$\textit{S}^3$Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
作者: Nan Huang, Xiaobao Wei, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, Shanghang Zhang
分类: cs.CV, cs.AI
发布日期: 2024-05-30
备注: Code is available at: https://github.com/nnanhuang/S3Gaussian/
🔗 代码/项目: GITHUB
💡 一句话要点
提出自监督街景高斯方法,无需3D标注实现自动驾驶场景的动态静态元素分解。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 自监督学习 街景重建 动态场景分解 自动驾驶 时空建模 神经渲染
📋 核心要点
- 现有街景3DGS方法依赖3D车辆标注分解动态静态元素,限制了其在真实无标注场景的应用。
- $ extit{S}^3$Gaussian利用4D一致性进行自监督学习,分解场景中的动态和静态元素,无需3D标注。
- 在Waymo-Open数据集上的实验表明,$ extit{S}^3$Gaussian能够有效分解场景,并在无3D标注下取得最佳性能。
📝 摘要(中文)
本文提出了一种自监督街景高斯方法($ extit{S}^3$Gaussian),用于在自动驾驶场景中进行逼真的3D重建。尽管神经辐射场(NeRF)在驾驶场景中表现出色,但3D高斯溅射(3DGS)因其更快的速度和更显式的表示而成为一个有前景的方向。然而,现有的大多数街景3DGS方法需要跟踪的3D车辆边界框来分解静态和动态元素以进行有效的重建,这限制了它们在实际场景中的应用。为了在没有昂贵标注的情况下促进高效的3D场景重建,我们提出了一种自监督街景高斯($ extit{S}^3$Gaussian)方法,通过4D一致性来分解动态和静态元素。我们用3D高斯表示每个场景,以保持显式性,并进一步用时空场网络来紧凑地建模4D动态。我们在具有挑战性的Waymo-Open数据集上进行了广泛的实验,以评估我们方法的有效性。我们的$ extit{S}^3$Gaussian展示了分解静态和动态场景的能力,并在不使用3D标注的情况下实现了最佳性能。
🔬 方法详解
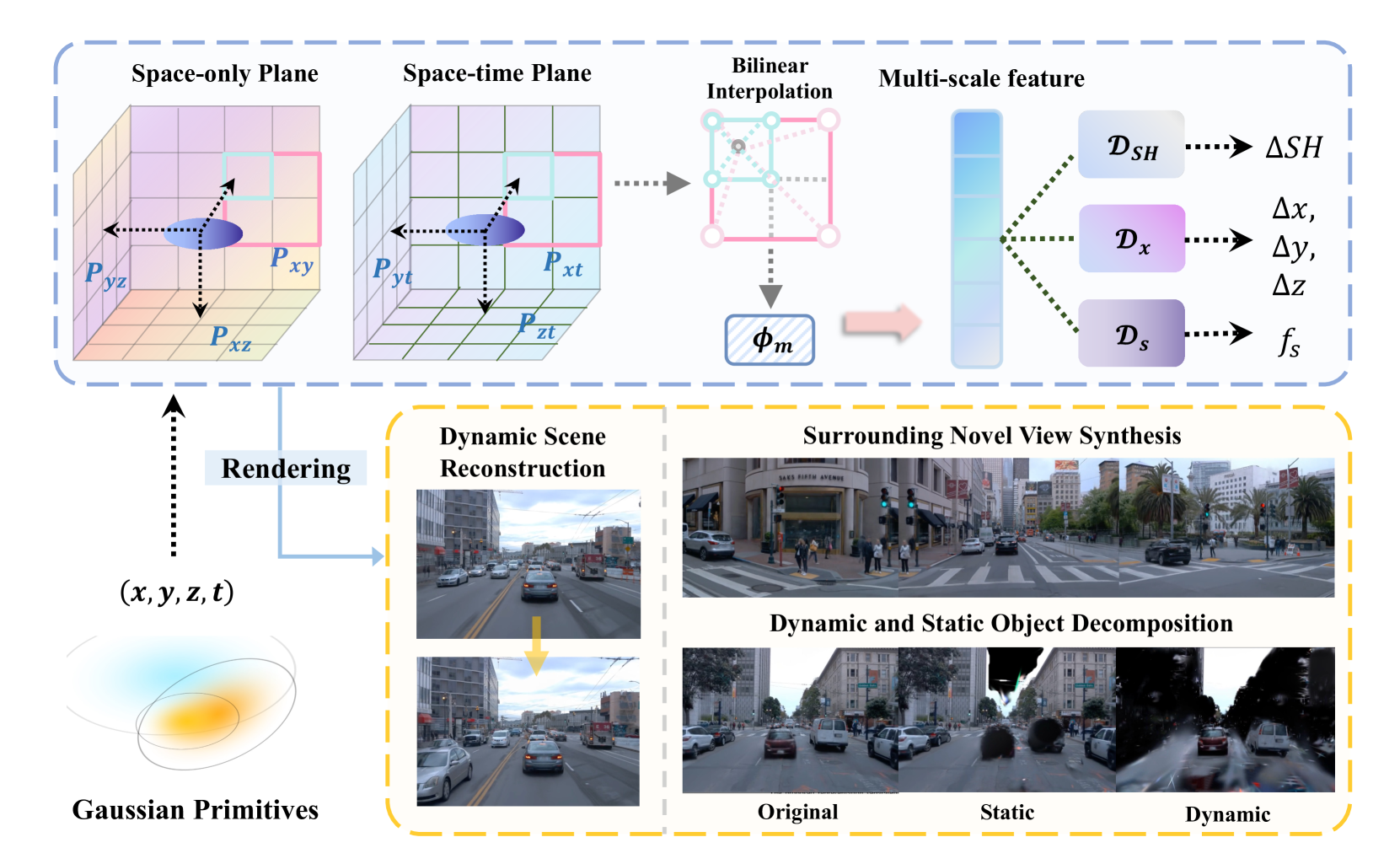
问题定义:现有街景场景的3D重建方法,特别是基于3D高斯溅射(3DGS)的方法,通常依赖于精确的3D车辆边界框标注来区分和处理场景中的动态和静态元素。这种依赖性限制了这些方法在实际应用中的可行性,因为获取大规模、精确的3D标注成本高昂且耗时。因此,如何在没有3D标注的情况下,有效地分解和重建动态变化的街景场景是一个关键问题。
核心思路:本文的核心思路是利用场景的4D一致性(即空间和时间维度上的一致性)进行自监督学习,从而在没有3D标注的情况下,将场景中的动态和静态元素分离。通过对场景进行3D高斯表示,并结合时空场网络来建模动态变化,可以有效地捕捉场景的时空信息,并实现动态和静态元素的分离。
技术框架:$ extit{S}^3$Gaussian方法主要包含以下几个关键模块:1) 3D高斯表示:使用3D高斯分布来表示场景中的每个点,保留了3DGS的显式特性。2) 时空场网络:引入一个紧凑的时空场网络,用于建模场景的4D动态变化。该网络接收3D高斯的位置和时间作为输入,输出该位置在特定时间的密度和颜色。3) 自监督损失函数:设计了一系列自监督损失函数,包括光度一致性损失、深度一致性损失和运动平滑损失,用于约束3D高斯和时空场网络的学习,从而实现动态和静态元素的分离。
关键创新:该方法最重要的创新点在于提出了一个完全自监督的框架,无需任何3D标注即可实现街景场景中动态和静态元素的分离。与现有方法相比,该方法摆脱了对昂贵3D标注的依赖,使其更具实用性和可扩展性。此外,结合3D高斯表示和时空场网络,能够有效地捕捉场景的时空信息,并实现高质量的3D重建。
关键设计:在时空场网络的设计上,作者采用了MLP结构,输入为3D高斯的位置和时间,输出为密度和颜色。损失函数方面,光度一致性损失用于约束渲染图像与原始图像的一致性,深度一致性损失用于约束渲染深度图与估计深度图的一致性,运动平滑损失用于约束相邻帧之间动态元素的运动平滑性。这些损失函数共同作用,使得网络能够学习到场景的动态信息,并实现动态和静态元素的分离。
🖼️ 关键图片


📊 实验亮点
$ extit{S}^3$Gaussian在Waymo-Open数据集上进行了评估,实验结果表明,该方法在没有使用3D标注的情况下,实现了最佳的场景分解和重建性能。具体而言,该方法在静态场景重建的PSNR、SSIM和LPIPS等指标上均优于现有方法,证明了其有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于自动驾驶仿真、增强现实、机器人导航等领域。通过高效重建真实街景,可以为自动驾驶算法提供更逼真的训练环境,加速算法的开发和验证。此外,该技术还可用于创建沉浸式AR/VR体验,以及为机器人提供更准确的环境感知能力。
📄 摘要(原文)
Photorealistic 3D reconstruction of street scenes is a critical technique for developing real-world simulators for autonomous driving. Despite the efficacy of Neural Radiance Fields (NeRF) for driving scenes, 3D Gaussian Splatting (3DGS) emerges as a promising direction due to its faster speed and more explicit representation. However, most existing street 3DGS methods require tracked 3D vehicle bounding boxes to decompose the static and dynamic elements for effective reconstruction, limiting their applications for in-the-wild scenarios. To facilitate efficient 3D scene reconstruction without costly annotations, we propose a self-supervised street Gaussian ($\textit{S}^3$Gaussian) method to decompose dynamic and static elements from 4D consistency. We represent each scene with 3D Gaussians to preserve the explicitness and further accompany them with a spatial-temporal field network to compactly model the 4D dynamics. We conduct extensive experiments on the challenging Waymo-Open dataset to evaluate the effectiveness of our method. Our $\textit{S}^3$Gaussian demonstrates the ability to decompose static and dynamic scenes and achieves the best performance without using 3D annotations. Code is available at: https://github.com/nnanhuang/S3Gaussian/.