RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation
作者: Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Pengju An, Xiaoqi Li, Kaichen Zhou, Senqiao Yang, Renrui Zhang, Yandong Guo, Shanghang Zhang
分类: cs.CV
发布日期: 2024-06-06 (更新: 2024-12-14)
备注: Accepted by Neurips 2024
💡 一句话要点
RoboMamba:高效的视觉-语言-动作模型,用于机器人推理与操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 状态空间模型 Mamba 机器人推理 位姿预测 高效微调
📋 核心要点
- 现有的机器人视觉-语言-动作模型在复杂任务的推理能力和模型微调与推理的计算成本方面面临挑战。
- RoboMamba利用Mamba状态空间模型,通过联合训练视觉和语言嵌入,赋予模型视觉常识和机器人相关的推理能力。
- 实验表明,RoboMamba在推理能力和位姿预测方面表现出色,推理速度比现有VLA模型快3倍,且仅需少量微调参数。
📝 摘要(中文)
本文提出RoboMamba,一个端到端的机器人视觉-语言-动作(VLA)模型,利用Mamba状态空间模型实现机器人推理和动作能力,同时保持高效的微调和推理。该模型首先将视觉编码器与Mamba集成,通过联合训练对齐视觉tokens和语言嵌入,赋予模型视觉常识和机器人相关的推理能力。为了进一步赋予RoboMamba SE(3)位姿预测能力,探索了一种高效的微调策略,使用一个简单的策略头。实验表明,一旦RoboMamba具备足够的推理能力,它就能以极少的微调参数(模型参数的0.1%)和时间获得操作技能。RoboMamba在通用和机器人评估基准上展示了出色的推理能力,并在模拟和真实世界的实验中展示了令人印象深刻的位姿预测结果,推理速度比现有的VLA模型快3倍。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在机器人操作任务中,面临着两个主要问题:一是缺乏足够的推理能力来处理复杂的任务;二是VLA模型的微调和推理需要很高的计算成本。因此,如何设计一个既能进行有效推理,又能高效微调和推理的VLA模型是本文要解决的问题。
核心思路:本文的核心思路是利用最近提出的状态空间模型(SSM)Mamba,它在序列建模方面表现出良好的性能,并且具有线性推理复杂度。通过将视觉编码器与Mamba集成,并进行视觉tokens和语言嵌入的联合训练,可以赋予模型视觉常识和机器人相关的推理能力。此外,通过高效的微调策略,可以使模型快速获得操作技能。
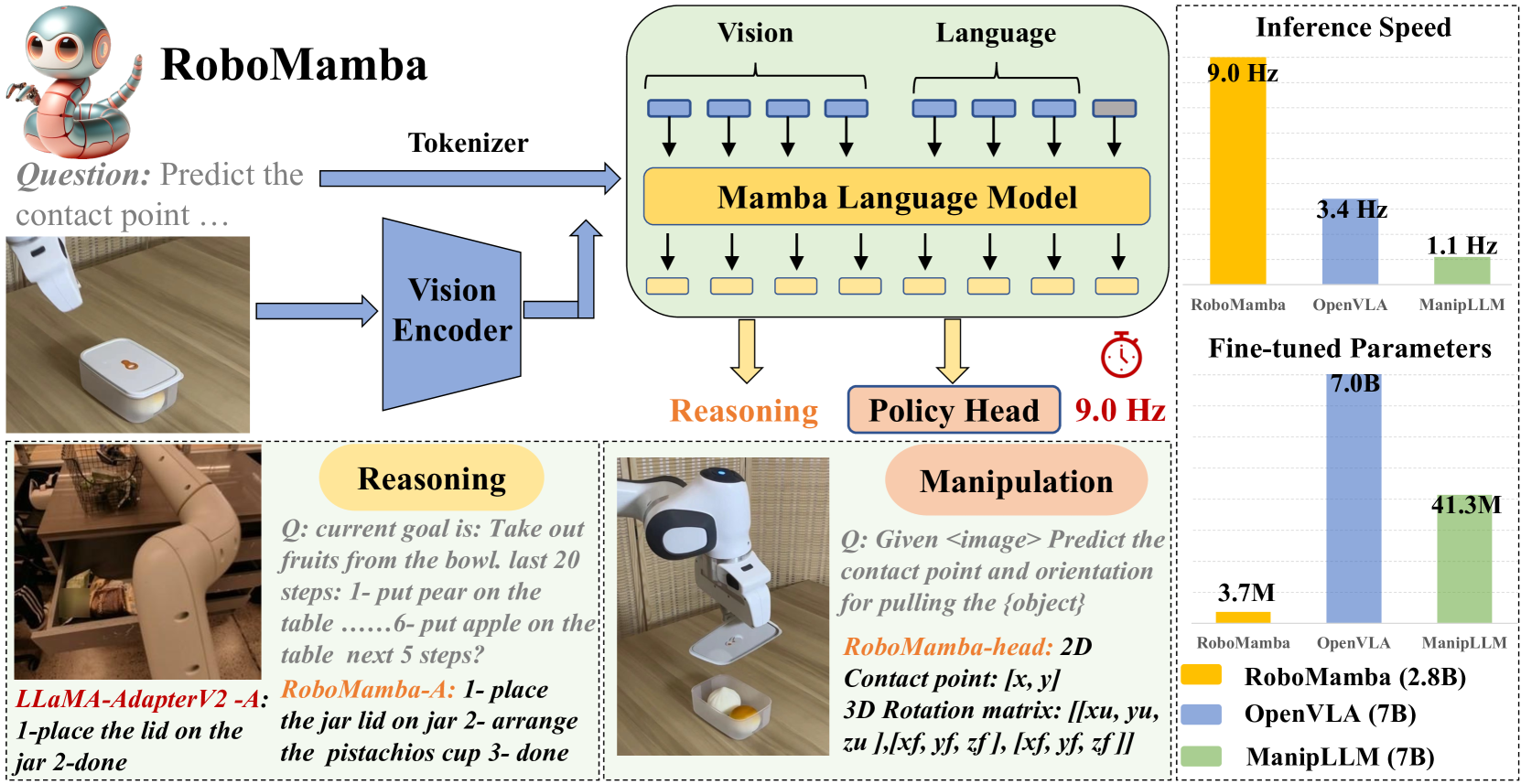
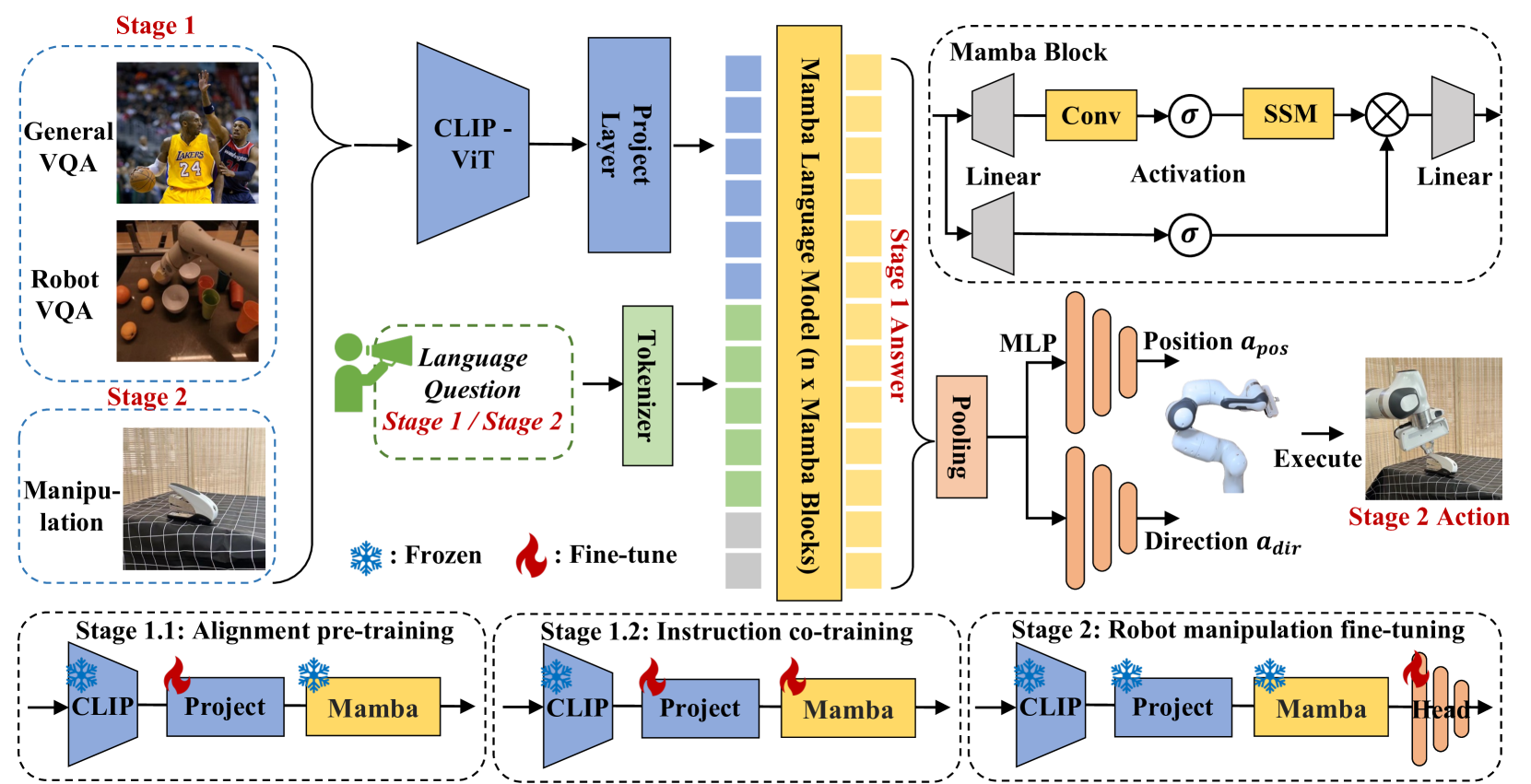
技术框架:RoboMamba的整体框架包括视觉编码器、Mamba模型和策略头三个主要模块。首先,视觉编码器将输入的图像转换为视觉tokens。然后,Mamba模型将视觉tokens和语言嵌入作为输入,进行联合推理。最后,策略头根据Mamba模型的输出,预测机器人的动作,例如SE(3)位姿。整个流程是端到端可训练的。
关键创新:RoboMamba的关键创新在于将Mamba状态空间模型引入到机器人VLA模型中。与传统的Transformer模型相比,Mamba具有线性推理复杂度,因此可以显著提高模型的推理速度。此外,通过联合训练视觉和语言嵌入,可以有效地提高模型的推理能力。
关键设计:在视觉编码器方面,使用了常见的卷积神经网络或Transformer模型。在Mamba模型方面,使用了标准的Mamba架构。在策略头方面,使用了一个简单的多层感知机(MLP)来预测机器人的动作。为了实现高效的微调,只对策略头的参数进行微调,而保持Mamba模型的参数不变。微调参数仅占模型总参数的0.1%。损失函数包括位姿预测损失和动作预测损失。
🖼️ 关键图片
📊 实验亮点
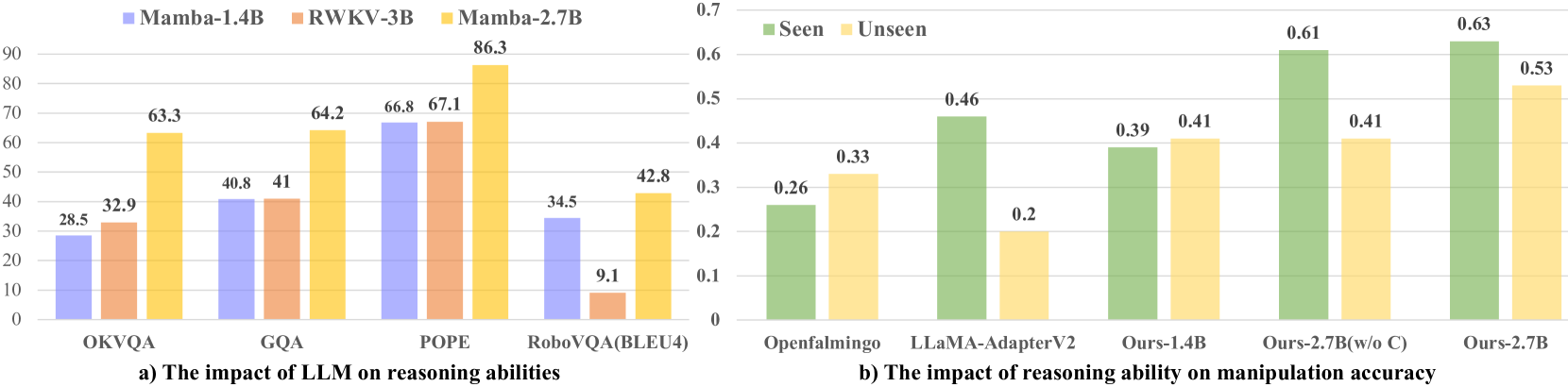
RoboMamba在通用和机器人评估基准上展示了出色的推理能力。在模拟和真实世界的实验中,RoboMamba实现了令人印象深刻的位姿预测结果,推理速度比现有的VLA模型快3倍。更重要的是,RoboMamba仅需少量微调参数(模型参数的0.1%)和时间即可获得操作技能,这大大降低了模型的训练成本。
🎯 应用场景
RoboMamba具有广泛的应用前景,例如在智能制造、家庭服务、医疗辅助等领域。它可以用于控制机器人执行各种复杂的任务,例如装配、清洁、护理等。通过提高机器人的推理能力和操作效率,RoboMamba可以显著提高生产效率和服务质量,并降低人工成本。未来,RoboMamba有望成为机器人领域的一项关键技术。
📄 摘要(原文)
A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing Vision-Language-Action (VLA) models for robots can handle a range of basic tasks, they still face challenges in two areas: (1) insufficient reasoning ability to tackle complex tasks, and (2) high computational costs for VLA model fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic VLA model that leverages Mamba to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual tokens with language embedding through co-training, empowering our model with visual common sense and robotic-related reasoning. To further equip RoboMamba with SE(3) pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time. In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 3 times faster than existing VLA models. Our project web page: https://sites.google.com/view/robomamba-web