ReDistill: Residual Encoded Distillation for Peak Memory Reduction of CNNs
作者: Fang Chen, Gourav Datta, Mujahid Al Rafi, Hyeran Jeon, Meng Tang
分类: cs.CV, cs.LG
发布日期: 2024-06-06 (更新: 2025-04-25)
备注: 16 pages, 7 figures, 10 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出残差编码蒸馏(ReDistill)方法,在显著降低CNN峰值内存消耗的同时保持性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 峰值内存降低 边缘计算 残差学习 卷积神经网络 图像分类 图像生成
📋 核心要点
- 现代视觉模型参数量和图像分辨率的提升导致内存和功耗需求增加,在边缘设备部署面临挑战,降低峰值内存消耗至关重要。
- ReDistill通过激进池化构建小内存学生网络,并利用残差编码蒸馏从教师网络学习,缓解了直接下采样带来的性能下降。
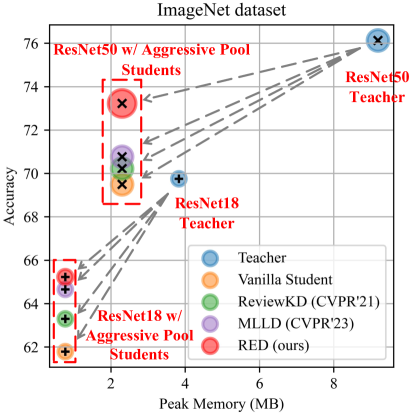
- 实验表明,ReDistill在图像分类任务中可降低4-5倍峰值内存,精度损失小;在图像生成任务中可降低4倍内存,同时保持图像质量。
📝 摘要(中文)
为了在资源受限的边缘设备上部署现代计算机视觉模型,本文提出了一种残差编码蒸馏(ReDistill)方法,旨在降低模型的峰值内存消耗。该方法基于教师-学生框架,通过激进的池化操作构建内存占用更小的学生网络,并利用残差编码蒸馏从教师网络中学习。实验表明,在图像分类任务中,ReDistill能够在大多数基于CNN的架构上实现4倍-5倍的理论峰值内存降低,同时精度损失较小。在基于扩散的图像生成任务中,该方法能够生成峰值内存降低4倍的去噪网络,并保持图像生成的多样性和保真度。实验结果表明,与其他的基于特征和基于响应的蒸馏方法相比,ReDistill在相同学生网络上的性能更优。
🔬 方法详解
问题定义:论文旨在解决卷积神经网络(CNNs)在边缘设备部署时,由于模型尺寸和高分辨率图像带来的高峰值内存消耗问题。现有方法,如通过大步长池化进行特征图下采样,虽然能降低内存消耗,但会导致网络性能的显著下降,无法满足实际应用需求。
核心思路:论文的核心思路是利用知识蒸馏,将一个高性能的教师网络中的知识迁移到一个内存占用更小的学生网络中。为了弥补激进池化带来的信息损失,论文引入了残差编码,使得学生网络能够更好地学习教师网络的特征表示。
技术框架:ReDistill方法基于教师-学生框架。首先,使用激进的池化操作(例如,更大的步长)构建一个内存占用较小的学生网络。然后,利用残差编码蒸馏损失函数,指导学生网络学习教师网络的特征表示。具体来说,教师网络的特征图经过编码器,学生网络的特征图经过解码器,目标是最小化编码器-解码器对的输出与教师网络原始特征图之间的残差。
关键创新:ReDistill的关键创新在于残差编码蒸馏损失函数的设计。传统的知识蒸馏方法通常直接匹配教师和学生的特征图,而ReDistill关注的是两者之间的残差。这种方法能够更有效地利用教师网络的信息,弥补学生网络由于激进池化带来的信息损失。
关键设计:残差编码蒸馏损失函数是该方法的核心。具体形式未知,但可以推断其目标是最小化教师网络特征图与学生网络特征图经过编码和解码后的重构误差。编码器和解码器的具体结构未知,但可能是简单的卷积层或全连接层。此外,激进池化的步长选择也是一个重要的参数,需要在内存消耗和性能之间进行权衡。
🖼️ 关键图片


📊 实验亮点
ReDistill在图像分类任务中,相较于直接使用大步长池化的学生网络,精度显著提升,同时实现了4-5倍的理论峰值内存降低。在扩散模型图像生成任务中,ReDistill生成的模型在降低4倍理论峰值内存的同时,保持了较好的图像多样性和保真度。实验结果表明,ReDistill优于其他基于特征和响应的蒸馏方法。
🎯 应用场景
ReDistill方法可广泛应用于资源受限的边缘设备上的计算机视觉任务,例如移动设备上的图像分类、目标检测和图像生成。该方法能够降低模型的内存占用,使其能够在低功耗设备上运行,从而扩展了计算机视觉技术的应用范围。此外,该方法还可以应用于云端服务器,降低模型的部署成本。
📄 摘要(原文)
The expansion of neural network sizes and the enhanced resolution of modern image sensors result in heightened memory and power demands to process modern computer vision models. In order to deploy these models in extremely resource-constrained edge devices, it is crucial to reduce their peak memory, which is the maximum memory consumed during the execution of a model. A naive approach to reducing peak memory is aggressive down-sampling of feature maps via pooling with large stride, which often results in unacceptable degradation in network performance. To mitigate this problem, we propose residual encoded distillation (ReDistill) for peak memory reduction in a teacher-student framework, in which a student network with less memory is derived from the teacher network using aggressive pooling. We apply our distillation method to multiple problems in computer vision, including image classification and diffusion-based image generation. For image classification, our method yields 4x-5x theoretical peak memory reduction with less degradation in accuracy for most CNN-based architectures. For diffusion-based image generation, our proposed distillation method yields a denoising network with 4x lower theoretical peak memory while maintaining decent diversity and fidelity for image generation. Experiments demonstrate our method's superior performance compared to other feature-based and response-based distillation methods when applied to the same student network. The code is available at https://github.com/mengtang-lab/ReDistill.