DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
作者: Lingchen Meng, Jianwei Yang, Rui Tian, Xiyang Dai, Zuxuan Wu, Jianfeng Gao, Yu-Gang Jiang
分类: cs.CV
发布日期: 2024-06-06
备注: Project Page: https://deepstack-vl.github.io/
💡 一句话要点
DeepStack:一种简单有效的视觉tokens深度堆叠方法,提升大型多模态模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型多模态模型 视觉tokens 深度学习 Transformer 分层堆叠
📋 核心要点
- 现有LMMs将视觉tokens直接输入LLM首层,导致计算和内存成本显著增加,成为性能瓶颈。
- DeepStack将视觉tokens分层堆叠,逐层输入到LMMs的transformer层,增强跨层视觉交互建模能力。
- 实验表明,DeepStack在多个基准测试中显著提升LMMs性能,尤其在高分辨率任务上优势明显。
📝 摘要(中文)
大多数大型多模态模型(LMMs)通过将视觉tokens作为序列输入到大型语言模型(LLM)的第一层来实现。这种架构虽然简单,但显著增加了计算和内存成本,因为它必须处理输入层中大量额外的tokens。本文提出了一种新的LMMs架构DeepStack。考虑到LMMs的语言和视觉transformer中有N层,我们将视觉tokens堆叠成N组,并将每组从下到上馈送到其对齐的transformer层。令人惊讶的是,这种简单的方法极大地增强了LMMs对跨层视觉tokens之间交互进行建模的能力,而只需极少的额外成本。我们将DeepStack应用于LMMs中的语言和视觉transformer,并通过大量的实验结果验证了DeepStack LMMs的有效性。在使用相同上下文长度的情况下,我们的DeepStack 7B和13B参数模型在9个基准测试中平均超过了它们的对应模型2.7和2.9。仅使用五分之一的上下文长度,DeepStack就能与使用完整上下文长度的对应模型相媲美。这些收益在高分辨率任务上尤为明显,例如,与LLaVA-1.5-7B相比,在TextVQA、DocVQA和InfoVQA上分别提高了4.2、11.0和4.0。我们进一步将DeepStack应用于视觉transformer层,这为我们带来了类似的改进,与LLaVA-1.5-7B相比平均提高了3.8。
🔬 方法详解
问题定义:现有大型多模态模型(LMMs)通常将视觉tokens作为序列直接输入到大型语言模型(LLM)的第一层。这种方法虽然简单,但由于需要在输入层处理大量的额外tokens,导致计算和内存成本显著增加,限制了模型的扩展性和在高分辨率图像任务上的表现。现有方法缺乏对视觉tokens在不同层级之间交互的有效建模。
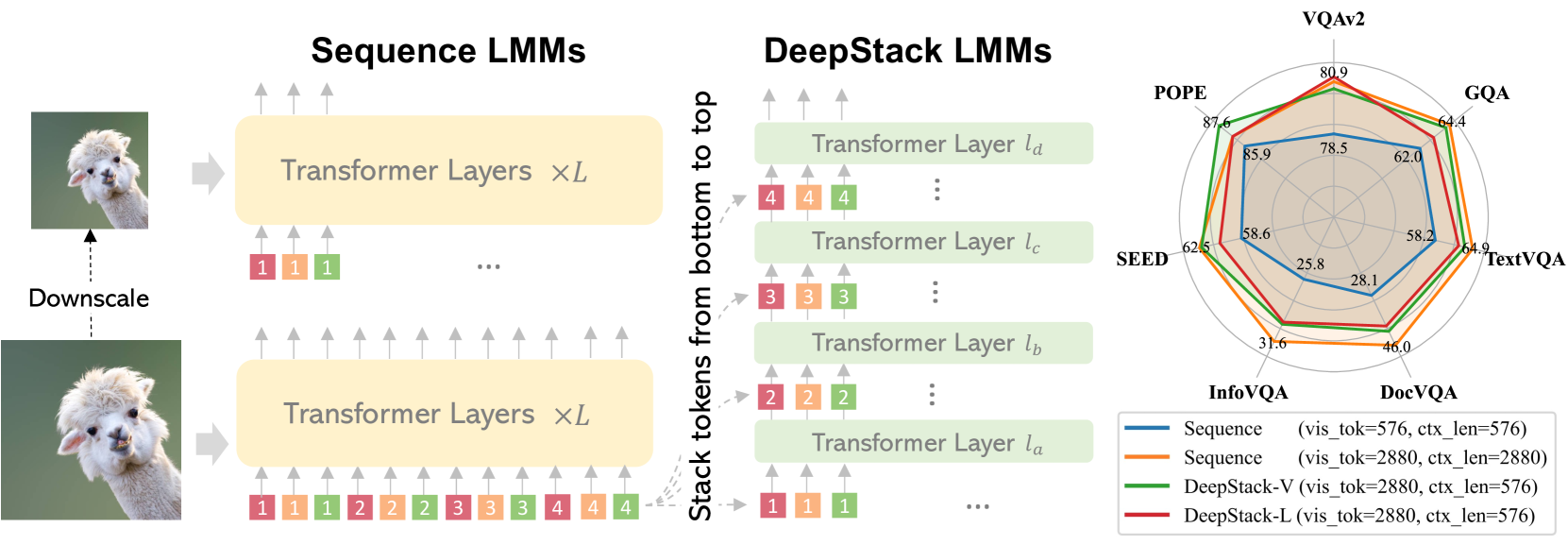
核心思路:DeepStack的核心思路是将视觉tokens分层堆叠,并逐层输入到LMMs的transformer层中。具体来说,对于一个N层的LMM,将视觉tokens分成N组,并将第i组tokens输入到第i个transformer层。这种设计允许模型在不同的层级上学习视觉tokens之间的交互,从而更有效地利用视觉信息。
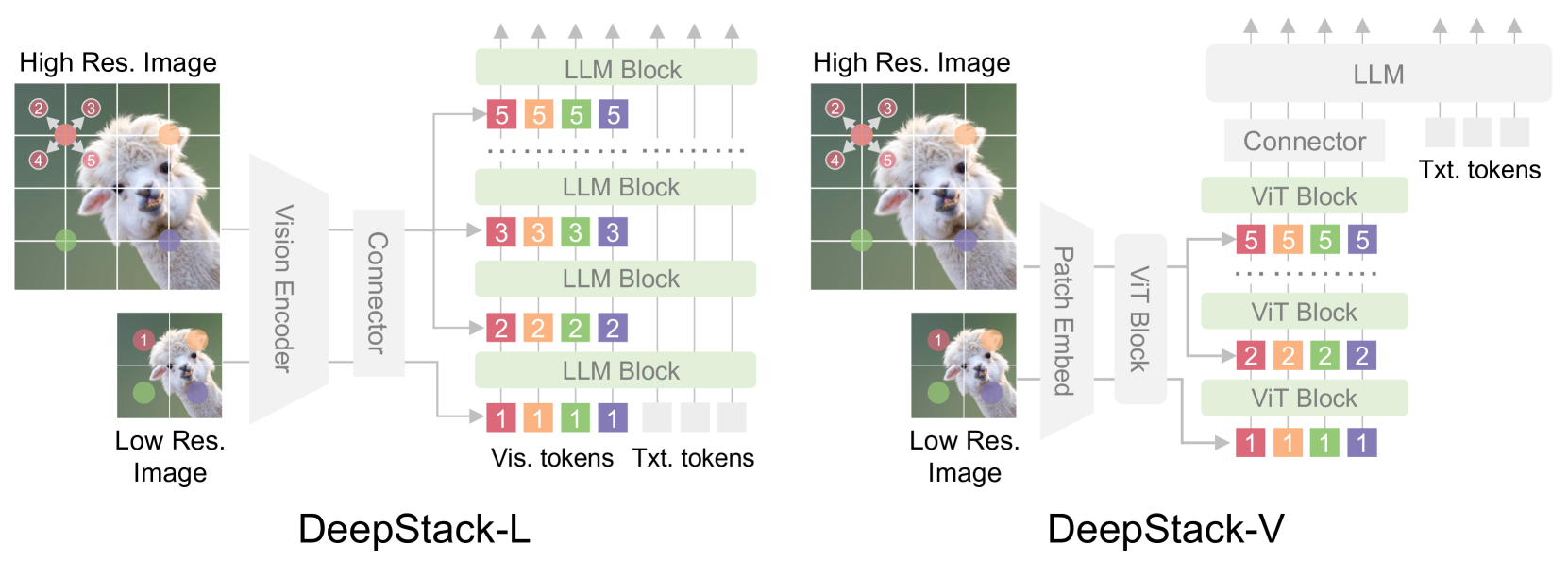
技术框架:DeepStack的整体架构是在现有的LMMs框架上进行改进。它主要包含以下几个阶段:1) 视觉编码器:将输入图像编码成视觉tokens。2) 视觉tokens堆叠:将视觉tokens分成N组,对应LMMs的N个transformer层。3) 分层输入:将每组视觉tokens输入到对应的transformer层。4) 语言模型:利用LLM进行文本生成或视觉问答等任务。
关键创新:DeepStack最重要的技术创新点在于其分层堆叠和逐层输入的策略。与现有方法将所有视觉tokens一次性输入到LLM的第一层不同,DeepStack允许模型在不同的层级上学习视觉tokens之间的交互,从而更有效地利用视觉信息。这种方法在计算成本增加不多的情况下,显著提升了模型的性能。
关键设计:DeepStack的关键设计包括:1) 视觉tokens的分组策略:如何将视觉tokens分成N组,以最大化模型对视觉信息的利用率。论文中采用了一种简单的均匀分组策略,即将视觉tokens平均分配到N组中。2) Transformer层的对齐:如何将视觉tokens组与transformer层进行对齐。论文中采用了一种简单的从下到上的对齐方式,即将第i组tokens输入到第i个transformer层。3) 损失函数:论文中使用标准的交叉熵损失函数进行训练。
🖼️ 关键图片

📊 实验亮点
DeepStack在多个基准测试中取得了显著的性能提升。例如,在使用相同上下文长度的情况下,DeepStack 7B和13B参数模型在9个基准测试中平均超过了它们的对应模型2.7和2.9。在高分辨率任务上,与LLaVA-1.5-7B相比,在TextVQA、DocVQA和InfoVQA上分别提高了4.2、11.0和4.0。更令人惊讶的是,仅使用五分之一的上下文长度,DeepStack就能与使用完整上下文长度的对应模型相媲美。
🎯 应用场景
DeepStack具有广泛的应用前景,包括但不限于:视觉问答、图像描述、文档理解、信息抽取等。该方法可以提升LMMs在各种视觉任务上的性能,尤其是在高分辨率图像处理方面。未来,DeepStack可以应用于自动驾驶、医疗影像分析、智能客服等领域,具有重要的实际价值。
📄 摘要(原文)
Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer \textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by \textbf{2.7} and \textbf{2.9} on average across \textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., \textbf{4.2}, \textbf{11.0}, and \textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, \textbf{3.8} on average compared with LLaVA-1.5-7B.