Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
作者: Minglei Li, Peng Ye, Yongqi Huang, Lin Zhang, Tao Chen, Tong He, Jiayuan Fan, Wanli Ouyang
分类: cs.CV
发布日期: 2024-06-05 (更新: 2024-06-06)
💡 一句话要点
提出Adapter-X,一种高效通用视觉参数高效微调框架,超越全参数微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 Adapter 视觉Transformer 动态分配 参数共享 3D点云 图像分类
📋 核心要点
- 现有Adapter方法难以兼顾高效率和跨任务的鲁棒泛化能力,存在参数冗余和性能瓶颈。
- Adapter-X通过共享混合Adapter(SMoA)模块和块特定设计,实现token级别动态分配和参数共享。
- 实验表明,Adapter-X在2D图像和3D点云分类任务上,以极少参数超越全参数微调。
📝 摘要(中文)
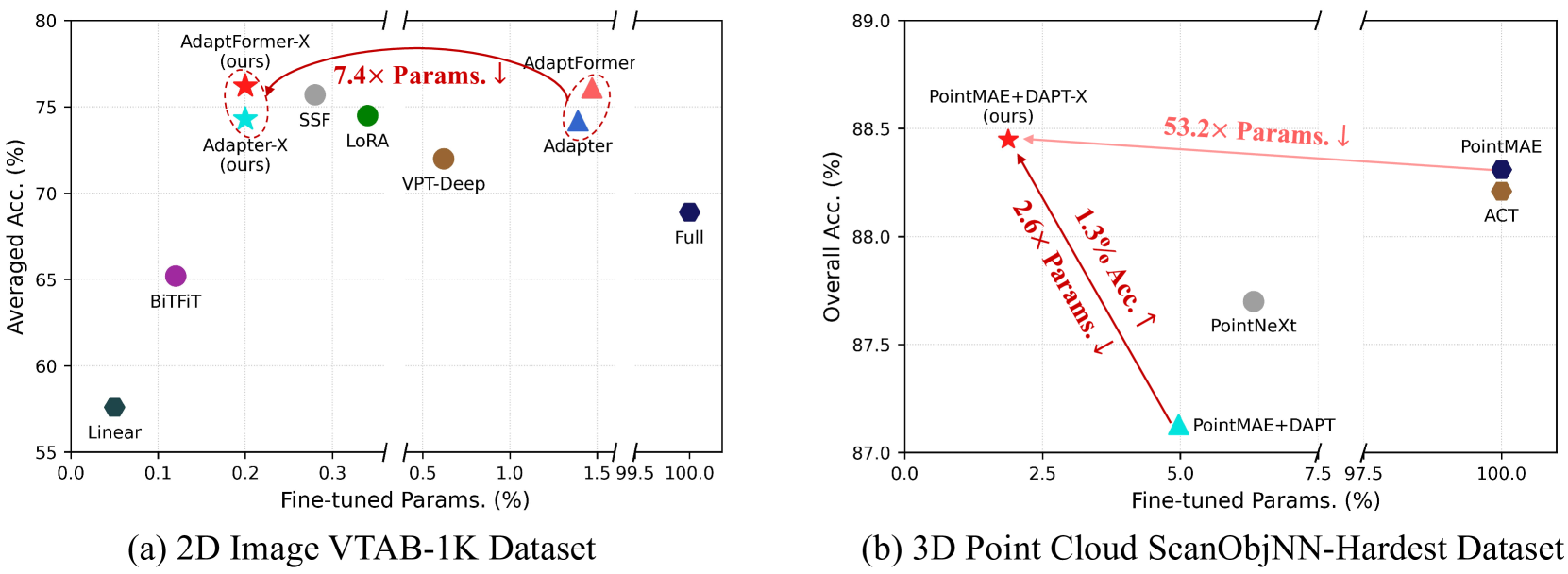
随着基础模型在流行度和规模上的持续增长,参数高效微调(PEFT)变得越来越重要。Adapter因其在参数减少和跨任务适应性方面的潜力而备受欢迎。然而,对于基于Adapter的方法来说,在高效率和跨任务的鲁棒泛化之间取得平衡仍然是一个挑战。我们分析了现有方法,发现:1)参数共享是减少冗余的关键;2)更多可调参数、动态分配和块特定设计是提高性能的关键。遗憾的是,之前的工作没有考虑到所有这些因素。受此启发,我们引入了一种名为Adapter-X的新框架。首先,提出了一种共享混合Adapter(SMoA)模块,以同时实现token级别的动态分配、增加的可调参数和块间共享。其次,引入了一些块特定的设计,如Prompt Generator(PG),以进一步增强适应能力。在2D图像和3D点云模态上的大量实验表明,Adapter-X代表着一个重要的里程碑,因为它首次在2D图像和3D点云模态上以显著更少的参数优于全参数微调,即对于2D和3D分类任务,分别仅为原始可训练参数的0.20%和1.88%。我们的代码将公开提供。
🔬 方法详解
问题定义:现有参数高效微调方法,特别是基于Adapter的方法,在效率和泛化能力之间难以平衡。它们要么参数冗余,导致效率低下;要么可调参数不足,限制了模型性能,无法充分适应不同任务。因此,如何设计一种既高效又具有强大泛化能力的Adapter成为关键问题。
核心思路:Adapter-X的核心思路是结合参数共享、动态分配和块特定设计,以提高Adapter的效率和性能。通过参数共享减少冗余,增加可调参数提升模型容量,动态分配实现token级别的自适应调整,块特定设计针对不同层级的特征进行优化。
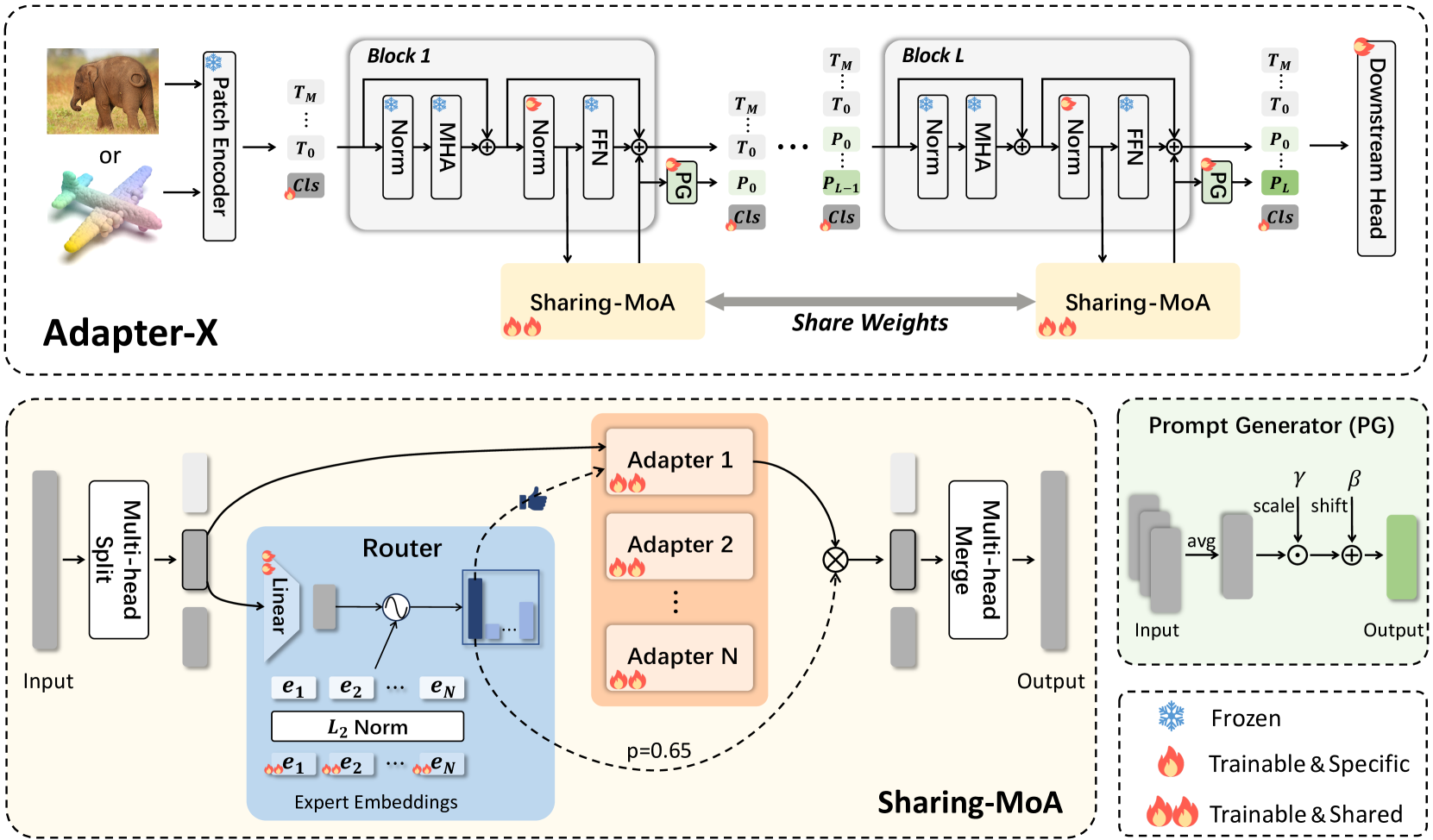
技术框架:Adapter-X框架主要包含两个核心模块:Sharing Mixture of Adapters (SMoA) 和 Prompt Generator (PG)。SMoA模块负责在不同Adapter之间共享参数,并根据输入token动态分配Adapter权重。PG模块则作为块特定设计,用于生成针对特定block的prompt,以增强模型的适应能力。整体流程是在Transformer的每个block中插入SMoA模块和PG模块,然后进行微调。
关键创新:Adapter-X的关键创新在于SMoA模块,它通过混合多个共享参数的Adapter,实现了token级别的动态分配和参数共享。与传统的Adapter方法相比,SMoA模块能够更有效地利用参数,并根据输入token的特征自适应地调整Adapter的权重,从而提高模型的性能。
关键设计:SMoA模块的关键设计包括:1)Adapter的共享参数结构;2)动态分配权重的计算方式,通常使用一个小型神经网络;3)混合Adapter的数量。PG模块的关键设计在于prompt的生成方式和注入位置,通常使用一个小型MLP生成prompt,并将其添加到输入特征中。
🖼️ 关键图片

📊 实验亮点
Adapter-X在2D图像和3D点云分类任务上均取得了显著的性能提升。在2D图像分类任务中,仅使用0.20%的原始可训练参数,Adapter-X就超越了全参数微调的性能。在3D点云分类任务中,使用1.88%的参数也超越了全参数微调。这些结果表明Adapter-X在参数效率和性能方面具有显著优势。
🎯 应用场景
Adapter-X适用于各种视觉任务,如图像分类、目标检测、语义分割等,尤其是在资源受限的场景下,例如移动设备或嵌入式系统。它还可以应用于3D点云数据的处理,为自动驾驶、机器人等领域提供更高效的模型微调方案。该研究有望推动参数高效微调技术的发展,降低模型部署成本,加速AI技术的普及。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.