Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
作者: Takayuki Kanai, Igor Vasiljevic, Vitor Guizilini, Kazuhiro Shintani
分类: cs.CV, cs.RO
发布日期: 2024-06-03 (更新: 2025-09-28)
备注: Project page: https://toyotafrc.github.io/SGInit-Proj/
期刊: The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
💡 一句话要点
提出自监督几何引导初始化,提升单目视觉里程计在复杂场景下的鲁棒性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目视觉里程计 自监督学习 深度估计 稠密SLAM 几何初始化
📋 核心要点
- 传统单目视觉里程计在光照变化、纹理不足或剧烈运动时容易失效,限制了其在复杂环境中的应用。
- 利用预训练的单目深度估计器,为稠密Bundle Adjustment提供几何先验初始化,提升了SLAM的鲁棒性。
- 实验表明,该方法在KITTI和DDAD等数据集上显著提升了视觉里程计的性能,无需对SLAM骨干网络进行微调。
📝 摘要(中文)
单目视觉里程计是各种自主系统的关键技术。传统的基于特征的方法容易因光照不足、纹理缺失和大运动而失效。相比之下,最近基于学习的稠密SLAM方法利用迭代稠密Bundle Adjustment来解决这些失效情况,并在各种真实环境中实现鲁棒和精确的定位,而无需依赖于特定领域的监督。然而,尽管具有潜力,这些方法仍然难以应对涉及大运动和物体动态的场景。本研究通过分析户外基准上的主要失效案例,揭示了流行的基于学习的稠密SLAM模型(DROID-SLAM)的关键弱点及其优化过程的各种缺陷。然后,我们提出使用自监督先验,利用冻结的大规模预训练单目深度估计器来初始化稠密Bundle Adjustment过程,从而实现鲁棒的视觉里程计,而无需微调SLAM骨干网络。尽管方法简单,但所提出的方法在KITTI里程计以及具有挑战性的DDAD基准上都表现出显著的改进。
🔬 方法详解
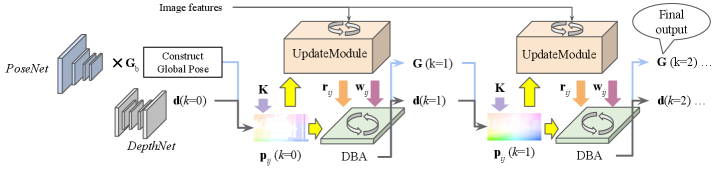
问题定义:论文旨在解决单目视觉里程计在复杂场景下,尤其是在存在大运动和动态物体时鲁棒性不足的问题。现有的基于学习的稠密SLAM方法,如DROID-SLAM,虽然在一定程度上缓解了传统方法的缺陷,但在这些场景下仍然容易失效,其优化过程存在各种缺陷。
核心思路:论文的核心思路是利用自监督学习得到的深度先验信息来引导稠密Bundle Adjustment的初始化过程。通过使用一个冻结的、大规模预训练的单目深度估计器,为SLAM系统提供一个相对准确的初始几何估计,从而避免优化过程陷入局部最小值,提高鲁棒性。
技术框架:该方法主要包含以下几个阶段:1) 使用预训练的单目深度估计器预测当前帧的深度图;2) 将预测的深度图转换为点云,并将其作为稠密Bundle Adjustment的初始几何估计;3) 使用DROID-SLAM进行后续的优化和位姿估计。整个框架的关键在于利用深度先验信息来约束优化过程,提高其稳定性和准确性。
关键创新:该方法最重要的创新点在于将自监督学习得到的深度先验信息引入到稠密SLAM的初始化过程中。与传统的随机初始化或基于特征的初始化方法相比,这种方法能够提供更准确的初始几何估计,从而显著提高SLAM系统的鲁棒性。此外,该方法无需对SLAM骨干网络进行微调,具有很强的通用性和易用性。
关键设计:该方法的关键设计包括:1) 选择一个性能良好的大规模预训练单目深度估计器,以保证深度先验信息的准确性;2) 将深度图转换为点云时,需要考虑深度值的尺度问题,并进行适当的尺度调整;3) 在Bundle Adjustment过程中,可以引入深度先验信息的约束,例如通过添加深度残差项来约束优化过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在KITTI里程计数据集上取得了显著的性能提升,尤其是在具有挑战性的序列中。此外,在DDAD数据集上的实验也验证了该方法在动态环境下的鲁棒性。与原始的DROID-SLAM相比,该方法在定位精度和鲁棒性方面均有明显改善,且无需对SLAM骨干网络进行微调。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、增强现实等领域。通过提高单目视觉里程计在复杂环境下的鲁棒性,可以提升机器人在未知环境中的自主导航能力,增强AR/VR应用的沉浸感和稳定性,并为自动驾驶系统提供更可靠的定位信息。未来,该方法有望进一步扩展到多目视觉和视觉惯性融合SLAM系统中。
📄 摘要(原文)
Monocular visual odometry is a key technology in various autonomous systems. Traditional feature-based methods suffer from failures due to poor lighting, insufficient texture, and large motions. In contrast, recent learning-based dense SLAM methods exploit iterative dense bundle adjustment to address such failure cases, and achieve robust and accurate localization in a wide variety of real environments, without depending on domain-specific supervision. However, despite its potential, the methods still struggle with scenarios involving large motion and object dynamics. In this study, we diagnose key weaknesses in a popular learning-based dense SLAM model (DROID-SLAM) by analyzing major failure cases on outdoor benchmarks and exposing various shortcomings of its optimization process. We then propose the use of self-supervised priors leveraging a frozen large-scale pre-trained monocular depth estimator to initialize the dense bundle adjustment process, leading to robust visual odometry without the need to fine-tune the SLAM backbone. Despite its simplicity, the proposed method demonstrates significant improvements on KITTI odometry, as well as the challenging DDAD benchmark.