Understanding Information Storage and Transfer in Multi-modal Large Language Models
作者: Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, Daniela Massiceti
分类: cs.CV
发布日期: 2024-06-06
备注: 20 pages
💡 一句话要点
提出多模态大语言模型信息溯源方法,揭示视觉问答中的信息存储与传递机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉问答 因果信息追踪 模型编辑 信息存储 信息传递 可解释性 VQA-Constraints
📋 核心要点
- 现有研究缺乏对多模态大语言模型(MLLM)信息存储和传递机制的深入理解,阻碍了模型能力的进一步提升。
- 论文提出一种基于约束的因果信息追踪方法,用于分析MLLM在视觉问答任务中如何利用视觉和文本信息。
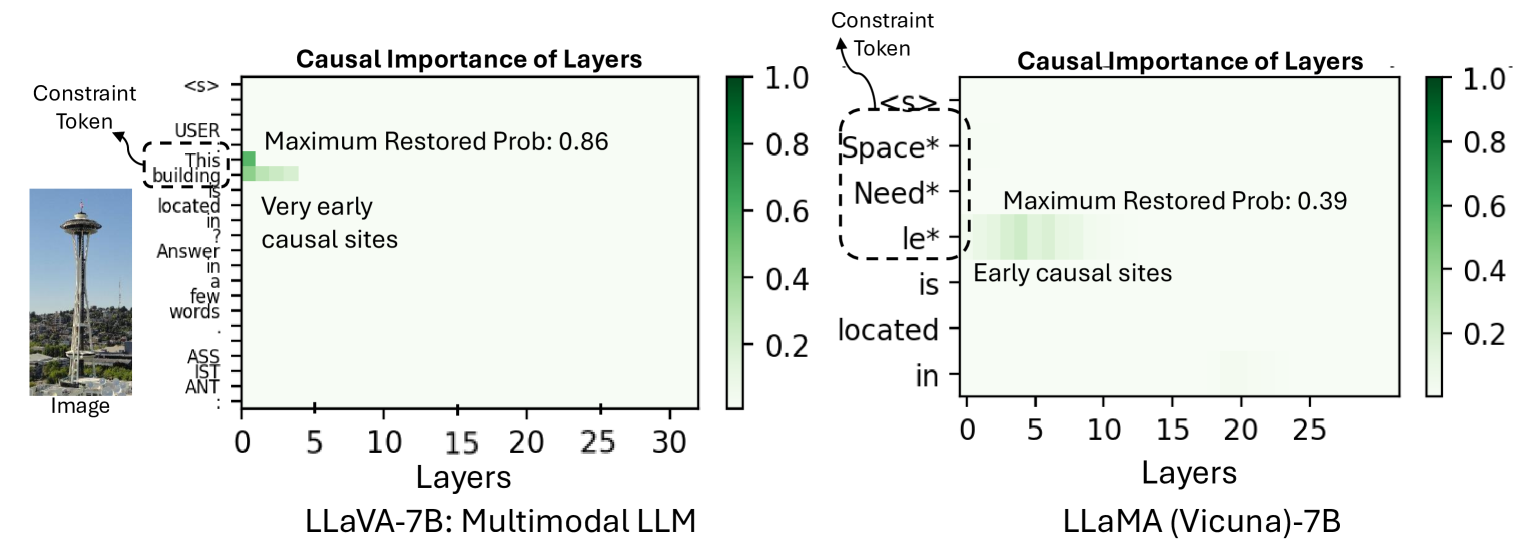
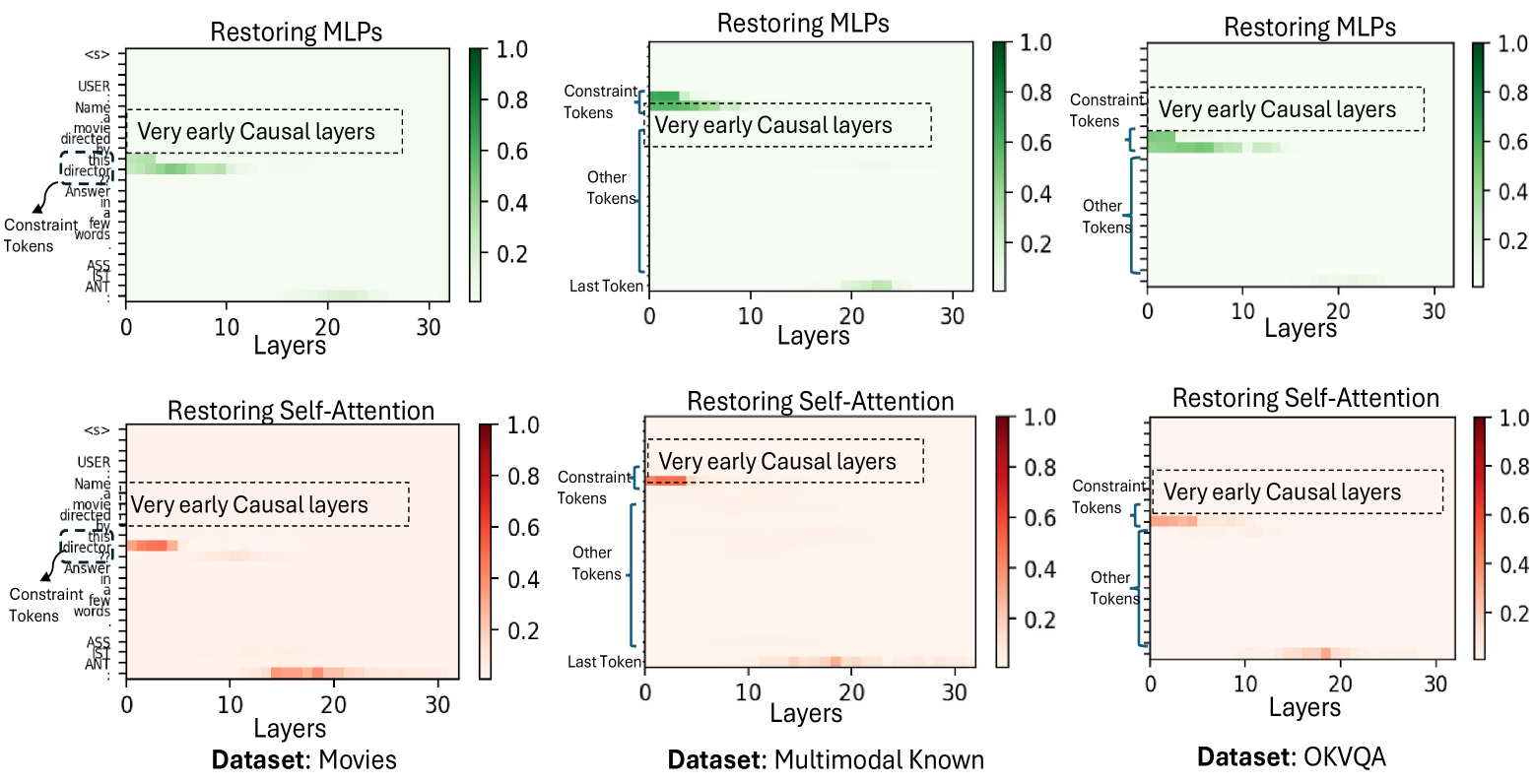
- 实验结果表明,MLLM的信息存储依赖于更早的MLP和自注意力层,并且少量视觉token负责信息传递,并通过模型编辑验证了这些机制。
📝 摘要(中文)
理解基于Transformer的模型中信息存储和传递的机制,对于推动模型理解的进展至关重要。本文将此类研究从纯语言大语言模型(LLM)扩展到多模态大语言模型(MLLM),聚焦于MLLM在事实性视觉问答任务中如何处理信息。研究采用基于约束的公式,将视觉问题视为具有一组视觉或文本约束,模型的答案必须满足这些约束才能正确。本文贡献包括:i) 一种将因果信息追踪从纯语言扩展到多模态环境的方法;ii) VQA-Constraints,一个包含9.7K个带有约束注释的视觉问题测试集。使用这些工具研究了LLaVa和多模态Phi-2两个开源MLLM。关键发现表明,与LLM相比,这些MLLM更早地依赖于MLP和自注意力模块进行信息存储。此外,少量视觉编码器输出的视觉token负责将信息从图像传递到这些因果模块。通过MultEdit模型编辑算法验证了这些机制,该算法通过定位这些因果模块来纠正错误并将新的长尾信息插入到MLLM中。
🔬 方法详解
问题定义:现有的大语言模型(LLM)信息溯源研究主要集中在纯文本领域,缺乏对多模态大语言模型(MLLM)的深入分析。MLLM在处理视觉信息时,其信息存储和传递机制与LLM可能存在差异,这限制了我们对MLLM工作原理的理解,也阻碍了针对MLLM的优化和改进。因此,本文旨在研究MLLM在视觉问答任务中如何存储和传递信息,从而更好地理解其内部机制。
核心思路:本文的核心思路是利用因果信息追踪技术,分析MLLM在处理视觉问答任务时,哪些模块和token对最终答案的生成起关键作用。通过将视觉问题分解为一系列约束条件,并追踪信息在模型中的流动路径,可以确定哪些模块负责存储相关信息,以及哪些视觉token负责将信息从图像传递到这些模块。这种方法能够揭示MLLM如何整合视觉和文本信息,并生成符合约束条件的答案。
技术框架:本文的技术框架主要包括以下几个阶段:1) 构建VQA-Constraints数据集:该数据集包含带有约束注释的视觉问题,用于评估MLLM在满足特定约束条件下的问答能力。2) 因果信息追踪:利用因果信息追踪技术,分析模型在处理视觉问题时,各个模块和token对最终答案的影响。3) 模型编辑:通过修改模型中的关键模块,验证因果信息追踪结果的有效性。4) 分析与验证:对实验结果进行分析,揭示MLLM的信息存储和传递机制。
关键创新:本文的关键创新在于将因果信息追踪技术扩展到多模态领域,并提出了一种基于约束的视觉问答分析方法。与传统的黑盒分析方法相比,本文的方法能够更深入地理解MLLM的内部工作机制,并揭示视觉信息在模型中的流动路径。此外,本文还提出了MultEdit模型编辑算法,通过修改模型中的关键模块,验证了因果信息追踪结果的有效性。
关键设计:VQA-Constraints数据集包含9.7K个视觉问题,每个问题都带有约束注释,例如“电影导演是谁?”、“这部电影获得了什么奖项?”。因果信息追踪采用类似于之前LLM研究的方法,但针对多模态场景进行了调整。MultEdit模型编辑算法通过修改模型中的MLP和自注意力模块,来纠正错误或插入新的信息。具体来说,该算法通过梯度下降的方式,调整模型参数,使得模型能够生成符合约束条件的答案。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与LLM相比,MLLM更早地依赖于MLP和自注意力模块进行信息存储。此外,研究发现少量视觉编码器输出的视觉token负责将信息从图像传递到这些因果模块。通过MultEdit模型编辑算法,成功地纠正了MLLM的错误答案,并注入了新的长尾知识,验证了因果信息追踪结果的有效性。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的可解释性和可控性,例如通过编辑模型内部的关键模块,可以纠正模型的错误答案或注入新的知识。此外,该研究还可以指导MLLM的架构设计和训练,使其更好地整合视觉和文本信息,从而提高其在视觉问答、图像描述等任务中的性能。未来,该研究有望推动开发更可靠、更智能的多模态人工智能系统。
📄 摘要(原文)
Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.