生成等。它能够帮助用户快速、便捷地对视频内容进行编辑和修改,而无需专业的视频编辑技能和大量的训练数据。未来,该技术有望进一步发展,实现更加智能化和个性化的视频编辑功能。
📄 摘要(原文)
The rapid advancement in visual generation, particularly the emergence of pre-trained text-to-image and text-to-video models, has catalyzed growing interest in training-free video editing research. Mirroring training-free image editing techniques, current approaches preserve original video information through video input inversion and manipulating intermediate features and attention during the inference process to achieve content editing. Although they have demonstrated promising results, the lossy nature of the inversion process poses significant challenges in maintaining unedited regions of the video. Furthermore, feature and attention manipulation during inference can lead to unintended over-editing and face challenges in both local temporal continuity and global content consistency. To address these challenges, this study proposes a score distillation paradigm based on pre-trained text-to-video models, where the original video is iteratively optimized through multiple steps guided by editing gradients provided by score distillation to ultimately obtain the target video. The iterative optimization starting from the original video, combined with content preservation loss, ensures the maintenance of unedited regions in the original video and suppresses over-editing. To further guarantee video content consistency and temporal continuity, we additionally introduce a global consistency auxiliary loss and optical flow prediction-based local editing gradient smoothing. Experiments demonstrate that these strategies effectively address the aforementioned challenges, achieving comparable or superior performance across multiple dimensions including preservation of unedited regions, local temporal continuity, and global content consistency of editing results, compared to state-of-the-art methods.