Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
作者: Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan
分类: cs.CV
发布日期: 2024-06-04 (更新: 2025-02-13)
备注: ICLR 2025 (Oral)
💡 一句话要点
提出Open-YOLO 3D,利用2D检测加速开放词汇3D实例分割。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D实例分割 开放词汇 2D目标检测 多视角几何 机器人视觉
📋 核心要点
- 现有开放词汇3D实例分割方法依赖3D CLIP特征,计算成本高昂,限制了其在实时应用中的部署。
- Open-YOLO 3D利用2D目标检测,生成类别无关的3D掩码并与文本提示关联,避免了对复杂3D特征的依赖。
- 实验表明,Open-YOLO 3D在ScanNet200等数据集上实现了SOTA性能,推理速度提升高达16倍。
📝 摘要(中文)
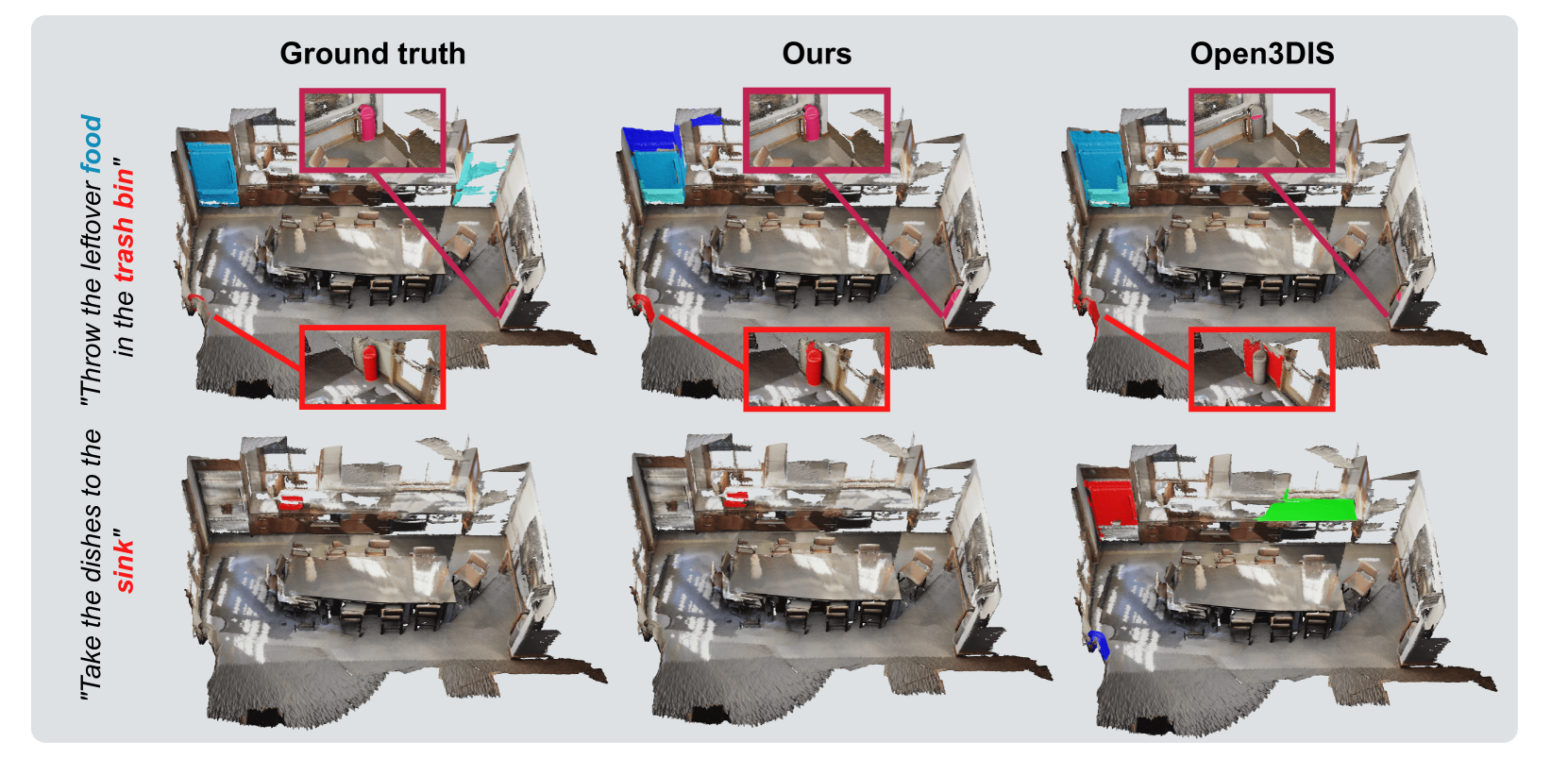
本文提出了一种快速且准确的开放词汇3D实例分割方法,名为Open-YOLO 3D。该方法仅利用多视角RGB图像的2D目标检测,有效实现了开放词汇3D实例分割。通过生成场景中物体的类别无关3D掩码,并将它们与文本提示相关联来解决此任务。作者观察到类别无关的3D点云实例投影已经包含了实例信息,因此使用SAM可能会导致冗余,并增加不必要的推理时间。实验结果表明,使用2D目标检测器可以更快地实现文本提示与3D掩码的更好匹配。在ScanNet200和Replica数据集上验证了Open-YOLO 3D的有效性。实验包括两种场景:(i)使用ground truth掩码,需要为给定的对象提议分配标签,以及(ii)使用从3D提议网络生成的类别无关3D提议。Open-YOLO 3D在两个数据集上均实现了最先进的性能,并且与现有最佳方法相比,速度提高了约16倍。在ScanNet200验证集上,Open-YOLO 3D实现了24.7%的平均精度均值(mAP),同时每场景运行时间为22秒。
🔬 方法详解
问题定义:现有的开放词汇3D实例分割方法,例如依赖3D CLIP特征的方法,计算量巨大,推理速度慢,难以满足实时应用的需求。这些方法通常需要使用Segment Anything (SAM) 和 CLIP 等计算密集型的2D基础模型进行多视角聚合,从而提取3D特征,这成为了性能瓶颈。
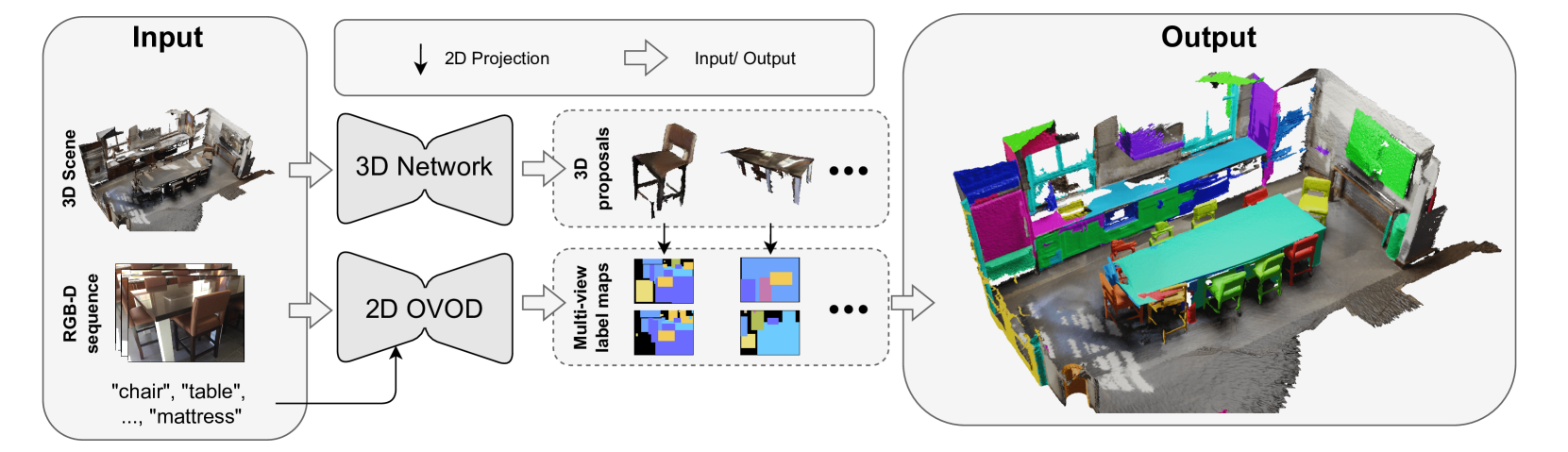
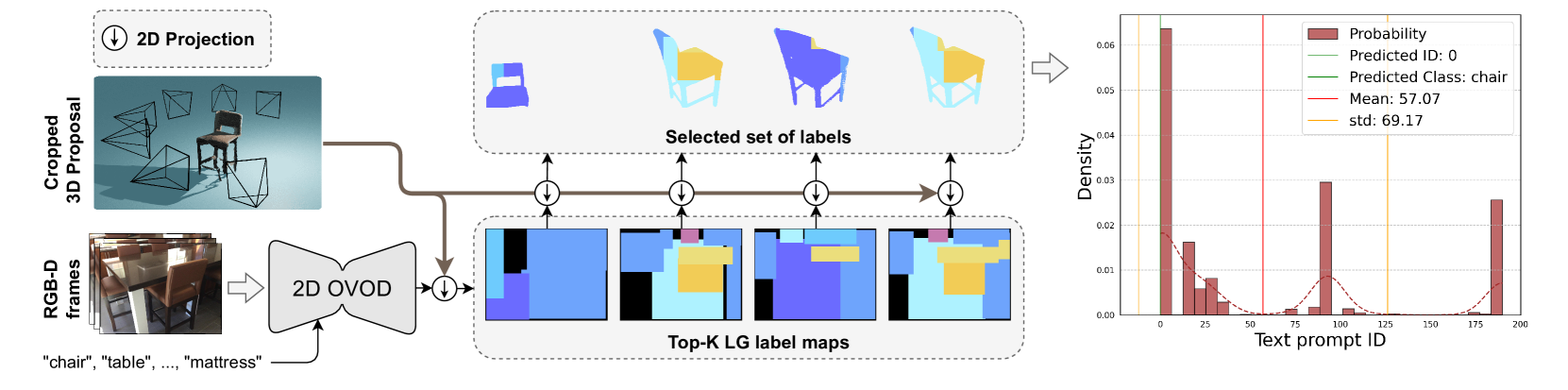
核心思路:Open-YOLO 3D的核心思路是利用2D目标检测的结果,直接生成类别无关的3D掩码,并将其与文本提示进行匹配。作者认为,3D点云实例的投影已经包含了足够的实例信息,因此避免使用复杂的3D特征提取,可以显著提高推理速度。
技术框架:Open-YOLO 3D的整体框架包含以下几个主要步骤:1) 从多视角RGB图像中提取2D目标检测结果;2) 基于2D检测结果生成类别无关的3D掩码;3) 将3D掩码与文本提示进行匹配,从而实现开放词汇的3D实例分割。该框架避免了对复杂3D特征的依赖,从而实现了更快的推理速度。
关键创新:Open-YOLO 3D最重要的创新点在于,它将2D目标检测与3D实例分割相结合,避免了对计算密集型的3D特征提取的依赖。通过直接利用2D检测结果生成3D掩码,并与文本提示进行匹配,实现了快速且准确的开放词汇3D实例分割。
关键设计:Open-YOLO 3D的关键设计包括:1) 使用2D目标检测器(具体型号未知)提取多视角图像中的目标;2) 设计了一种方法(具体细节未知)将2D检测结果投影到3D空间,生成类别无关的3D掩码;3) 使用文本编码器(具体型号未知)对文本提示进行编码,并设计了一种相似度度量方法(具体细节未知)来匹配3D掩码和文本提示。
🖼️ 关键图片
📊 实验亮点
Open-YOLO 3D在ScanNet200验证集上实现了24.7%的mAP,同时每场景运行时间为22秒。与现有最佳方法相比,推理速度提高了约16倍。这些结果表明,Open-YOLO 3D在保证精度的同时,显著提高了推理速度,使其更适用于实际应用。
🎯 应用场景
Open-YOLO 3D在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以用于快速识别和分割场景中的各种物体,从而帮助机器人更好地理解周围环境,并做出相应的决策。该方法的高效性使其能够应用于资源受限的移动设备,促进相关技术的普及。
📄 摘要(原文)
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $\sim$16$\times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7\% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.