DIRECT-3D: Learning Direct Text-to-3D Generation on Massive Noisy 3D Data
作者: Qihao Liu, Yi Zhang, Song Bai, Adam Kortylewski, Alan Yuille
分类: cs.CV
发布日期: 2024-06-06 (更新: 2024-06-07)
备注: Accepted to CVPR 2024. Code: https://github.com/qihao067/direct3d Project page: https://direct-3d.github.io/
🔗 代码/项目: GITHUB
💡 一句话要点
DIRECT-3D:提出一种基于扩散模型的大规模噪声3D数据直接文本到3D生成方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 文本到3D生成 扩散模型 神经辐射场 噪声数据 三平面表示
📋 核心要点
- 现有3D生成模型依赖于干净对齐的3D数据,限制了其在单类或少类生成任务上的应用。
- DIRECT-3D通过在大量噪声数据上直接训练,并采用自动过滤和对齐机制,解决了数据稀缺问题。
- 该模型在单类生成和文本到3D生成任务上取得了SOTA性能,并可作为3D几何先验缓解Janus问题。
📝 摘要(中文)
本文提出DIRECT-3D,一种基于扩散的3D生成模型,用于从文本提示创建高质量的3D资产(由神经辐射场表示)。与最近依赖于干净且对齐良好的3D数据的3D生成模型不同,这些模型通常局限于单类或少类生成,我们的模型直接在大量噪声和未对齐的“野外”3D资产上进行训练,从而缓解了大规模3D生成中的关键挑战(即数据稀缺)。具体而言,DIRECT-3D是一个三平面扩散模型,集成了两项创新:1) 一种新颖的学习框架,其中噪声数据在训练过程中自动过滤和对齐。具体来说,在使用少量干净数据进行初始预热阶段后,在扩散过程中引入迭代优化,以显式估计对象的3D姿势并基于条件密度选择有益数据。2) 一种高效的3D表示,通过使用两个单独的条件扩散模型分层优化来解耦对象几何和颜色特征来实现。给定提示输入,我们的模型可以在几秒钟内生成具有精确几何细节的高质量、高分辨率、逼真且复杂的3D对象。我们在单类生成和文本到3D生成方面都实现了最先进的性能。我们还证明了DIRECT-3D可以作为对象有用的3D几何先验,例如,以减轻2D-lifting方法(如DreamFusion)中众所周知的Janus问题。代码和模型可在https://github.com/qihao067/direct3d 获取,供研究使用。
🔬 方法详解
问题定义:现有的文本到3D生成模型通常依赖于高质量、对齐的3D数据集进行训练,这限制了它们的可扩展性和泛化能力。真实世界中存在大量未对齐、带有噪声的3D数据,如何有效利用这些数据进行3D生成是一个挑战。此外,如何从文本提示生成具有高质量几何细节和逼真外观的3D模型也是一个难点。
核心思路:DIRECT-3D的核心思路是直接在大量噪声3D数据上训练扩散模型,并通过迭代优化来自动过滤和对齐数据。通过条件密度估计来选择有益的数据,并使用分层优化的条件扩散模型来解耦几何和颜色特征,从而实现高质量的3D生成。
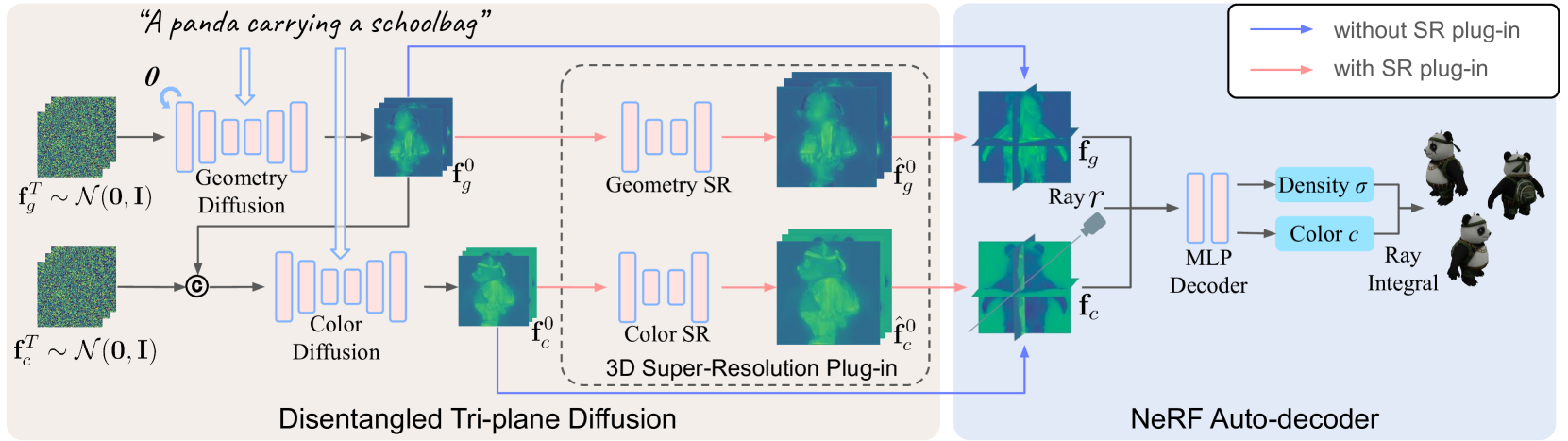
技术框架:DIRECT-3D是一个三平面扩散模型,其整体流程包括:1) 使用少量干净数据进行预热;2) 在扩散过程中,迭代估计3D姿势并基于条件密度选择数据;3) 使用两个条件扩散模型分别生成几何和颜色特征,并进行分层优化。该模型以文本提示作为输入,输出高质量的3D神经辐射场表示。
关键创新:DIRECT-3D的关键创新在于:1) 提出了一种在噪声数据上进行训练的框架,通过迭代优化实现自动过滤和对齐;2) 使用分层优化的条件扩散模型解耦几何和颜色特征,提高了生成质量和效率。与现有方法相比,DIRECT-3D能够直接利用大规模噪声数据,避免了对高质量数据的依赖。
关键设计:DIRECT-3D的关键设计包括:1) 使用三平面表示3D场景;2) 使用条件密度估计来选择有益数据;3) 使用两个独立的条件扩散模型分别生成几何和颜色特征,并进行分层优化。具体的损失函数和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
DIRECT-3D在单类生成和文本到3D生成任务上都取得了state-of-the-art的性能。实验结果表明,该模型能够生成具有高质量几何细节和逼真外观的3D模型。此外,该模型还可以作为3D几何先验,有效缓解2D-lifting方法中的Janus问题。
🎯 应用场景
DIRECT-3D在游戏开发、虚拟现实、增强现实、工业设计等领域具有广泛的应用前景。它可以根据文本描述快速生成各种3D模型,降低了3D内容创作的门槛,并可以作为3D几何先验,辅助其他3D视觉任务,例如2D图像到3D模型的重建。
📄 摘要(原文)
We present DIRECT-3D, a diffusion-based 3D generative model for creating high-quality 3D assets (represented by Neural Radiance Fields) from text prompts. Unlike recent 3D generative models that rely on clean and well-aligned 3D data, limiting them to single or few-class generation, our model is directly trained on extensive noisy and unaligned `in-the-wild' 3D assets, mitigating the key challenge (i.e., data scarcity) in large-scale 3D generation. In particular, DIRECT-3D is a tri-plane diffusion model that integrates two innovations: 1) A novel learning framework where noisy data are filtered and aligned automatically during the training process. Specifically, after an initial warm-up phase using a small set of clean data, an iterative optimization is introduced in the diffusion process to explicitly estimate the 3D pose of objects and select beneficial data based on conditional density. 2) An efficient 3D representation that is achieved by disentangling object geometry and color features with two separate conditional diffusion models that are optimized hierarchically. Given a prompt input, our model generates high-quality, high-resolution, realistic, and complex 3D objects with accurate geometric details in seconds. We achieve state-of-the-art performance in both single-class generation and text-to-3D generation. We also demonstrate that DIRECT-3D can serve as a useful 3D geometric prior of objects, for example to alleviate the well-known Janus problem in 2D-lifting methods such as DreamFusion. The code and models are available for research purposes at: https://github.com/qihao067/direct3d.