Towards Practical Single-shot Motion Synthesis
作者: Konstantinos Roditakis, Spyridon Thermos, Nikolaos Zioulis
分类: cs.CV, cs.AI, cs.GR, cs.LG
发布日期: 2024-06-03 (更新: 2024-06-04)
备注: CVPR 2024, AI for 3D Generation Workshop, Project page: https://moverseai.github.io/single-shot
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出一种加速GAN训练的单样本运动合成方法,提升训练效率。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 单样本生成 运动合成 生成对抗网络 GAN训练加速 迁移学习
📋 核心要点
- 现有文本提示生成方法需要大量数据和计算资源,且存在知识产权和隐私问题。
- 通过单样本无条件生成,解决数据依赖问题,本文聚焦于加速单样本运动生成的GAN训练。
- 通过损失函数权重退火和迁移学习,提升GAN的训练速度和性能,并在Mixamo数据集上验证。
📝 摘要(中文)
本文致力于单样本运动生成,重点在于加速生成对抗网络(GAN)的训练时间。针对使用小批量训练时GAN的平衡崩溃问题,通过精心调整损失函数的权重来防止模式崩溃。此外,对生成器和判别器模型进行统计分析,以识别训练阶段之间的相关性,从而实现迁移学习。改进后的GAN在Mixamo基准测试中实现了与原始GAN架构和单样本扩散模型相比具有竞争力的质量和多样性,同时训练时间分别加快了6.8倍和1.75倍。最后,证明了改进后的GAN能够通过单次前向传播混合和组合运动。
🔬 方法详解
问题定义:论文旨在解决单样本运动生成中,GAN训练时间过长的问题。现有GAN在小批量训练时容易发生模式崩溃,导致生成结果质量下降,且训练效率低下。
核心思路:论文的核心思路是通过改进GAN的训练策略,使其在单样本条件下能够更快地收敛,并生成高质量的运动序列。具体来说,通过动态调整损失函数权重来避免模式崩溃,并利用统计分析实现跨阶段的迁移学习。
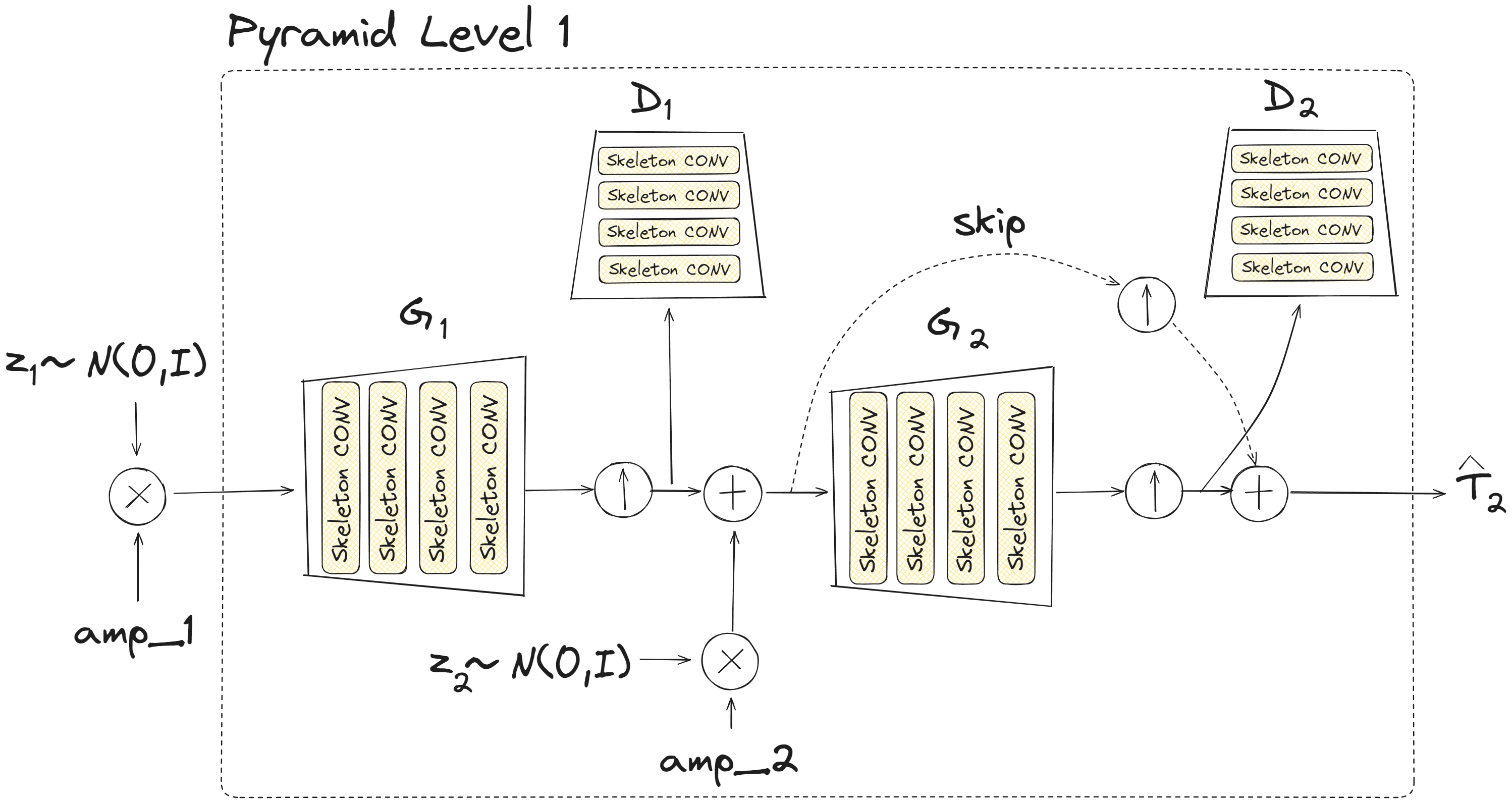
技术框架:该方法基于GAN架构,包含生成器和判别器两个主要模块。生成器负责生成运动序列,判别器负责区分生成的运动序列和真实运动序列。训练过程中,通过对抗训练不断优化生成器和判别器的性能。此外,引入了损失函数权重退火机制和迁移学习策略。
关键创新:论文的关键创新在于:1) 提出了一种损失函数权重退火机制,通过动态调整损失函数的权重,有效地避免了模式崩溃;2) 通过对生成器和判别器进行统计分析,识别训练阶段之间的相关性,实现了迁移学习,从而加速了训练过程。
关键设计:损失函数权重退火机制:根据训练的进度,动态调整用于防止模式崩溃的损失函数的权重。迁移学习策略:在不同的训练阶段,利用统计分析的结果,将已经训练好的模型参数迁移到新的模型中。具体的网络结构和参数设置在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,改进后的GAN在Mixamo基准测试中,与原始GAN架构相比,训练时间缩短了6.8倍,与单样本扩散模型相比,训练时间缩短了1.75倍。同时,在运动质量和多样性方面,改进后的GAN也达到了具有竞争力的水平。
🎯 应用场景
该研究成果可应用于游戏开发、动画制作、虚拟现实等领域,能够快速生成逼真自然的运动序列,降低内容创作成本,提高开发效率。未来,该技术有望进一步扩展到其他类型的单样本生成任务中,例如单样本图像生成、单样本语音生成等。
📄 摘要(原文)
Despite the recent advances in the so-called "cold start" generation from text prompts, their needs in data and computing resources, as well as the ambiguities around intellectual property and privacy concerns pose certain counterarguments for their utility. An interesting and relatively unexplored alternative has been the introduction of unconditional synthesis from a single sample, which has led to interesting generative applications. In this paper we focus on single-shot motion generation and more specifically on accelerating the training time of a Generative Adversarial Network (GAN). In particular, we tackle the challenge of GAN's equilibrium collapse when using mini-batch training by carefully annealing the weights of the loss functions that prevent mode collapse. Additionally, we perform statistical analysis in the generator and discriminator models to identify correlations between training stages and enable transfer learning. Our improved GAN achieves competitive quality and diversity on the Mixamo benchmark when compared to the original GAN architecture and a single-shot diffusion model, while being up to x6.8 faster in training time from the former and x1.75 from the latter. Finally, we demonstrate the ability of our improved GAN to mix and compose motion with a single forward pass. Project page available at https://moverseai.github.io/single-shot.