Predictive Dynamic Fusion
作者: Bing Cao, Yinan Xia, Yi Ding, Changqing Zhang, Qinghua Hu
分类: cs.CV, cs.LG
发布日期: 2024-06-07 (更新: 2024-11-05)
备注: Accepted by ICML 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出预测动态融合框架,解决多模态融合中的不稳定性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 动态融合 协同信念 泛化误差 深度学习
📋 核心要点
- 现有动态多模态融合方法缺乏理论支撑,容易陷入局部最优,导致融合结果不稳定和不可靠。
- 论文提出预测动态融合(PDF)框架,通过可预测的协同信念(Co-Belief)降低泛化误差上界。
- 实验结果表明,该方法在多个基准数据集上优于现有方法,验证了其有效性。
📝 摘要(中文)
多模态融合在联合决策系统中至关重要,能够提供全面的判断依据。由于多模态数据在开放环境中不断变化,动态融合应运而生,并在众多应用中取得了显著进展。然而,现有动态多模态融合方法大多缺乏理论保证,容易陷入次优解,导致不可靠和不稳定的问题。为了解决这个问题,我们提出了一个用于多模态学习的预测动态融合(PDF)框架。我们从泛化的角度揭示了多模态融合的本质,并从理论上推导出了具有单模态和整体置信度的可预测的协同信念(Co-Belief),这可以有效地降低泛化误差的上界。相应地,我们进一步提出了一种相对校准策略来校准预测的协同信念,以应对潜在的不确定性。在多个基准数据集上的大量实验证实了我们方法的优越性。代码已开源。
🔬 方法详解
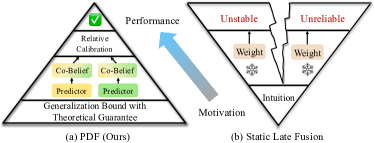
问题定义:现有动态多模态融合方法在开放环境中表现出不稳定性,缺乏理论保证,容易陷入次优解。这导致融合结果的可靠性降低,影响了联合决策系统的性能。论文旨在解决多模态融合中的不稳定性问题,提高融合结果的泛化能力和鲁棒性。
核心思路:论文的核心思路是从泛化的角度理解多模态融合,通过理论推导得到可预测的协同信念(Co-Belief),并利用单模态和整体置信度来指导融合过程。通过降低泛化误差的上界,提高融合结果的稳定性和可靠性。
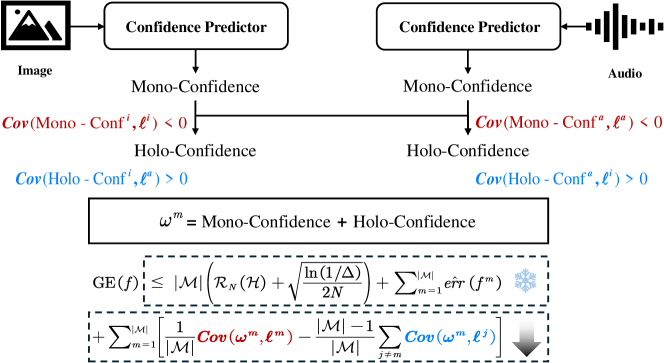
技术框架:PDF框架主要包含以下几个阶段:1) 特征提取:从不同的模态中提取特征表示。2) 协同信念预测:基于提取的特征,预测协同信念(Co-Belief),包括单模态置信度和整体置信度。3) 相对校准:利用相对校准策略,校准预测的协同信念,以应对潜在的不确定性。4) 融合决策:基于校准后的协同信念,进行最终的融合决策。
关键创新:论文的关键创新在于从泛化的角度对多模态融合进行建模,并提出了可预测的协同信念(Co-Belief)的概念。通过理论推导证明了Co-Belief可以降低泛化误差的上界,从而提高了融合结果的稳定性和可靠性。此外,相对校准策略能够有效地应对潜在的不确定性,进一步提升了融合性能。
关键设计:论文中,协同信念(Co-Belief)的预测可能涉及到特定的网络结构设计,例如使用多层感知机(MLP)或图神经网络(GNN)来学习模态之间的关系和置信度。相对校准策略的具体实现可能涉及到损失函数的设计,例如使用KL散度或交叉熵损失来衡量预测的Co-Belief与真实Co-Belief之间的差异。具体的参数设置和网络结构细节需要在代码中进一步分析。
🖼️ 关键图片

📊 实验亮点
论文在多个基准数据集上进行了实验,结果表明,所提出的PDF框架优于现有的动态多模态融合方法。具体的性能提升幅度需要参考论文中的实验数据,例如在某个数据集上,PDF框架的准确率比基线方法提高了X%。这些实验结果验证了PDF框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种需要多模态信息融合的场景,例如自动驾驶、医疗诊断、情感识别、视频理解等。通过提高多模态融合的稳定性和可靠性,可以提升这些应用系统的性能和用户体验,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Multimodal fusion is crucial in joint decision-making systems for rendering holistic judgments. Since multimodal data changes in open environments, dynamic fusion has emerged and achieved remarkable progress in numerous applications. However, most existing dynamic multimodal fusion methods lack theoretical guarantees and easily fall into suboptimal problems, yielding unreliability and instability. To address this issue, we propose a Predictive Dynamic Fusion (PDF) framework for multimodal learning. We proceed to reveal the multimodal fusion from a generalization perspective and theoretically derive the predictable Collaborative Belief (Co-Belief) with Mono- and Holo-Confidence, which provably reduces the upper bound of generalization error. Accordingly, we further propose a relative calibration strategy to calibrate the predicted Co-Belief for potential uncertainty. Extensive experiments on multiple benchmarks confirm our superiority. Our code is available at https://github.com/Yinan-Xia/PDF.