Enhancing Multimodal Large Language Models with Multi-instance Visual Prompt Generator for Visual Representation Enrichment
作者: Wenliang Zhong, Wenyi Wu, Qi Li, Rob Barton, Boxin Du, Shioulin Sam, Karim Bouyarmane, Ismail Tutar, Junzhou Huang
分类: cs.CV
发布日期: 2024-06-05
💡 一句话要点
提出多示例视觉提示生成器MIVPG,增强多模态大语言模型中的视觉表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉语言任务 多示例学习 视觉提示生成 Q-former 视觉表征 实例相关性
📋 核心要点
- 现有MLLM使用Q-former等适配器进行视觉表征融合,但忽略了图像实例间的异质性和相关性,限制了性能。
- 提出多示例视觉提示生成器(MIVPG),利用图像或patch间的实例相关性,生成更丰富的视觉表征,提升MLLM性能。
- 在三个视觉语言数据集上的实验表明,MIVPG能够有效提升Q-former在主流视觉语言任务上的表现。
📝 摘要(中文)
多模态大语言模型(MLLMs)通过融合视觉表征和LLMs,并借助一些视觉适配器,在各种视觉语言任务中取得了SOTA性能。本文首先指出,使用基于查询的Transformer(如Q-former)的适配器是一种简化的多示例学习方法,没有考虑实例异质性/相关性。然后,我们提出了一个通用组件,称为多示例视觉提示生成器(MIVPG),通过利用同一样本的图像或patch之间的实例相关性,将丰富的视觉表征整合到LLMs中。在来自不同场景的三个公共视觉语言(VL)数据集上的定量评估表明,所提出的MIVPG改进了Q-former在主要VL任务中的性能。
🔬 方法详解
问题定义:现有的多模态大语言模型在处理视觉信息时,通常使用基于查询的Transformer(如Q-former)作为视觉适配器。这种方法将视觉信息编码为一系列查询向量,然后与语言模型进行交互。然而,这种方法忽略了图像内部不同区域(或patch)之间的异质性和相关性。例如,图像的不同部分可能包含不同的语义信息,而这些信息之间存在复杂的关联。现有方法将所有patch视为独立的个体,未能充分利用这些关联,导致视觉表征不够丰富,限制了模型的性能。
核心思路:本文的核心思路是引入多示例学习的思想,将图像视为一个包含多个实例(例如,图像patch)的集合。通过学习实例之间的相关性,生成更具判别性和鲁棒性的视觉表征。具体来说,论文提出了一个多示例视觉提示生成器(MIVPG),该生成器能够根据图像中不同patch之间的关系,生成一组视觉提示,这些提示能够更好地表达图像的整体语义信息。
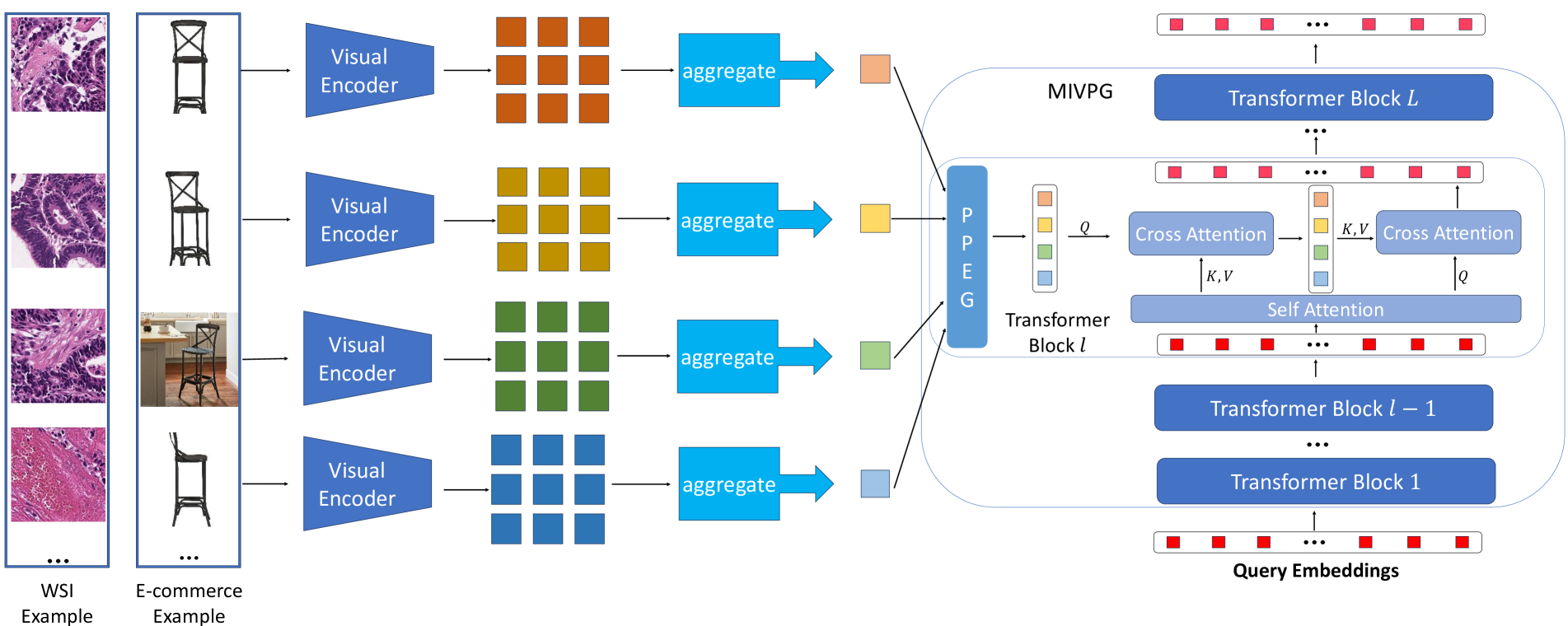
技术框架:MIVPG的整体框架可以概括为以下几个步骤:1) 特征提取:使用预训练的视觉模型(例如,ViT)提取图像patch的特征。2) 实例关系建模:使用Transformer或其他关系建模模块,学习patch之间的相关性。3) 提示生成:根据学习到的patch关系,生成一组视觉提示。这些提示可以是向量、图像patch或其他形式的视觉信息。4) 提示融合:将生成的视觉提示与语言模型的输入进行融合,从而增强语言模型对视觉信息的理解。
关键创新:MIVPG的关键创新在于它将多示例学习的思想引入到多模态大语言模型中,并设计了一个能够有效学习实例关系的提示生成器。与现有方法相比,MIVPG能够更好地利用图像内部的信息,生成更丰富的视觉表征。此外,MIVPG是一个通用的组件,可以与不同的视觉模型和语言模型进行组合,具有很强的灵活性和可扩展性。
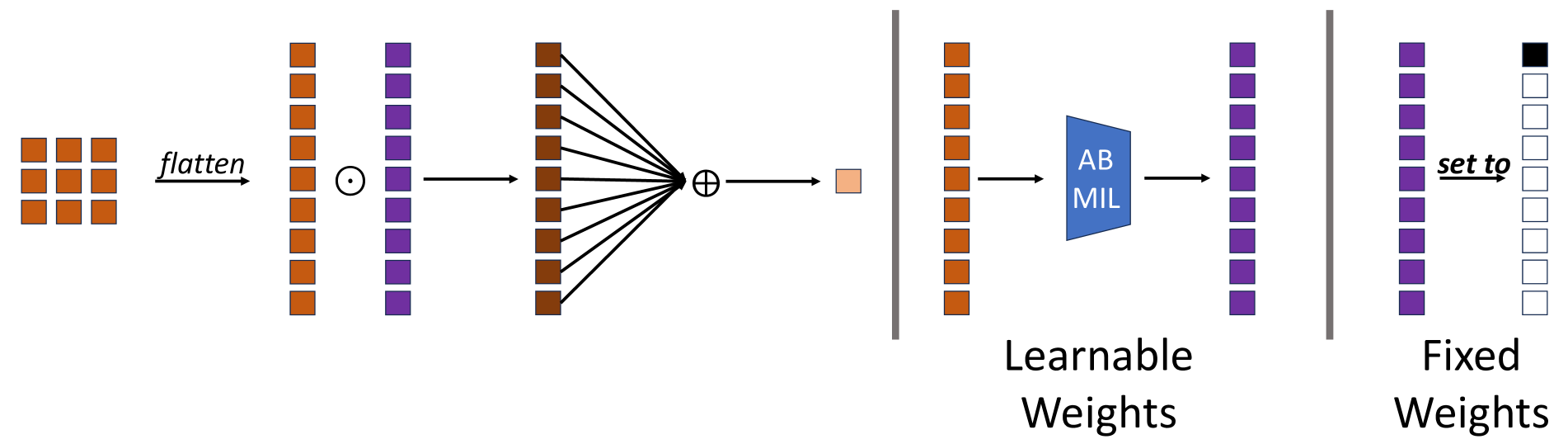
关键设计:MIVPG的关键设计包括:1) 关系建模模块:可以使用Transformer、图神经网络或其他关系建模模块来学习patch之间的相关性。论文中具体使用的关系建模模块的细节未知。2) 提示生成策略:可以使用不同的策略来生成视觉提示,例如,可以选择最具代表性的patch作为提示,或者生成一组能够概括图像整体语义信息的向量。3) 提示融合方式:可以使用不同的方式将视觉提示与语言模型的输入进行融合,例如,可以将提示直接添加到语言模型的输入中,或者使用注意力机制来引导语言模型关注重要的视觉信息。具体使用的提示生成策略和融合方式未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的MIVPG能够有效提升Q-former在视觉语言任务上的性能。在三个公共视觉语言数据集上的定量评估显示,MIVPG在图像描述、视觉问答等任务上均取得了显著的提升。具体的性能数据和提升幅度在论文中给出,但此处未知。
🎯 应用场景
该研究成果可广泛应用于视觉语言任务,如图像描述、视觉问答、视觉推理等。通过增强多模态大语言模型对视觉信息的理解能力,可以提升这些任务的性能,并为智能机器人、自动驾驶、智能医疗等领域提供更强大的技术支持。未来,该方法有望扩展到更多模态数据的融合,实现更通用的人工智能系统。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved SOTA performance in various visual language tasks by fusing the visual representations with LLMs leveraging some visual adapters. In this paper, we first establish that adapters using query-based Transformers such as Q-former is a simplified Multi-instance Learning method without considering instance heterogeneity/correlation. We then propose a general component termed Multi-instance Visual Prompt Generator (MIVPG) to incorporate enriched visual representations into LLMs by taking advantage of instance correlation between images or patches for the same sample. Quantatitive evaluation on three public vision-language (VL) datasets from different scenarios shows that the proposed MIVPG improves Q-former in main VL tasks.