Can't make an Omelette without Breaking some Eggs: Plausible Action Anticipation using Large Video-Language Models
作者: Himangi Mittal, Nakul Agarwal, Shao-Yuan Lo, Kwonjoon Lee
分类: cs.CV
发布日期: 2024-05-30
备注: CVPR 2024
💡 一句话要点
提出PlausiVL,利用视频-语言大模型进行符合现实的动作序列预测。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频语言模型 动作预测 反事实学习 长时程建模 合理性推理 视频理解 Ego4D EPIC-Kitchens-100
📋 核心要点
- 现有动作预测方法忽略了动作序列在现实世界中的合理性,导致预测结果可能不符合常理。
- 利用视频-语言大模型的生成能力,并设计了基于反事实学习和长时程重复惩罚的损失函数,提升模型对动作合理性的理解。
- 在Ego4D和EPIC-Kitchens-100数据集上的实验表明,该方法在动作预测任务上取得了性能提升。
📝 摘要(中文)
本文提出PlausiVL,一个用于预测现实世界中符合常理的动作序列的视频-语言大模型。虽然在预测未来动作方面已经取得了显著进展,但现有方法没有考虑到动作序列的合理性。为了解决这个局限性,本文探索了大型视频-语言模型的生成能力,并通过引入两个目标函数来发展对动作序列合理性的理解:基于反事实的合理动作序列学习损失和长时程动作重复损失。利用时间逻辑约束以及动词-名词动作对逻辑约束来创建不合理/反事实的动作序列,并使用它们来训练模型,配合合理动作序列学习损失。该损失有助于模型区分合理和不合理的动作序列,并帮助模型学习对动作预测至关重要的隐式时间线索。长时程动作重复损失对在较长时间窗口内更易重复的动作施加更高的惩罚。通过这种惩罚,模型能够生成多样化的、合理的动作序列。在Ego4D和EPIC-Kitchens-100两个大规模数据集上评估了该方法,并在动作预测任务上显示出改进。
🔬 方法详解
问题定义:现有动作预测方法主要关注预测的准确性,而忽略了预测的动作序列在现实世界中是否合理。例如,预测一个人在做饭时先吃掉鸡蛋再打碎鸡蛋,这在逻辑上是不合理的。因此,需要一种方法来确保预测的动作序列是符合常理的。
核心思路:论文的核心思路是利用大型视频-语言模型的生成能力,并结合反事实学习和长时程重复惩罚,使模型能够区分合理和不合理的动作序列。通过让模型学习哪些动作序列是不合理的,从而提高其预测合理动作序列的能力。同时,通过惩罚长时间内重复的动作,鼓励模型生成更多样化的动作序列。
技术框架:PlausiVL模型的整体框架基于一个大型视频-语言模型。训练过程包括以下几个关键步骤:1) 利用时间逻辑约束和动词-名词动作对逻辑约束生成不合理/反事实的动作序列;2) 使用合理动作序列学习损失(基于反事实)训练模型,使模型能够区分合理和不合理的动作序列;3) 使用长时程动作重复损失,对长时间内重复的动作进行惩罚,鼓励模型生成多样化的动作序列。
关键创新:论文的关键创新在于提出了两种新的损失函数:基于反事实的合理动作序列学习损失和长时程动作重复损失。基于反事实的损失函数通过学习区分合理和不合理的动作序列,提高了模型对动作合理性的理解。长时程动作重复损失通过惩罚重复动作,鼓励模型生成更多样化的动作序列。与现有方法相比,该方法更注重预测动作序列的合理性,而不仅仅是准确性。
关键设计:基于反事实的合理动作序列学习损失的设计关键在于如何生成有效的反事实动作序列。论文利用时间逻辑约束(例如,动作A必须在动作B之前发生)和动词-名词动作对逻辑约束(例如,“吃掉鸡蛋”必须在“打碎鸡蛋”之后)来生成反事实动作序列。长时程动作重复损失的设计关键在于如何定义“重复”。论文使用一个时间窗口来衡量动作的重复程度,并在损失函数中对重复的动作施加更高的惩罚。具体的参数设置和网络结构细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


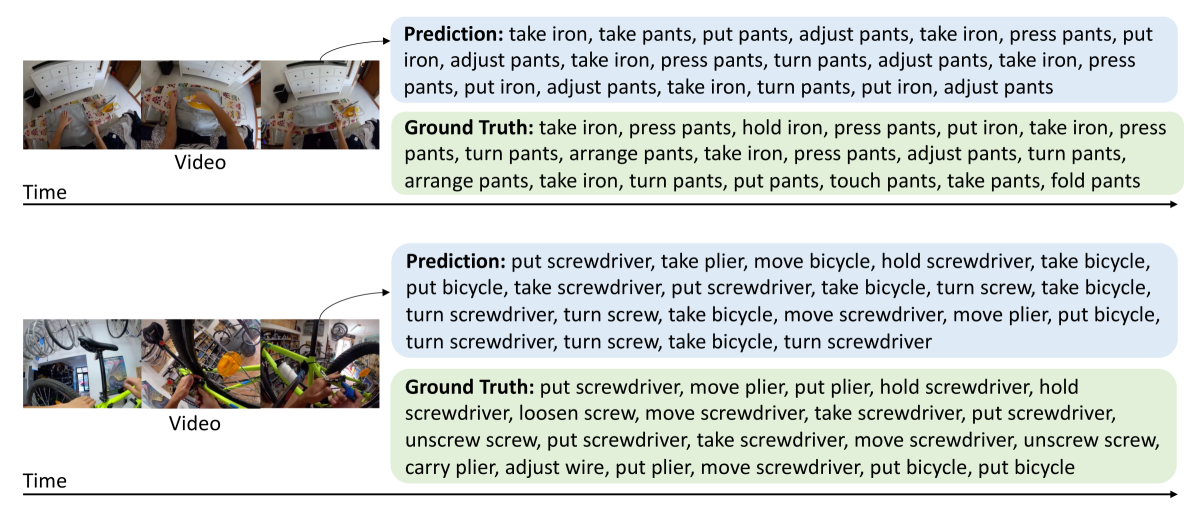
📊 实验亮点
该方法在Ego4D和EPIC-Kitchens-100两个大规模数据集上进行了评估,并在动作预测任务上取得了显著的改进。具体的性能数据和提升幅度在摘要中没有给出,属于未知信息。实验结果表明,该方法能够有效地提高模型对动作序列合理性的理解,并生成更符合现实的动作序列。
🎯 应用场景
该研究成果可应用于机器人辅助、智能家居、自动驾驶等领域。例如,在机器人辅助烹饪中,可以利用该模型预测用户接下来可能执行的动作,并提前做好准备,提高效率和安全性。在自动驾驶中,可以预测行人和车辆的未来行为,从而做出更合理的决策,避免交通事故。该研究有助于提升人工智能系统在复杂环境中的理解和决策能力。
📄 摘要(原文)
We introduce PlausiVL, a large video-language model for anticipating action sequences that are plausible in the real-world. While significant efforts have been made towards anticipating future actions, prior approaches do not take into account the aspect of plausibility in an action sequence. To address this limitation, we explore the generative capability of a large video-language model in our work and further, develop the understanding of plausibility in an action sequence by introducing two objective functions, a counterfactual-based plausible action sequence learning loss and a long-horizon action repetition loss. We utilize temporal logical constraints as well as verb-noun action pair logical constraints to create implausible/counterfactual action sequences and use them to train the model with plausible action sequence learning loss. This loss helps the model to differentiate between plausible and not plausible action sequences and also helps the model to learn implicit temporal cues crucial for the task of action anticipation. The long-horizon action repetition loss puts a higher penalty on the actions that are more prone to repetition over a longer temporal window. With this penalization, the model is able to generate diverse, plausible action sequences. We evaluate our approach on two large-scale datasets, Ego4D and EPIC-Kitchens-100, and show improvements on the task of action anticipation.