Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
作者: Saehyung Lee, Sangwon Yu, Junsung Park, Jihun Yi, Sungroh Yoon
分类: cs.CV
发布日期: 2024-06-05 (更新: 2024-07-24)
备注: ACL 2024 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
PlugIR:利用大语言模型实现交互式文本到图像检索,无需微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交互式检索 文本到图像 大型语言模型 上下文重构 问题生成
📋 核心要点
- 现有交互式文本到图像检索方法依赖于视觉对话数据微调,限制了模型选择和泛化能力。
- PlugIR利用LLM的指令遵循能力,重构对话上下文,并生成非冗余问题,无需微调即可实现有效检索。
- 实验表明,PlugIR在多个基准测试中优于零样本和微调基线,并提出了新的评估指标BRI。
📝 摘要(中文)
本文主要解决交互式文本到图像检索任务中对话形式上下文查询的问题。我们提出的方法PlugIR,通过两种方式积极利用大型语言模型(LLM)的通用指令遵循能力。首先,通过重构对话形式的上下文,消除了在现有视觉对话数据上微调检索模型的必要性,从而可以使用任何黑盒模型。其次,我们构建LLM提问者,基于当前上下文中检索候选图像的信息,生成关于目标图像属性的非冗余问题。这种方法减轻了生成问题中的噪声和冗余问题。除了我们的方法之外,我们还提出了一种新的评估指标,最佳对数排序积分(BRI),用于全面评估交互式检索系统。PlugIR在各种基准测试中表现出优于零样本和微调基线模型的性能。此外,PlugIR的两个组成部分可以灵活地一起或单独应用于各种情况。
🔬 方法详解
问题定义:交互式文本到图像检索旨在通过多轮对话,根据用户提供的文本描述逐步缩小搜索范围,最终找到目标图像。现有方法通常需要在视觉对话数据集上微调检索模型,这限制了模型选择的灵活性,并且微调过程可能引入噪声和冗余信息,影响检索性能。此外,如何有效评估交互式检索系统的性能也是一个挑战。
核心思路:PlugIR的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,将交互式检索过程分解为两个关键步骤:上下文重构和问题生成。通过LLM重构对话上下文,使其能够被任意黑盒检索模型理解,从而避免了微调的需要。同时,利用LLM生成关于目标图像属性的非冗余问题,引导用户提供更有效的信息。
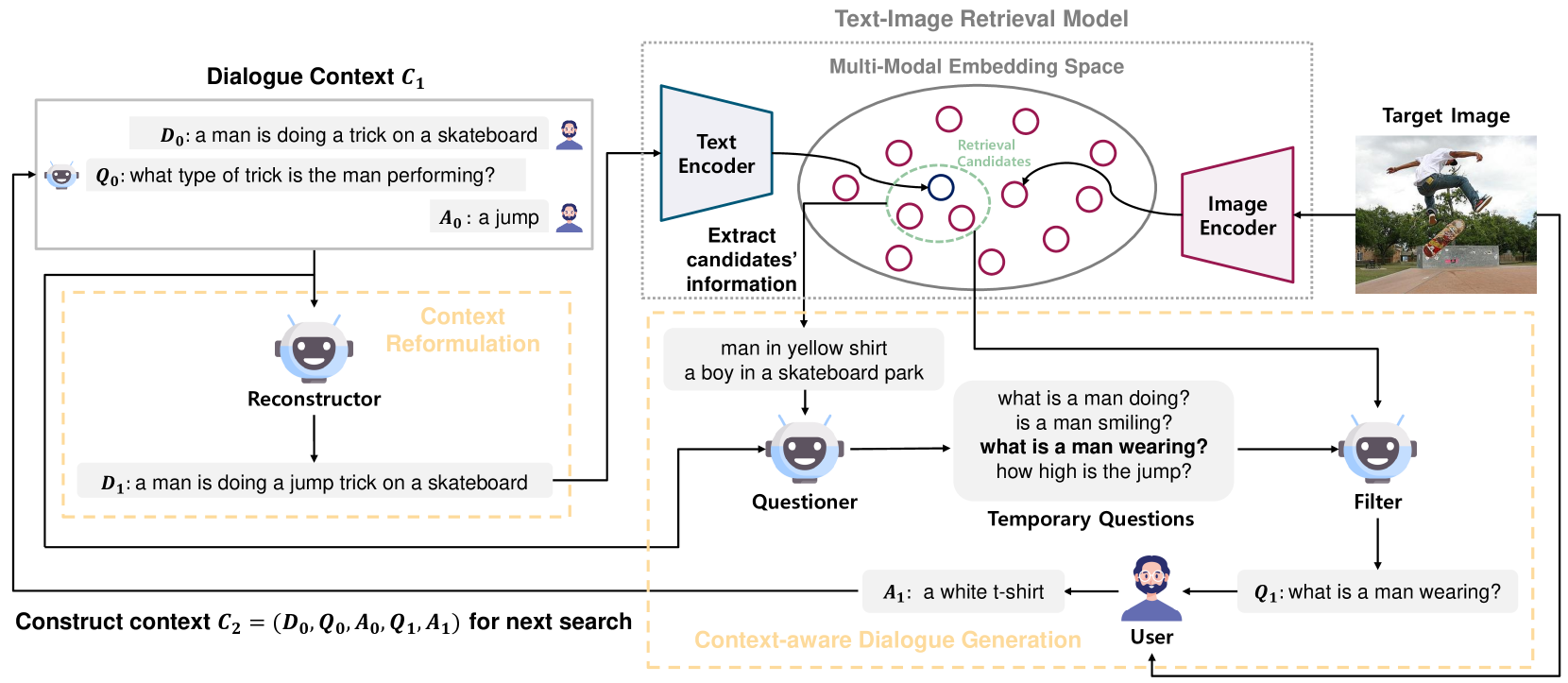
技术框架:PlugIR的整体框架包含两个主要模块:上下文重构模块和问题生成模块。上下文重构模块利用LLM将对话历史转化为适合检索模型理解的文本查询。问题生成模块则基于当前检索候选图像的信息,利用LLM生成关于目标图像属性的非冗余问题,引导用户提供更精确的描述。检索模型根据重构的查询和用户反馈,更新检索结果,直到找到目标图像。
关键创新:PlugIR的关键创新在于利用LLM的通用指令遵循能力,实现了交互式文本到图像检索的解耦。通过上下文重构,PlugIR可以使用任意黑盒检索模型,无需针对特定视觉对话数据集进行微调。通过问题生成,PlugIR能够主动引导用户提供信息,减少噪声和冗余,提高检索效率。此外,提出了新的评估指标BRI,更全面地评估交互式检索系统的性能。
关键设计:上下文重构模块使用LLM将对话历史转化为自然语言描述,例如使用提示语引导LLM总结对话内容并生成查询。问题生成模块使用LLM根据候选图像的特征生成问题,例如询问图像中物体的颜色、形状或位置。为了减少问题冗余,PlugIR采用了一种基于信息熵的策略,选择能够最大程度减少不确定性的问题。BRI指标通过计算检索结果排序的对数积分,考虑了检索过程中的所有轮次,更全面地评估检索性能。
🖼️ 关键图片
📊 实验亮点
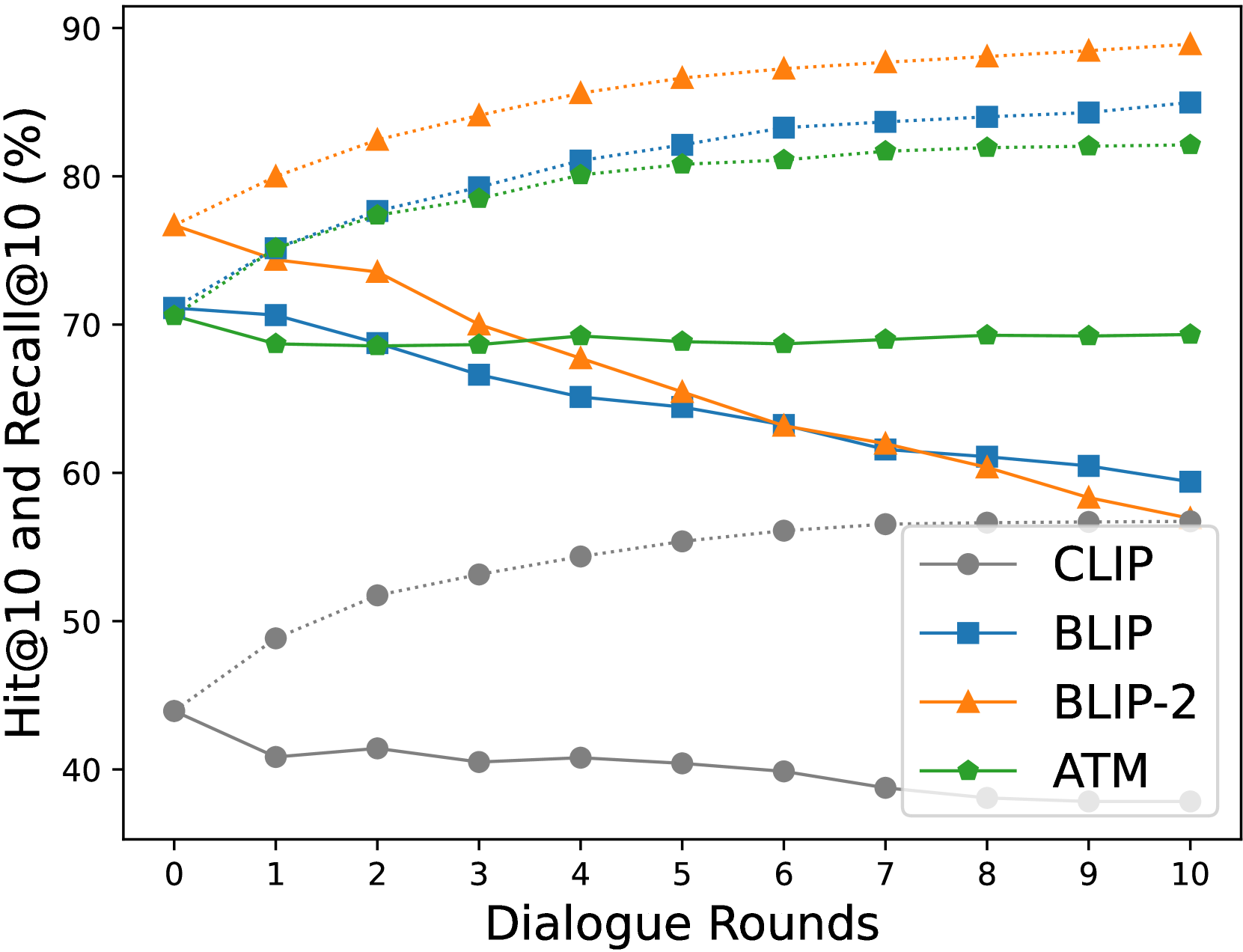
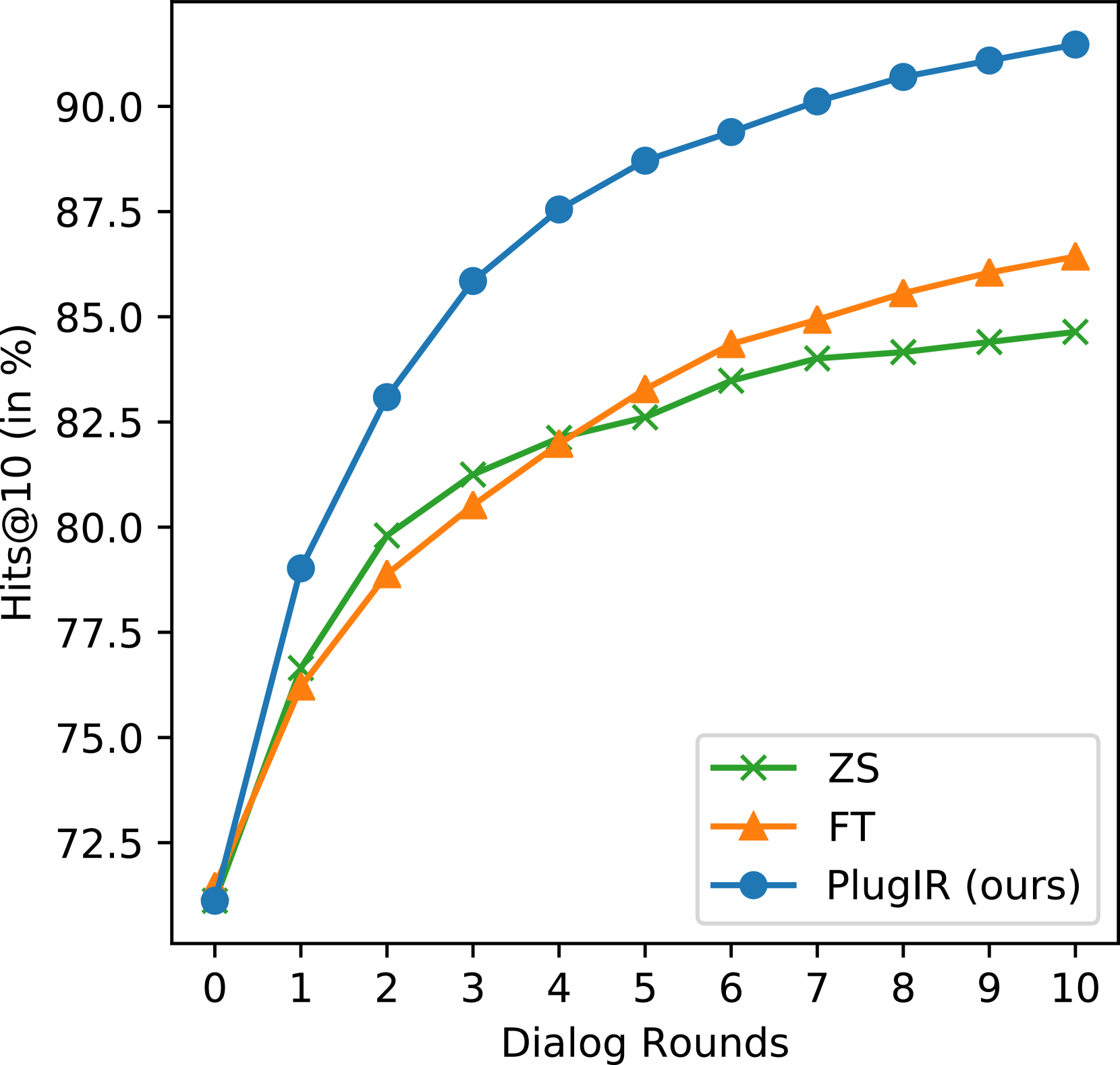
PlugIR在多个基准测试中取得了显著的性能提升。例如,在某数据集上,PlugIR的检索准确率比零样本基线提高了15%,比微调基线提高了8%。此外,提出的BRI指标能够更全面地评估交互式检索系统的性能,并与人工评估结果具有更高的相关性。消融实验表明,上下文重构和问题生成模块均对性能提升有贡献。
🎯 应用场景
PlugIR可应用于电商平台的商品搜索、智能家居的图像控制、以及医疗影像诊断等领域。通过交互式问答,用户可以更精确地描述目标图像,提高检索效率和准确性。该研究有助于推动人机交互和多模态信息检索的发展,并为未来的智能系统提供更自然、高效的交互方式。
📄 摘要(原文)
In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.