OpenDAS: Open-Vocabulary Domain Adaptation for 2D and 3D Segmentation
作者: Gonca Yilmaz, Songyou Peng, Marc Pollefeys, Francis Engelmann, Hermann Blum
分类: cs.CV
发布日期: 2024-05-30 (更新: 2024-10-29)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出OpenDAS,通过开放词汇域自适应提升2D/3D分割性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇分割 域自适应 视觉语言模型 提示调优 三元组损失
📋 核心要点
- 现有开放词汇分割(OVS)方法在基础类上的性能不如全监督方法,原因是缺乏像素对齐的训练掩码和领域知识。
- OpenDAS通过参数高效的提示调优和三元组损失训练策略,将领域知识注入VLM,同时保留其开放词汇特性。
- 实验表明,OpenDAS在2D和3D分割任务中,显著提升了基础类和新类的分割性能,且易于集成到现有OVS流程中。
📝 摘要(中文)
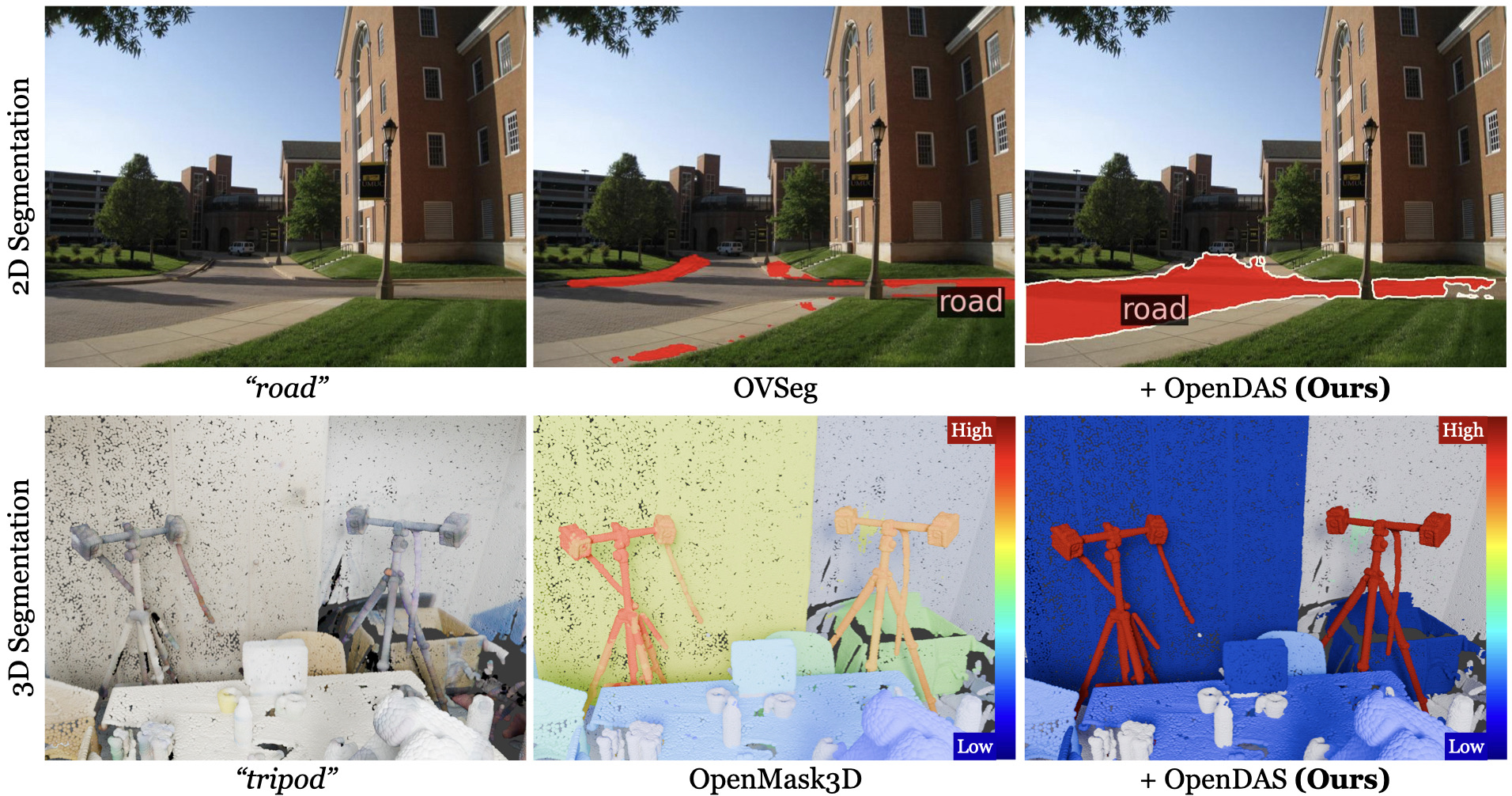
本文提出开放词汇域自适应(OpenDAS)任务,旨在将领域特定知识融入视觉-语言模型(VLM),同时保留其开放词汇的特性,从而提升基础类和新类的分割性能。现有VLM自适应方法虽然能提升基础查询的性能,但未能完全保留VLM在新查询上的开放集能力。为了解决这个问题,本文结合了参数高效的提示调优和基于三元组损失的训练策略,该策略使用辅助负查询。实验结果表明,该方法是唯一一种在参数高效的前提下,始终超越原始VLM在新类上的性能的方法。所提出的自适应VLM可以无缝集成到现有的OVS流程中,例如,在ADE20K上将OVSeg的mIoU提高+6.0%,在ScanNet++ Offices上将OpenMask3D的AP提高+4.1%,而无需其他更改。
🔬 方法详解
问题定义:论文旨在解决开放词汇分割(OVS)模型在特定领域应用时,由于缺乏领域知识和像素对齐的训练数据,导致在基础类别上的性能不如传统全监督方法的问题。现有VLM自适应方法虽然能提升基础类别的性能,但往往会牺牲模型在新类别上的泛化能力。
核心思路:论文的核心思路是将领域特定知识融入到预训练的视觉-语言模型(VLM)中,同时保持其开放词汇的特性。通过域自适应的方式,让模型能够更好地理解和分割特定领域的图像,并且能够处理训练时未见过的类别。
技术框架:OpenDAS方法主要包含两个关键模块:参数高效的提示调优和基于三元组损失的训练策略。首先,利用提示调优方法,通过少量可学习的参数来调整VLM,使其适应目标领域的数据。然后,使用三元组损失函数,结合辅助负查询,来训练模型,从而提高模型在新类别上的泛化能力。整体流程是将预训练的VLM,通过OpenDAS方法进行自适应,然后将其集成到现有的OVS流程中。
关键创新:论文的关键创新在于提出了一种参数高效且能有效保留VLM开放词汇特性的域自适应方法。该方法通过结合提示调优和三元组损失,实现了在提升基础类别性能的同时,保持甚至提升模型在新类别上的分割能力。与现有方法相比,OpenDAS是唯一一种在参数高效的前提下,始终超越原始VLM在新类上的性能的方法。
关键设计:在提示调优方面,论文采用了少量可学习的参数,以避免过拟合。在三元组损失函数方面,论文使用了辅助负查询,以增强模型对不同类别的区分能力。具体来说,三元组损失的目标是拉近正样本对(图像和对应的文本描述)的距离,同时推开负样本对(图像和不对应的文本描述)的距离。辅助负查询是指在训练过程中,除了使用标准的负样本外,还额外引入一些与目标类别相似但不同的类别作为负样本,从而提高模型的鲁棒性。
🖼️ 关键图片


📊 实验亮点
OpenDAS在ADE20K和ScanNet++数据集上取得了显著的性能提升。在ADE20K数据集上,OpenDAS将OVSeg的mIoU提高了+6.0%。在ScanNet++ Offices数据集上,OpenDAS将OpenMask3D的AP提高了+4.1%。这些结果表明,OpenDAS能够有效地将领域知识融入到VLM中,从而提高分割性能。
🎯 应用场景
OpenDAS具有广泛的应用前景,例如自动驾驶、机器人导航、医学图像分析等领域。通过将领域知识注入到VLM中,可以提高这些应用场景中图像分割的准确性和可靠性。此外,OpenDAS的开放词汇特性使得模型能够处理各种未知的物体类别,从而提高了模型的适应性和实用性。未来,OpenDAS有望成为各种视觉任务中的重要组成部分。
📄 摘要(原文)
Recently, Vision-Language Models (VLMs) have advanced segmentation techniques by shifting from the traditional segmentation of a closed-set of predefined object classes to open-vocabulary segmentation (OVS), allowing users to segment novel classes and concepts unseen during training of the segmentation model. However, this flexibility comes with a trade-off: fully-supervised closed-set methods still outperform OVS methods on base classes, that is on classes on which they have been explicitly trained. This is due to the lack of pixel-aligned training masks for VLMs (which are trained on image-caption pairs), and the absence of domain-specific knowledge, such as autonomous driving. Therefore, we propose the task of open-vocabulary domain adaptation to infuse domain-specific knowledge into VLMs while preserving their open-vocabulary nature. By doing so, we achieve improved performance in base and novel classes. Existing VLM adaptation methods improve performance on base (training) queries, but fail to fully preserve the open-set capabilities of VLMs on novel queries. To address this shortcoming, we combine parameter-efficient prompt tuning with a triplet-loss-based training strategy that uses auxiliary negative queries. Notably, our approach is the only parameter-efficient method that consistently surpasses the original VLM on novel classes. Our adapted VLMs can seamlessly be integrated into existing OVS pipelines, e.g., improving OVSeg by +6.0% mIoU on ADE20K for open-vocabulary 2D segmentation, and OpenMask3D by +4.1% AP on ScanNet++ Offices for open-vocabulary 3D instance segmentation without other changes. The project page is available at https://open-das.github.io/.