Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
作者: Risab Biswas
分类: eess.IV, cs.CV
发布日期: 2024-06-05
备注: Master's thesis
💡 一句话要点
提出多任务多尺度对比知识蒸馏,提升医学图像分割效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学图像分割 知识蒸馏 多任务学习 对比学习 多尺度特征 CT图像 深度学习
📋 核心要点
- 医学图像分割面临数据量有限的挑战,现有方法难以充分利用大型预训练模型的知识。
- 提出多任务多尺度对比知识蒸馏方法,将大型教师网络的知识迁移到小型学生网络,提升分割性能。
- 实验结果表明,该方法在有限数据下能有效提升学生模型的性能,并分析了多尺度蒸馏的重要性。
📝 摘要(中文)
本研究旨在探索神经网络之间知识迁移在医学图像分割任务中的可行性,特别关注从大型多任务“教师”网络到小型“学生”网络的知识迁移。在医学成像领域,数据量通常有限,利用大型预训练网络的知识可能很有用。主要目标是通过整合教师模型获取的知识表征来提高小型学生模型的性能,教师模型采用在CT图像上训练的多任务预训练架构,而学生网络本质上是教师模型的一个更小版本,仅使用教师模型50%的数据进行训练。为了促进两个模型之间的知识转移,我们设计了一种结合多尺度特征蒸馏和监督对比学习的架构。我们的研究旨在通过整合来自教师模型的知识表征来提高学生模型的性能。我们研究了这种方法在计算资源和训练数据可用性有限的情况下是否特别有效。为了评估多尺度特征蒸馏的影响,我们进行了广泛的实验。我们还进行了详细的消融研究,以确定在不同尺度上(包括来自编码器层的低级特征)提取知识对于有效的知识转移是否至关重要。此外,我们检查了知识蒸馏过程中的不同损失,以深入了解它们对整体性能的影响。
🔬 方法详解
问题定义:医学图像分割任务中,数据量有限是一个普遍存在的问题。直接训练小型网络难以达到理想的性能。现有方法可能无法充分利用大型预训练模型所学习到的丰富知识,尤其是在多任务学习场景下。因此,如何有效地将大型模型的知识迁移到小型模型,以提升分割精度,是一个亟待解决的问题。
核心思路:本论文的核心思路是利用知识蒸馏技术,将一个在大量数据上预训练的多任务教师网络的知识迁移到一个小型学生网络。通过多尺度特征蒸馏和监督对比学习,学生网络可以学习到教师网络更深层次的特征表示,从而在数据量有限的情况下也能获得较好的分割性能。这种方法旨在提高学生网络的效率和准确性,使其能够在资源受限的环境中应用。
技术框架:整体框架包含一个预训练的多任务教师网络和一个需要训练的学生网络。教师网络首先在大量CT图像上进行训练,学习多任务知识。然后,通过多尺度特征蒸馏模块,将教师网络不同层的特征传递给学生网络。同时,利用监督对比学习,使学生网络学习到与教师网络相似的特征表示。学生网络在少量数据上进行训练,同时受到分割损失、特征蒸馏损失和对比学习损失的约束。
关键创新:本论文的关键创新在于结合了多尺度特征蒸馏和监督对比学习,用于知识蒸馏。多尺度特征蒸馏可以使学生网络学习到教师网络不同层次的特征,从而更全面地获取知识。监督对比学习则可以使学生网络学习到与教师网络相似的特征表示,从而提高泛化能力。与传统的知识蒸馏方法相比,该方法能够更有效地利用教师网络的知识,提升学生网络的性能。
关键设计:在多尺度特征蒸馏中,选择教师网络和学生网络中对应的编码器层,计算特征之间的差异,并将其作为蒸馏损失。监督对比学习采用InfoNCE损失函数,鼓励学生网络学习到与教师网络相似的特征表示。具体的网络结构和参数设置需要根据具体的任务和数据集进行调整。损失函数的权重也需要进行实验调整,以达到最佳的性能。
🖼️ 关键图片
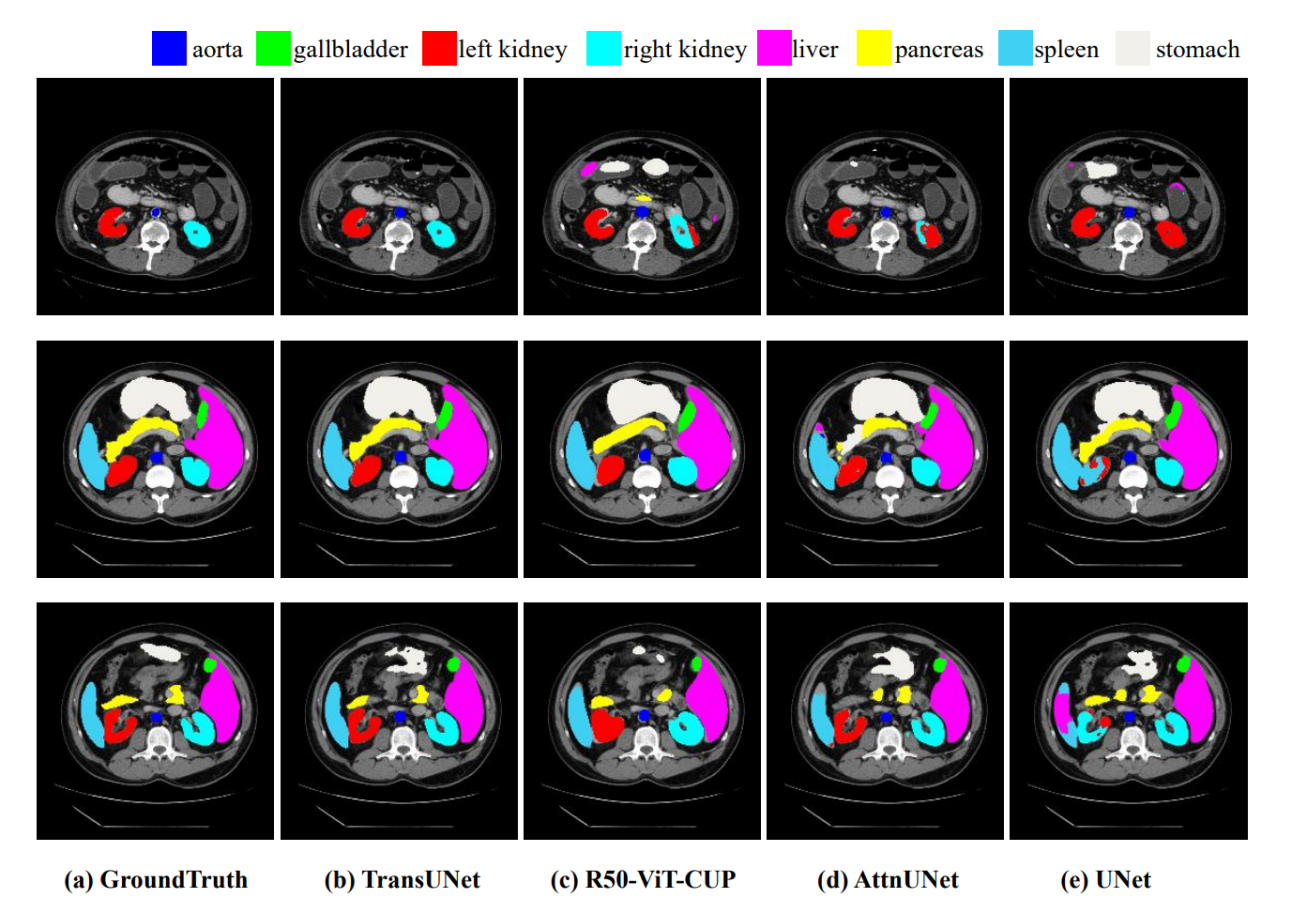
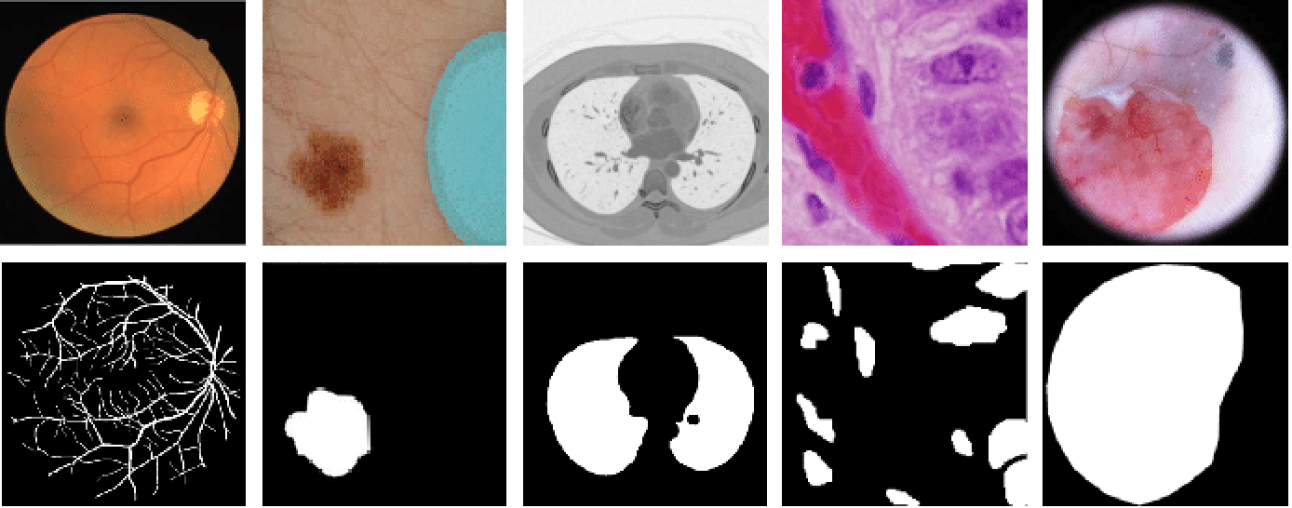
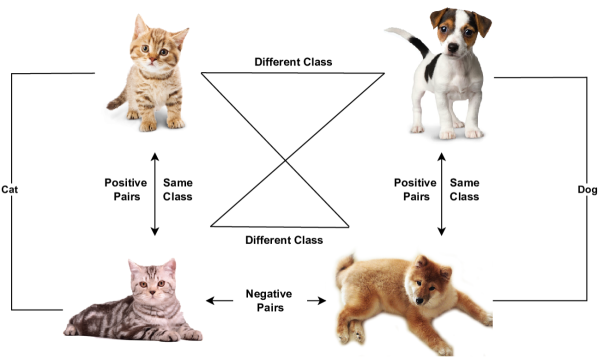
📊 实验亮点
论文通过实验验证了所提出的多任务多尺度对比知识蒸馏方法的有效性。结果表明,在仅使用教师网络50%的数据进行训练的情况下,学生网络的分割性能得到了显著提升。消融研究进一步证实了多尺度特征蒸馏的重要性,以及不同损失函数对整体性能的影响。
🎯 应用场景
该研究成果可应用于多种医学图像分割任务,例如器官分割、病灶检测等。通过知识蒸馏,可以将大型预训练模型的知识迁移到资源受限的设备上,实现高效的医学图像分析。这对于在医疗资源匮乏地区进行诊断和治疗具有重要意义,并能加速医学影像分析的智能化进程。
📄 摘要(原文)
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task "Teacher" network to a smaller "Student" network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.