RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
作者: Jiaben Chen, Xin Yan, Yihang Chen, Siyuan Cen, Zixin Wang, Qinwei Ma, Haoyu Zhen, Kaizhi Qian, Lie Lu, Chuang Gan
分类: cs.CV, cs.SD, eess.AS
发布日期: 2024-05-30 (更新: 2025-12-14)
备注: ICCV 2025, Project website: https://jiabenchen.github.io/RapVerse/
💡 一句话要点
RapVerse:提出一种从文本生成连贯歌声和全身动作的统一框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成 歌声生成 动作生成 多模态融合 Transformer VQ-VAE 人机交互
📋 核心要点
- 现有方法通常孤立地处理歌声和人体动作生成,缺乏两者之间的内在联系。
- 提出RapVerse框架,通过统一的多模态Transformer建模,实现文本到歌声和全身动作的连贯生成。
- 实验表明,该框架在联合生成任务上表现出色,甚至可以与单模态生成系统相媲美。
📝 摘要(中文)
本文提出了一项具有挑战性的任务,即直接从文本歌词输入同时生成3D全身动作和歌唱声音,超越了通常孤立地处理这两种模态的现有工作。为此,我们首先收集了RapVerse数据集,这是一个包含同步说唱声音、歌词和高质量3D全身网格的大型数据集。利用RapVerse数据集,我们研究了在语言、音频和运动上扩展自回归多模态Transformer,在多大程度上可以增强歌声和全身人体动作的连贯和逼真生成。对于模态统一,采用矢量量化变分自编码器将全身运动序列编码为离散运动token,同时利用语音到单元模型获得保留内容、韵律信息和歌手身份的量化音频token。通过以统一的方式对这三种模态进行联合Transformer建模,我们的框架确保了歌声和人体动作的无缝和逼真融合。大量实验表明,我们的统一生成框架不仅可以直接从文本输入生成连贯逼真的歌声以及人体动作,而且可以与专门的单模态生成系统的性能相媲美,为联合歌声-运动生成建立新的基准。
🔬 方法详解
问题定义:现有方法通常将歌声和人体动作生成视为独立的任务,忽略了它们之间的内在联系和相互影响。这导致生成的歌声和动作缺乏协调性和真实感。因此,本文旨在解决如何从文本歌词输入同时生成连贯的3D全身动作和歌唱声音的问题。
核心思路:本文的核心思路是利用统一的多模态Transformer模型,将文本、音频和运动三种模态的信息进行融合,从而实现歌声和动作的协同生成。通过共享的Transformer架构,模型可以学习到不同模态之间的依赖关系,从而生成更连贯和逼真的结果。
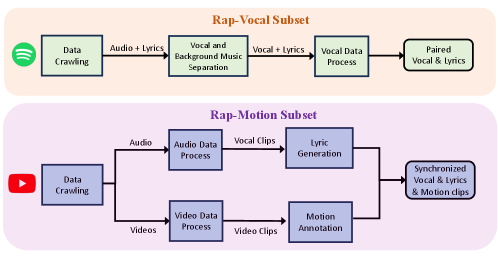
技术框架:RapVerse框架包含以下主要模块:1) 文本编码器:将文本歌词转换为向量表示。2) 运动编码器:使用矢量量化变分自编码器(VQ-VAE)将3D全身运动序列编码为离散的运动token。3) 音频编码器:使用语音到单元模型将歌声编码为量化的音频token,保留内容、韵律信息和歌手身份。4) 多模态Transformer:将文本、运动和音频的token作为输入,进行联合建模,生成新的运动和音频token。5) 运动解码器:将生成的运动token解码为3D全身运动序列。6) 音频解码器:将生成的音频token解码为歌声。
关键创新:该论文的关键创新在于提出了一个统一的多模态Transformer框架,可以同时生成连贯的歌声和全身动作。此外,该论文还构建了一个新的大型数据集RapVerse,包含同步的说唱声音、歌词和高质量的3D全身网格。
关键设计:在运动编码器中,使用VQ-VAE将连续的运动序列离散化为token,这有助于降低模型的复杂度,并提高生成结果的多样性。在音频编码器中,使用语音到单元模型,可以保留歌声的内容、韵律信息和歌手身份,从而生成更逼真的歌声。多模态Transformer采用自回归的方式进行训练,可以更好地捕捉不同模态之间的依赖关系。
🖼️ 关键图片

📊 实验亮点
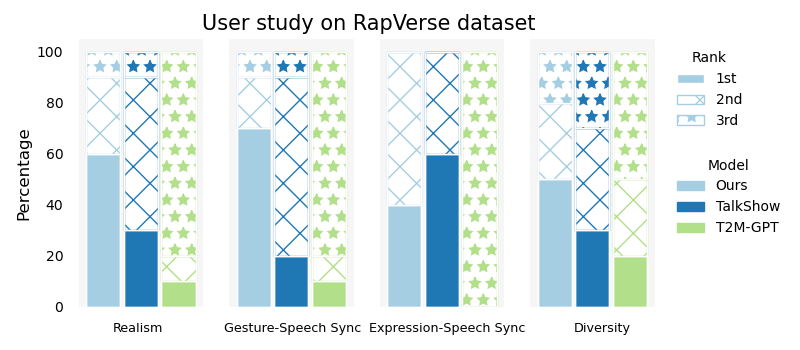
实验结果表明,RapVerse框架不仅能够生成连贯逼真的歌声和全身动作,而且在联合生成任务上表现出色,甚至可以与专门的单模态生成系统相媲美。这证明了该框架的有效性和优越性。RapVerse数据集的发布也为相关研究提供了宝贵的数据资源。
🎯 应用场景
该研究成果可应用于虚拟演唱会、游戏角色动画、虚拟社交等领域。通过输入歌词,即可自动生成逼真的歌声和舞蹈动作,极大地降低了内容创作的成本,并提升了用户体验。未来,该技术有望应用于更广泛的人机交互场景,例如虚拟助手、教育娱乐等。
📄 摘要(原文)
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs, but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation.